
Classification
: 데이터를 다양한 클래스로 분류하는 것
Classification 모델 종류 (문제)
1. 이진 분류 (Binary Classification)
: 2개 클래스로 분류
예) 스팸 vs 일반 이메일
2. 다중 클래스 분류 (Multiclass Classification)
: 3개 이상 클래스로 분류(하나의 데이터가 하나의 클래스에 속함)
예) 손글씨 숫자 인식 (0-9)
3. 다중 레이블 분류 (Multilabel Classification)
: 하나의 데이터가 여러 클래스에 할당될 수 있음
예) 뉴스 기사가 하나가 경제, 사회 등의 여러 카테고리에 속할 수 있음
Classification 알고리즘 종류 (해결 방법)
1. Logistic Regression
- 이진 분류 문제에 자주 사용
- input x가 주어졌을 때 binary class에 소속될 확률이 y가 된다.
- y는 확률이기 때문에 0 ~ 1 사이의 값

2. Decision Tree
- Feature의 중요도와 동작 방식을 파악할 수 있음 → 직관적, 시각화 용이
- Regression으로도 사용 가능

3. Random Forests
4. Support Vector Machines
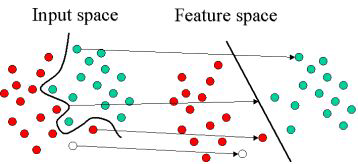
- Feature space를 변환하여 분류를 수행하는 방법
- 원래의 Feature들의 차원에 대해서 Feature의 값을 변환하여 이들을 분류할 수 있는 선을 긋는 것이 목표
- 복잡한 분류 문제에 효과적
5. Deep Learning
- 고급 분류 문제 활용(ex. 이미지 및 음성 인식)
Classification 모델 성능 평가
Confusion Matrix

| (정답여부 예측) | 의미 |
| TP (True Positive) | 양성이라 예측했는데, 실제로도 양성인 것 |
| FP (False Positive) | 양성이라 예측했는데, 실제로는 음성인 것 |
| FN (False Negative) | 음성이라 예측했는데, 실제로는 양성인 것 |
| TN (True Nagetive) | 음성이라 예측했는데, 실제로도 음성인 것 |
- Precision = TP / (TP + FP)
: 양성이라 예측된 것 중 얼마나 실제로도 양성이었는가 - Recall = TP / (TP + FN) = TPR
: 실제로 양성인 것 중 얼마나 양성으로 예측되었는가 - FPR = FP / (FP + TN)
- Accuracy = (TP + TN) / (TP + TN + FP + FN )
ROC curve (Receiver Operating Characteristic)
threshold(임계값)을 0부터 1까지 이동시키면서 Classification model 최적의 정확도를 찾는 곡선
[목표]
- 우리가 만든 Classification 모델이 괜찮은 성능을 보이는가?
- 기준점(threshold)을 어디로 잡아야 최적의 성능을 보이는가?

- x축 : TPR (True Positive Rate) - 양성이라 예측했을 때 실제로도 양성일 확률 ▶ 높을수록 최적
- y축 : FPR (False Positive Rate) - 실제로 음성인 것들을 음성이라 판정하는 확률 ▶ 낮을수록 최적
AUC (Area Under the Curve)
ROC curve의 아래 면적을 계산 한 것으로, AUC 값을 보고 threshold를 결정한다.
0~1 사이의 값을 리턴한다.
- 1 : 모델이 매우 정확함
- 0.5 : 랜덤 추정에 가까움 (ex. 동전 던지기)
- 0 : 데이터에 문제가 있음
classification 리포트 생성
from sklearn.metrics import classification_report
classificationReport = classification_report(expected, predicted)
모델 학습의 큰 흐름(Hold Out을 사용한다고 가정)
- 내가 풀고자 하는 문제 정의하기
- 머신러닝 알고리즘과 성과 지표 결정
- 데이터셋 불러오기
- 데이터셋을 훈련 데이터와 평가 데이터(+ 검증데이터)로 분리
- 훈련 데이터 전처리(Feature Engineering)
- 훈련 데이터로 모델 학습(빌딩)
- 평가 데이터 전처리(훈련 데이터와 동일한 방식 적용)
- 레이블(정답) 정보를 제외시킨 평가 데이터를 모델에 입력(input)으로 지정
- 위 결과물과 정답 레이블을 비교하여 성과 계산
피쳐(Feature) 추출 및 변환
: 입력으로 주어진 훈련 데이터(피쳐 값들)를 모델 훈련에 적합한 형태로 바꾸는 것
1. Feature Extraction
: 기존 필드에서 새로운 필드를 만들어 내는 것
- Loading features from dicts
- Feature hashing
- Text feature extraction
- Image feature extraction
2. Preprocessing data (범주형 → 수치형 변환)
Encoder 사용 방법
방법 1.
from sklearn.preprocessing import 인코더이름
X = [['seoul'], ['tokyo'], ['beijing']] # 예제 데이터
enc = 인코더이름()
enc.fit(X)
X_enc = enc.transform(X)▶ 훈련 데이터와 평가 데이터의 전처리 일관성 유지 측면에서 방법 1이 더 좋다.
방법 2.
from sklearn.preprocessing import 인코더이름
X = [['seoul'], ['tokyo'], ['beijing']] # 예제 데이터
X_enc = 인코더이름().fit_transfomr(X)
1. Ordinal Encoding
- 각각의 클래스에 맞게 일련번호를 부여하는 방식으로 인코딩
- 카테고리 값들 간에 좋고/나쁨의 순서가 있을 경우 사용
- `sklearn.preprocessing` 모듈 내 `OrdinalEncoder` 사용
## 1. Ordinal Encoding
from sklearn.preprocessing import OrdinalEncoder
X = [['seoul'], ['tokyo'], ['beijing']]
enc = OrdinalEncoder()
enc.fit(X)
enc.transform(X)
2. One-hot Encoding
- 카테고리 값을 벡터 형태로 인코딩
- 카테고리 값들 간에 좋고/나쁨의 순서가 없고 서로 독립적일 경우 사용
- `sklearn.preprocessing` 모듈 내 `OneHotEncoder` 사용
## 2. One-Hot Encoding
from sklearn.preprocessing import OneHotEncoder
X = [['seoul'], ['tokyo'], ['beijing']]
enc = OneHotEncoder()
enc.fit(X)
enc.transform(X)
3. Label Encoding
- 레이블 필드를 인코딩하는 경우
- `sklearn.preprocessing` 모듈 내 `LabelEncoder` 사용
## 2. One-Hot Encoding
from sklearn.preprocessing import LabelEncoder
y = ['recurrence-events', 'no-recurrence-events', 'recurrence-events']
enc = LabelEncoder()
enc.fit(y)
y_labeled = enc.transform(y)
print(y_labeled)
3. Feature Scaling (Normalization; 정규화)
: 숫자 필드 값의 범위를 특정 범위(ex. 0부터 1 사이)로 표준화하는 것
스케일러 종류
1. StandardScaler
각 값에서 평균을 빼고 이를 표준편차로 나눔
값의 분포가 정규분포를 따르도록 변환
`sklearn.preprocessing` 모듈 내 `StandardScaler` 사용
from sklearn.preprocessing import StandardScaler
import numpy as np
X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]])
## 아래와 동일한 코드 : X_scaled= StandardScaler().fit_transform(X_train)
scaler = StandardScaler().fit(X_train)
X_scaled = scaler.transform(X_train)
2. MinMaxScaler
각 값에서 최솟값을 빼고 (최댓값 - 최솟값)으로 나누어서 모든 값을 0과 1 사이로 변환
`sklearn.preprocessing` 모듈 내 `MinMaxScaler` 사용
`MinMaxScaler()` 괄호 안에 별도로 최댓값, 최솟값을 부여하지 않으면 1과 0이 디폴트 값임
3. RobustScaler
`sklearn.preprocessing` 모듈 내 `RobustScaler` 사용
4. MaxAbsScaler
`sklearn.preprocessing` 모듈 내 `MaxAbsScaler` 사용
4. Imputation of missing values
: 결측치가 존재하는 컬럼의 경우 기본값을 정해서 채우는 것(= Impute 한다.)
Imputer 종류
1. SimplerImputer
- 간단한 통계(ex. 평균, 중앙값, 최다 빈도, 상수 등)를 지정하여 결측치를 대체하는 방식
- `sklearn.impute` 모듈 내 `SimpleImputer` 사용
import numpy as np
from sklearn.impute import SimpleImputer
# Example dataset with missing values
data = np.array([[1, np.nan, 3],
[4, 3, np.nan],
[np.nan, 6, 9],
[8, 5, 2]])
imputer = SimpleImputer(missing_values=np.nan, strategy='mean') # np.nan을 찾아서 평균값으로 대체
imputed_data = imputer.fit_transform(data)
print(imputed_data)
2. IterativeImputer
- (데이터가 충분히 있다고 가정할 때) 결측치가 있는 피처를 유사한 다른 피처들의 함수로 지정하는 방
- `sklearn.impute` 모듈 내 `IterativeImputer` 사용
- 아직은 시범 사용중
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
data = np.array([[1, np.nan, 3],
[4, 3, np.nan],
[np.nan, 6, 9],
[8, 5, 2]])
# 10번의 반복을 돌면서 비슷한 레코드를 점진적으로 찾아서 그 레코드에 해당되는 필드 값을 대체값으로 사용
iterative_imputer = IterativeImputer(max_iter=10, random_state=0)
imputed_data = iterative_imputer.fit_transform(data)
print(imputed_data)
5. Unsupervised dimensionality reduction
: 차원 축소(비지도 학습에서는 매우 중요)
6. Transforming the prediction target(y)
: 타겟 값 변환
파이프라인 (pipeline)
: 입력 데이터에 적용되는 operation들(데이터 전처리, 모델 빌딩)을 순서대로 적용할 수 있는 것
`make_pipline(전처리 메소드, 모델)`
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
X, y = make_classification(random_state=42) # 사이킷 런 내 작은 샘플 데이터
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
pipe = make_pipeline(StandardScaler(), LogisticRegression())
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)
Kaggle 타이타닉 데이터로 Classification 실습
실습 데이터
실습 링크 : https://www.kaggle.com/c/titanic
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
총 892개 레코드(행), 12개 컬럼(피쳐 + 레이블 필드)
PassengerId, Fare, Ticket 컬럼은 분석에 사용하지 않을 예정
| 컬럼명 | 의미 | 클래스 |
| PassengerId | 승객 일련번호 | |
| Survived (레이블) | 생존 여부 | - 0 : 사망 - 1 : 생존 |
| Pclass | 좌석 등급 | - 1 : 1등급 - 2 : 2등급 - 3 : 3등급 |
| Name | 승객 이름 | |
| Sex | 승객 성별 | |
| Age | 승객 나이 | |
| SibSp | 동승한 형제/자매/배우자 수 | |
| Parch | 동승한 부모/자녀 수 | |
| Ticket | 티켓 번호 | |
| Fare | 운임료 | |
| Cabin | 숙소 번호 | |
| Embarked | 승선한 항구 | - C : Cherboug - Q : Queenstown - S : Southampton |
1단계. 훈련 데이터셋 불러오기
import pandas as pd
import numpy as np
train = pd.read_csv("https://s3-geospatial.s3-us-west-2.amazonaws.com/train.csv")
train.shape