
딥러닝
: 사람의 신경망을 기반으로 학습과 추론을 진행하는 학문
인간과 딥러닝
<인간>
뉴런(Neuron)
: 사람 신경 구조의 기본 단위 ► 뉴런이 모여 신경계가 이루어짐
시냅스(Synapse)
: 정보가 전달되는 연결통로로, 뉴런과 뉴런을 이어줌
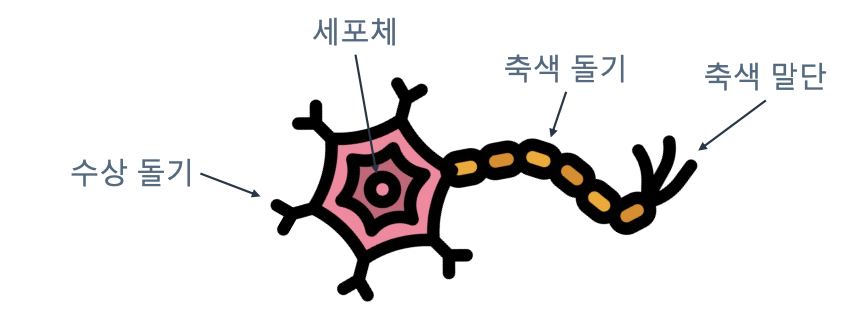
- 수상돌기 : 앞선 뉴런의 신호를 수신
- 세포체 : 신호 연산
- 축색돌기 : 신호 이동
- 출색말단 : 후발 뉴런에게 신호 전달

<딥러닝>
퍼셉트론(Perceptron; ●)
: 뉴런을 모방하기 위해 수학적으로 모델링한 딥러닝의 기본 단위 ► 퍼셉트론이 쌓아져 딥러닝 모델이 만들어짐
※ 퍼셉트론을 어떤식으로 구성하느냐에 따라 받을 수 있는 입력 데이터와 풀 수 있는 문제가 달라진다.
가중치(Weight; →)
: 두 퍼셉트론 사이의 연관관계도

이미지 데이터 처리
문제
- 이미지 분류 : 이미지의 대부분을 차지하는 객체의 종류를 예측하는 문제
- 객체 인식
- 객체 분할
- 자세 분석
대표적 딥러닝 모델 : CNN
: 사람이 보는 과정을 모듈(module)의 형태로 만들어 낸 이미지 분석을 위한 개념단위
| 사람이 보는 과정 | 이미지 처리 과정 |
| 1. 분석 단위를 설정 후 정보를 추출 | 1. Convolutional Filter (정보 처리) |
| 2. 주변정보를 통합해 차츰차츰 상위 개념을 구성 | 2. Pooling (의미 추출) |
| 3. 목적하는 상위 개념에 도달할 때 까지 반복 | 3. 반복 (정보처리 + 의미추출) |
📌 Convolutional Filter : 이미지 위에서 작동하는 정보 처리기
이미지 분류 실습
문제 정의
입력으로 하나의 이미지를 제공하고 해당 이미지의 종류(=클래스)를 예측하는 것
- 일반적으로 선택 가능한 모든 클래스에 대한 정답 점수값을 예측
► 최종결과는 그 점수 중 가장 큰 값을 선택하면서 얻을 수 있음 - 이 점수들을 활용해 확률값을 취할 수 있음
사용할 이미지 분류 모델 : ResNet
2015년 제안되었으며, 당시 사람의 이미지 인식 능력을 넘어선 최초의 이미지 인식 모델
- Layer(=모델의 깊이)에 따라 18, 34, 50, 101, 152 이라는 5가지 종류가 존재
- 깊이가 얕을수록 성능이 낮지만 빠르게 결과를 얻을 수 있음
- 깊이가 깊을수록 성능이 높아지지만 결과를 도출하기 위한 시간이 오래 걸림
- 딥러닝 모델을 학습하는 시간은 이전 머신러닝 모델 대비 상당히 오래 걸림
- 따라서 Pytorch(딥러닝 프레임워크) 내부에서 이미 학습 된 모델을 가져다가 활용할 예정
- 따라서 Pytorch(딥러닝 프레임워크) 내부에서 이미 학습 된 모델을 가져다가 활용할 예정
📌 자주 사용하는 프레임워크
머신러닝 : scikit-learn
딥러닝 : tensorflow, pytorch
GPU 연결
딥러닝 모델은 보통 모델의 크기가 크기 때문에(실습 모델은 152) 코드 실행 전에 항상 GPU에 연결하는 것이 좋다.
1) 실습환경인 Google Colab기준으로 오른쪽 상단에 [연결] - [런타임 유형 변경]을 클릭해준다.

2) 보통 CPU로 설정되어있는 경우가 많기 때문에 [T4 GPU]로 변경 후 [저장]을 누르면 변경된다.

1단계. 데이터 로드
- 인터넷으로부터 이미지 url을 통해 이미지를 가져옴
(※ 단, `webp` 포맷의 데이터는 `request 요청 거부 에러`가 뜰 가능성이 있음) - 웹상 이미지 링크 복사 후 `url` 변수에 할당
# 웹 상에서 이미지 url 복사 후 변수 할당
url = 'https://img.freepik.com/premium-photo/cute-puppy-of-maltipoo-dog-posing-running-isolated-over-white-studio-background-playful-animal_756748-85193.jpg'
url = 'https://cdn.newsquest.co.kr/news/photo/202305/206197_97856_1244.jpg'import requests
from PIL import Image
import matplotlib.pyplot as plt
# 이미지를 웹에서 불러오는 함수
def load_image_from_web(url):
response = requests.get(url, stream=True).raw
img = Image.open(response).convert('RGB')
if img is None :
raise ValueError('url로부터 데이터를 가져오지 못했습니다. 다른 url을 사용해보세요!')
return img
# 이미지 시각화 코드
def imshow(img):
plt.imshow(img)
plt.axis('off')
# 이미지 보기
image = load_image_from_web(url)
imshow(image)
2단계. 전처리 - 모델 학습시 전처리 불러오기
딥러닝 모델로 추론을 할 때는 학습시 전처리와 동일한 과정을 해당 이미지에 적용해줘야한다.
ResNet 모델이 학습할 당시의 전처리 과정이 저장된 클래스가 존재하는데, 전처리 코드를 가져와 사용할 이미지에 적용하면 된다.
📌 클래스 : ResNet 모델의 학습 결과물이 저장된 객체
https://pytorch.org/vision/stable/models/resnet.html
ResNet — Torchvision 0.18 documentation
Shortcuts
pytorch.org
ResNet18_Weights 라는 클래스에 ResNet18 모델이 학습할 당시 전처리 과정이 저장되어있다.

[SOURCE]를 클릭해보면

ResNet18이 학습할 당시에 어떤식으로 전처리되어있는지 코드가 나와있다.
우선, 선택한 모델과 해당 모델 학습 당시의 전처리 과정 코드를 불러올 수 있는 함수 `get_model_and_trans`를 정의한다.
import re
import torchvision.models as models
# 우리가 선택한 모델(resnet18)과 전처리과정을 불러올 수 있는 함수 정의
def get_model_and_trans(model_name):
if model_name not in ['resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152']:
raise ValueError("model name을 확인해주세요. 옵션 : 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152'")
weight_name = 'ResNet' + re.findall(r'\d+', model_name)[0] +'_Weights'
weights = getattr(models, weight_name).DEFAULT
transforms = weights.transforms()
model = getattr(models, model_name)(weights=weights)
model.eval()
meta_data = weights.meta # 메타 데이터(클래스에 대한 정보 등)
return model, transforms, meta_data# 타깃 모델을 선택하고
model_name='resnet18'
# 모델과 그에 맞는 전처리 과정을 불러온다
myModel, transform, meta_data = get_model_and_trans(model_name)
myModel
transform
3단계. 전처리 - 모델에 입력하기 전의 전처리
import torch
# 이미지 전처리 진행
trans_image = transform(image)
trans_image = torch.unsqueeze(trans_image, 0)def imshow_from_tensor(tensor):
image = tensor.cpu().clone() # 텐서 복제
image = image.squeeze(0) # 배치 차원 제거
image = image.permute(1, 2, 0) # 차원 재배열
image = image.numpy()
plt.imshow(image)
plt.axis('off')
plt.show()# 전처리가 진행되면 원본 이미지의 형태가 많이 훼손됨
# 하지만 딥러닝 모델은 이런 형태를 더욱 잘 알아본다고!
imshow_from_tensor(trans_image)
Q. 전처리가 진행된 이후 색감이 바뀐 이유는?
A. 사람이 보는 이미지는 R(빨강), G(초록), B(파랑)가 섞여있는 조합의 색을 인식하는데,
딥러닝 모델도 마찬가지로 R, G, B를 기준으로 이미지를 확인한다.
이 때, 각 색상의 분포가 사람이 보는 색상의 분포와 완전히 똑같지는 않기 때문에,
모델이 잘 확인할 수 있는 형태의 분포로 바뀌어서 학습을 시켜주고 이를 사람이 보게된다.
4단계. 모델에 이미지를 넣어서 결과 분석
# 모델에 입력하고 결과를 출력
output = myModel(trans_image)
ResNet 모델을 1000개 중 딱 1개만 내보내는 모델이다.
그래서 결과값에 1000개가 출력되게 된다.
아래의 1000개 데이터는 각 클래스의 점수이다.
# 1000개의 결과값을 출력
# 이들 중 최고 값을 갖는 값이 출력의 결과값!
print(output)
각 클래스 별 점수가 차등적으로 존재하며, 이 점수들을 바탕으로 max값을 뽑아낼 수 있다.
바로 점수 자체를 뽑는 것은 아니고, 점수들의 확률(`conf`)과 가장 큰 확률의 인덱스(`predicted`)를 뽑아준다.
이를 바탕으로 `meta_data` 안에서 클래스 정보(`"categories"`)를 불러와서 해당 클래스가 무엇인지(`cls`) 뽑아준다.
- `softmax()` : 점수 → 확률 로 변환
import torch.nn.functional as F
# 출력 결과로부터 출력 결과 도출하기
conf, predicted = F.softmax(output, dim=1).max(1)
total_class = meta_data["categories"]
cls = total_class[predicted.item()]
print(f'최종 결과 입력 이미지는 {conf.item()*100:.2f} % 의 확률로 {cls} 이라고 예측됩니다.')
텍스트 데이터 처리
문제
- 텍스트 이해 - 질의응답 / 문자 이해 / 정보 검색
- 텍스트 생성 - 문장 생성 / 요약 / 번역
- 텍스트 분류 및 태깅 - 문장 분류 / 개체명 인싱 / 품사 태깅
- 텍스트 관계 추출 - 문장 관계 추출
대표적 딥러닝 모델 : RNN, Attention module
1. RNN(초기)
: 텍스트와 같은 순차 데이터를 처리하기 위해 고안된 모델로, 이웃한 텍스트 글자 간의 연관성을 표현하는 방식으로 정보를 처리
📌 hidden state(은닉층) : 기억을 담당하는 정보 덩어리 ► 새로운 입력이 들어오면 은닉층을 조금씩 수정
| 사람이 글을 읽는 과정 | 텍스트 처리 과정 |
| 1. 문장의 앞에서부터 한 단어씩 읽음 | 1. 문장의 앞에서부터 한 단어씩 입력으로 받음 |
| 2. 새로운 단어가 들어오면 이를 읽고 이해함 | 2. 새로운 단어가 들어오면 이를 처리해서 정보 추출 |
| 3. 앞서 해석해서 만들어낸 기억 정보에 정보를 추가하여 기억을 업데이트 |
3. 앞서 해석해 만들어낸 정보 덩어리에 추출한 정보를 추가하여 정보를 업데이트 |
| 4. 문장이 끝나는 시점까지 위의 과정을 되풀이 | 4. 문장이 끝나는 시점까지 위 과정을 되풀이(Recurrent) |
사람이 이미지 or 텍스트와 같은 데이터를 다룰 때, 모든 데이터를 같은 중요도로 처리하지 않음
2. Attention(최근) Module
: 특정 요소에만 집중해서 정보를 처리할 수 있도록 만들어낸 모듈 ► 중요한 정보와 중요하지 않은 정보를 구분