해당 Fold 데이터를 평가 데이터로 사용해서 모델 검증 해당 Fold를 제외한 나머지 데이터를 훈련 데이터로 사용해서 모델 학습
K개의 Fold에 대해서 위의 과정을 반복 = K번의 모델 학습 + 성능 측정 수행
모든 Fold를 처리한 후 K개의 성능 결과에 대해 평균을 구하고 이를 모델의 전체 성능으로 간주
4. 표준화 (Normalization)
: 머신러닝 모델이 학습하기 위해서는 입력으로 받는 데이터가 전부 수치화 되어야 하는데, 이 과정에서 특정 컬럼값의 범위가 너무 커서 특정 방향으로 편향되지 않도록 보정해주는 과정
훈련 데이터셋에 존재하는 feature들의 값을 특정 범위로 제약을 주어 모델의 성능이 훈련 데이터셋에 따라 달라지는 것을 방지
보통 모든 feature들의 값을 동일한 범위에 들어가도록 하는 전처리 기법
예) 최대/최소값이 각각 1과 -1이 되도록 표준화
예) 최대/최소값이 각각 1과 0이 되도록 표준화
딥러닝에서는 “Batch Normalization”이라는 것이 존재
5. 비용 함수(Cost Function, Loss Function)
: 모델의 예측 정확도를 측정하기 위해 사용되는 함수로, 함수값이 최소일 때의 모델이 최적의 모델이 된다.
종류 :
Absolute loss (Least Absolute Deviation, L1 norm)
Square loss (Least Square Error, L2 norm)
Hinge loss
Logistic loss
Cross entropy loss
RMSE (Root Mean Squared Error)
Logarithmic loss (RMSLE, Root Mean Squared Logarithmic Error)
6. 정규화 (Regularization)
: 손실 함수에 추가 정보(or 패널티)를 부여하여 과적합을 방지하기 위한 기술
(일부 feature의 가중치를 0 혹은 아주 작게 만든다.)
정규화 없는 기본 ML 방식 : Linear Regression
1) L1 정규화
일부 덜 중요한 피처의 가중치를 0으로 만든다.
► Linear Regression + L1 정규화 = Lasso Regression
2) L2 정규화
일부 덜 중요한 feature의 가중치를 아주 작게 만든다.
► Linear Regression + L2 정규화 = Ridge Regression
머신 러닝(Machine Learning) 이란?
: 배움이 가능한 기계가 데이터의 패턴을 보고 인간을 모방하는 방식
► 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
머신 러닝 모델 (Machine Learning Model)
: 머신 러닝을 통해서 최종적으로 만드는 결과물
블랙박스 : 내부가 어떤지 모름
선택한 ML 알고리즘에 따라 내부 동작 방식이 다르다.
디버깅이 쉽지 않다.
입력 데이터를 주면 이를 기반으로 예측
모델 학습(training, building)
: 머신러닝 모델을 만드는 과정
머신 러닝 종류
1. 지도 학습(Supervised Machine Learning)
: 훈련데이터 O + 정답(=레이블, 타겟) O
분류(classificaiton) : 정답이 유한한 수의 범주형일때
모델 성과 지표(클수록 good) : accuracy, precision, recall, f1 score
binary classification : 예측 대상이 2개
multi-class classification : 예측 대상이 2개 이상
회귀(regression) : 연속적인 숫자를 예측하는데 사용되는 ML 모델
활용분야 : 주택 가격 예측, 주식 가격 예측
모델 성과 지표(작을수록 good) : RMSE
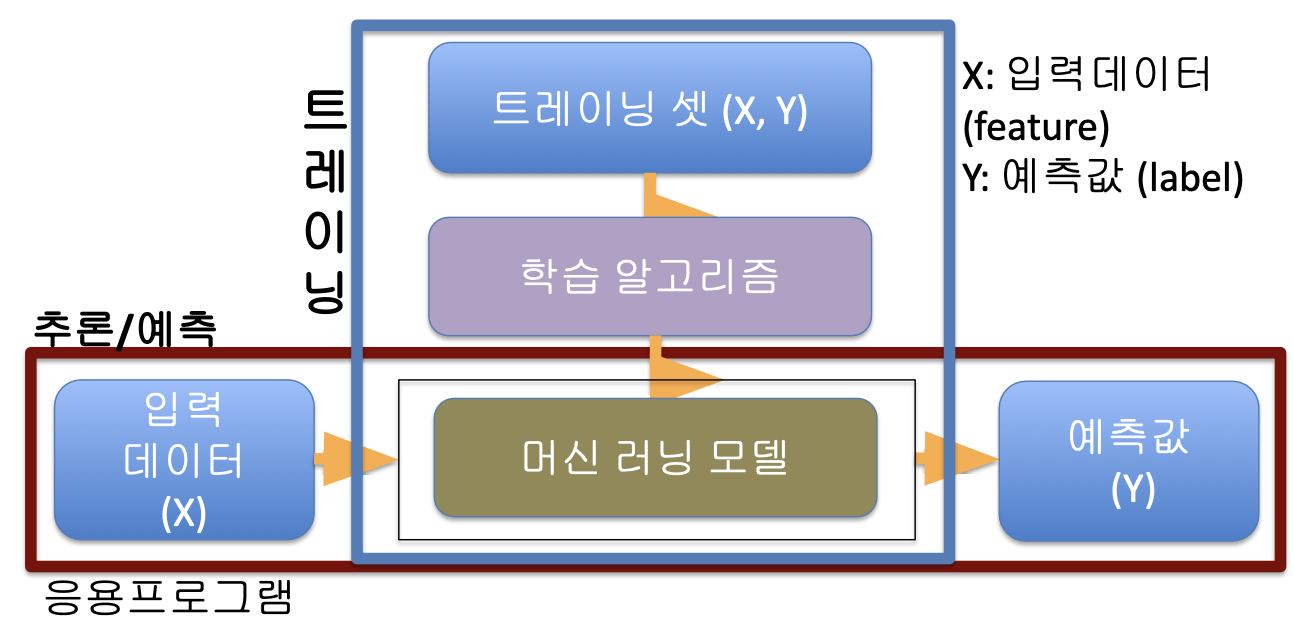
지도 기계 학습
1단계. 모델 훈련 (Training) ← 데이터 과학자가 진행
훈련 데이터 셋 (X, Y)
X : 입력데이터 (feature)
Y : 예측값 (label)
학습 알고리즘
머신러닝 모델
2단계. 추론/예측 (Prediction) : 학습시킨 모델을 사용하는 단계 ← 백엔드 엔지니어, 프론트엔드 엔지니어
응용 프로그램단에서 머신러닝 모델이 필요할 때마다 입력 데이터(X)를 준비해서 API를 호출하면, API안에서 머신러닝 모델에 받은 입력 데이터(X)를 input으로 주고, 머신러닝 모델이 반환해준 값은 예측값이 된다. 이를 응용 프로그램에 돌려주는 방식으로 동작
머신러닝 모델을 API 형태로 배포하는 것은 데이터 엔지니어 또는 백엔드 엔지니어가 관여
이러한 과정을 한번에 할 수 있게 하는 프레임워크 : SageMaker
📌 API(Application Programming Interface) : 프로그램을 작성하기 위해 사용하는 인터페이스 = 특정 업무를 수행하기 위해서 호출하는 기능들
◆ 다양한 종류의 API가 존재 ex) Python 모듈은 각기 제공해주는 기능에 따라 다양한 함수 제공 (이것도 API라 할 수 있음) ◆ 보통 API는 웹 상의 다른 서버에 존재하는 특정 기능을 사용 가능하게 해주는 인터페이스를 지칭 ◆ 머신러닝에서 API는 모델을 통해 예측하는 것을 의미함 📌 Interface(인터페이스) : 무엇인가와 통신을 하기 위한 방법
2. 비지도 학습(Unsupervised Machine Learning)
: 훈련데이터 O + 정답 X → 훈련데이터로부터 패턴을 찾음
군집화(clustering) : 데이터로부터 특성을 찾아서 비슷한것끼리 묶어줌
활용분야 : 뉴스 기사 클러스터링
언어모델(LLM; Large Language Model) : 문장의 일부를 보고 비어있는 단어를 확률적으로 예측하는 모델
예시 : GPT
3. 강화학습 (Reinforcement Learning)
: 훈련데이터 X → 시행착오를 통해 최적의 결정을 학습하는 ML 학습 방법
에이전트 : 머신러닝 모델
환경 : 규칙이 명확하게 있어야 함
에이전트는 환경과 상호작용하며(행동에 대한 보상을 받으며) 시간이 지남에 따라 최대 보상 전략을 학습
예시 : 알파고, 자율주행
모델 추론/예측(사용) 과정
예측 데이터를 실제 훈련에 사용되는 데이터로 전환
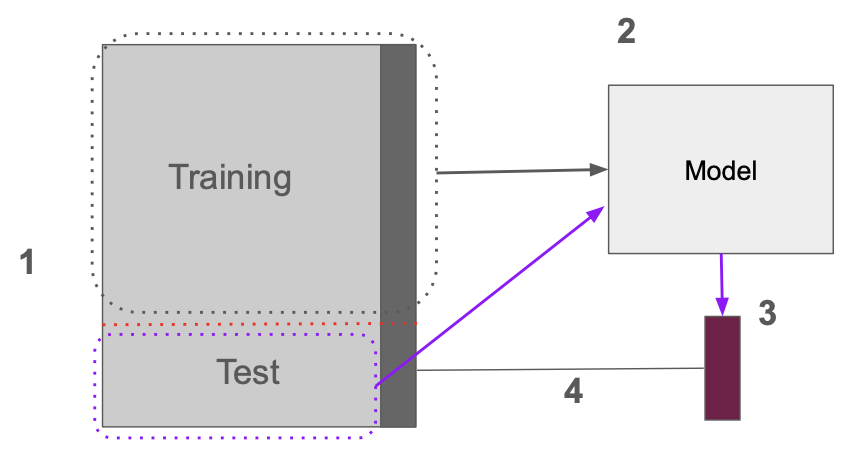
모델 훈련 프로세스
1. Load Data
: 훈련 데이터 불러오기
2. Extract features
: 훈련용 데이터가 있는 그대로 모델 훈련에 사용되는 것이 아니라 숫자가 아닌 값들은 무시되거나 숫자로 변환되고 숫자들은 표준화 (0과 1사이) 등으로 한번 변환됨