
📌 학습목표
1. 머신러닝이란?
2. 메타데이터
3. 레이블
4. 머신러닝의 종류 - 지도학습/비지도학습/준지도학습/자기지도학습/강화학습
5. 데이터 분할 - 학습/검증/평가
6. 과적합
7. 손실과 손실함수
8. 파라미터와 최적화
명시적 프로그램 : 규칙 기반 전문가 시스템(Rule-Based Expert System)
: 문제를 해결하기 위한 규칙(rule)을 사람이 수동으로 사전에 정의하고 해당 정의에 따라서 판단을 내리는 것
(※ 규칙 : 하드 코딩된 `if-else` 명령어의 집합)
- 머신러닝 이전의 문제 해결 방법론
- ex. 스팸 메일을 분류하는 과정 → 특정 단어(Sale, Win, Free 등)의 유무로 스팸 메일을 분류
| 장점 | 단점 |
| - 처리 과정을 사람이 이해하기 쉬움 - 작은 데이터에서 효과적 |
- 특정 규칙은 하나의 분야나 작업에 국한되어 있음 - 변경 대응이 어려움 - 규칙 설계 시 해당 분야의 전문가 필요 |
머신러닝 (Machine Learning; ML)
: 기계 스스로가 데이터로부터 그 안에 있는 특징과 패턴을 찾아서(=학습) 지식을 추출하는 작업
→ 특징과 패턴을 바탕으로 새로운 데이터에 대한 추론을 진행
→ 명시적 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야
- 명시적 프로그램의 한계를 극복할 수 있는 기법
- 데이터 내부에서 자주 발생하는 특징과 패턴(=feature)을 감지
- 문제를 해결하기 위한 판단 기준을 시스템 스스로가 찾아냄
- 구체적으로 명시할 수 없는 규칙을 찾는게 불가능하다면 기계 스스로가 그것을 찾아내게 하는 방법이 best solution
| 장점 | 단점 |
| - 예상치 못한 상관관계를 파악하는데 탁월함 - 특정 도메인에서 전문가가 필수로 필요하지 않음 |
- 기계가 패턴(feature)을 파악할 수 있도록 다양한 데이터 필요 - 결과 분석 과정에서 사람이 이해할 수 없는 포인트가 존재할 수 있음 |
인공지능 vs. 머신러닝 vs. 딥러닝

- 인공지능 (Artificial Intelligence; AI) : 사람이 아닌 것이 사람의 지능을 모방한 형태
- 머신 러닝 (Machine Learning; ML) : 기계를 학습시키면서 사람의 지능을 모방하도록 하는 작업
- 딥러닝 (Deep Learning; DL) : 머신 러닝을 하는 여러가지 학습 방법 중 하나로, 컴퓨터가 사람의 지적 인지과정의 한 단위인 '뉴런'을 모방한 것을 시각적으로 표현해내고 그러한 모델을 가지고 여러 문제를 풀어내는 작업
머신러닝과 딥러닝 활용 사례
- 머신러닝은 다양한 어플리케이션과 연구 분야에서 활용
- 최근 딥러닝의 발전으로 매우 다양한 분야에서 다양한 목적으로 사용됨
- 추천 : 영화, 음식, 쇼핑 등
- FaceID : 암호
- 의료 영상 처리 : 종양 진단, 병변 예측 등
- 음성 처리 : TTS(Test to Speech), STT(Speech to Test) 등
- 금융 데이터 예측 : 수익 예측, 이상 거래 감지 등
머신러닝 프로젝트의 흐름
- 문제 정의
- 파이프라인
- 모델 입/출력 - 데이터 확인
- 시각화
- 특성 파악 - 데이터 분할
- 학습/검증/테스트용 데이터로 분할
- 편향성 확인
- 이상치(outlier) 제거 - 알고리즘 탐색
- 선행 연구 및 선행 프로젝트 참고 - 데이터 전처리
- 알고리즘 고려한 전처리(알고리즘에 따라 다름)
- 선행 과정 참고 - 학습과 검증
- 최적 모델 탐색
- 반복 작업(피드백) - 최종 테스트
- 테스트 데이터 활용
- 보고 - 시스템 런칭
- 모니터링
- 유지 보수
메타 데이터 (Meta Data)
: 주어진 기본 데이터에 추가적으로 제공하는 정보 (= 실제로 학습에 활용되는 파트를 제외한 부분)
- 데이터의 출처, 형식, 위치 등 데이터 간의 관계와 구조 파악
- 데이터의 속성, 특성, 분류 등 데이터의 내용 설명
레이블 (Label)
: 특정 문제에 해당하는 데이터의 설명 혹은 답변 (= 실제로 학습에 활용하는 파트에 포함된 부분)
- 분류를 하는 문제라면 데이터가 속할 범주(= 클래스, class)
- 목표 값을 찾는 회귀 문제라면 데이터가 표현할 특정 숫자
- 대부분 사람이 직접 생성해줘야 하는 경우가 많음
- 정답 혹은 타겟(target)이라고 부르기도 함
머신러닝 종류
1. 지도 학습 (Supervised Learning)
: 정답 레이블 정보를 활용해 알고리즘을 학습하는 학습 방법론
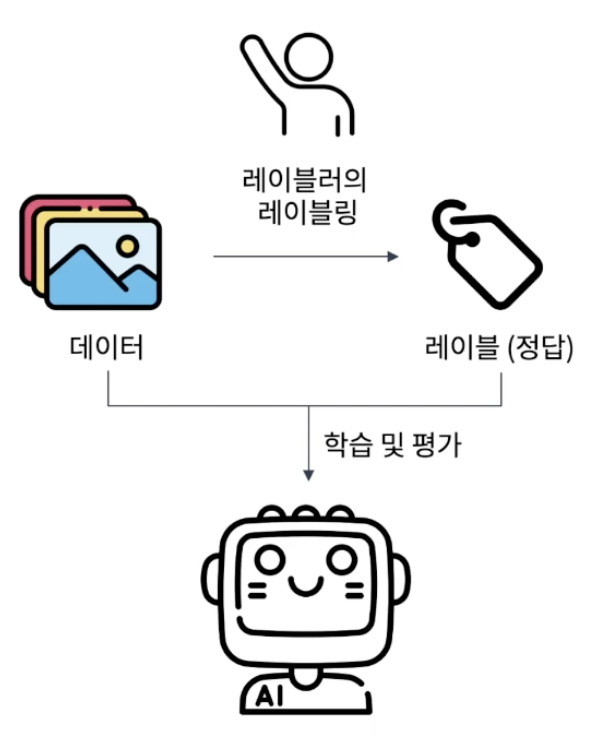
- 목적 : 입력 데이터와 정답인 출력 레이블 사이의 관계를 파악하는 것
- 장점 :
- 정답이 존재하기 때문에 모델이 풀어야될 문제가 비교적 쉽고 잘 학습됨
- 명확한 평가 수치가 존재 → 학습된 모델 성능 측정이 용이함
- 단점 :
- 정답이 필요하므로 이를 위한 추가적인 시간/노동/비용 필요
- 정답을 매기는 행위에 필요한 전문 인력과 같은 추가 비용 발생
1-1. 지도 학습에서 다루는 문제
📌 문제(Task)
: 머신 러닝 기법을 활용해 해결하고자 하는 대상
1) 회귀 문제(Regression Problem)
: 주어진 입력 데이터에 대해 연속적인 숫자값을 예측하는 문제
- 주관식 문제와 비슷
- 입력 데이터를 바탕으로 정확한 숫자(정수 or 실수 범위의 수) 형태의 결과를 예측하는 문제
- 예시 :
- 내일 주식 가격은? 53,228.3 원
- 5년 뒤 나의 몸무게는? 73.2 kg
- 선형 회귀 (Linear Regression)
- 기본적이고 널리 사용되는 회귀 알고리즘
- 독립변수와 종속변수 간의 선형관계를 모델링
- 라쏘 회귀 혹은 릿지 회귀 (Lasso & Ridge Regression)
- 규제 기법을 이용해 과적합을 방지하고 일반화 성능이 향상된 선형 모델
- 결정 트리 회귀 (Decision Tree Regression)
- 결정 트리를 이용해 회귀문제에 적용
- 서포트 벡터 회귀 (Support Vector Regression, SVR)
- 분류 모델인 SVM을 회귀에 적용한 알고리즘
- K-최근접 이웃 회귀 (K-Nearest Neighbors Regression)
- 주어진 데이터 포인트에서 가장 가까운 K개의 이웃 데이터의 평균으로 예측값을 결정
- 간단하면서도 데이터 자체만을 활용한 추정(비모수적 추적)이 가능
2) 분류 문제(Classification Problem)
: 주어진 입력 데이터가 어떤 범주(클래스)에 속하는지 판별하는 문제
- 5지선다형 객관식 문제와 비슷
- 입력으로 주어지는 데이터를 정해진 보기(Class) 중 하나로 분류하는 문제
✓ 분류 문제의 세분화
주어진 클래스의 수 & 모델이 결과로 출력하는 수 등에 따라 나뉨
- 이진 분류 문제 : 주어지는 클래스가 2개인 경우
- 다중 클래스 문제 : 모델이 여러 클래스를 내보내야 하는 경우
- 로지스틱 회귀 (Logistic Regression)
- 이진 분류 문제에 적합한 구조
- 확률을 직접 예측하는 확률 추정 접근으로 결과를 예측
- 결정 트리 분류기 (Decision Tree Classifier)
- 데이터를 잘 분할하는 결정 트리를 사용하여 분류를 수행
- 직관적이고 이해가 쉬움
- 랜덤 포레스트 (Random Forest)
- 여러 결정 트리의 결합으로 앙상블 기법에 해당
- 높은 정확도를 보이면서도 과적합 문제를 방지함
- 서포트 벡터 머신 (Support vector Machine, SVM)
- 데이터를 최적으로 분리하는 결정 경계를 찾는데 강력한 알고리즘
- 어려운 형태의 데이터라도 비선형 계산이 가능한 다양한 커널 트릭 있어야 해를 구할 수 있음
2. 비지도 학습 (Un-Supervised Learning)
: 정답 레이블 정보 없이 입력 데이터만을 활용해 알고리즘을 학습하는 학습 방법론
- 목적 : 데이터 내부에 존재하는 패턴을 스스로 파악하는 것
- 장점 :
- 따로 정답을 준비할 필요가 없어서 비용 측면에서 이점이 있음
- 사용자가 의도한 패턴 이외의 새로운 패턴을 찾을 가능성 존재 → 창작과 같은 다양한 활용 분야에 사용 가능
- 단점 :
- 학습된 모델 성능 측정 기준이 없어서 결과 해석이 주관적일 수 있음
- 신뢰할만한 결과를 얻기 위해 다수의 데이터 필요
3. 준지도 학습 (Semi-Supervised Learning)
: 일부 데이터만 정답이 존재하고, 다수 데이터에는 레이블이 없는 상황에서 알고리즘을 학습하는 학습 방법론
= 지도학습 + 비지도학습
- 목적 : 일부 레이블링 된 데이터로 특성을 파악하고, 레이블링 되지 않은 데이터로 전체 데이터의 패턴을 파악하는 것
- 장점 :
- 레이블이 부족한 데이터셋에서 유용함
- 많은 데이터 활용이 가능하므로 일반화 성능을 향상시킬 수 있음
- 단점 :
- 품질이 낮은 레이블이나 데이터 존재에 특히 취약
- 알고리즘의 복잡성이 증가 → 구현 및 활용에 어려움
4. 자기 지도 학습 (Self-Supervised Learning)
: 정답이 하나도 없는 데이터에서 정답을 강제로 생성한 후 학습하는 학습 방법론

- 목적 : 데이터 내부를 강제로 훼손 후 복원하는 방법 사용하며, 이 과정에서 특정 데이터 내부의 성질을 파악하고 해당 데이터를 이용한 다른 문제에 적용시킴
- 장점 :
- 레이블 없이 데이터의 특징 파악 가능
- 다양한 데이터에 활용 가능
- 단점 :
- 목적하는 문제를 직접적으로 해결하는 것이 아님 → N회 이상의 추가 학습이 필요할 수 있음
- 알고리즘이 잘못된 패턴을 학습할 위험이 있음
5. 강화 학습 (Reinforcement Learning)
: 어떤 환경(Environment)에서 상호작용하는 에이전트(Agent)가 보상(Reward)을 이용해 특정 행동을 하도록 유도하는 학습 방법론
※ `에이전트(Agent)` : 행동을 하는 주체
※ `환경(Environment)` : 에이전트와 행동을 포함한 큰 구역
※ `보상(Reward)` : 에이전트가 환경 안에서 특정 행동을 잘하면 보상을 주고 못하면 패널티를 줌
- 예시) 강아지에게 "앉아"를 가르키는 훈련사
- 강아지 : 다양한 행동을 함
- 훈련사 : 강아지가 앉는 행동을 하면 간식을 줌
- 전개 상황 :
- 강아지는 어쩌다가 먹은 간식을 더 많이 먹기 위해
- 본인이 간식을 먹을 수 있는 상황을 인지하게 되고
- 지속적으로 그런 행동을 반복
- 대표적 알고리즘 : 알파고
데이터 분할 : 학습 / 검증 / 평가
ex) 시험을 보는 학생의 공부 방법을 생각해보자.
- 이론지 : 학습을 통해 정보를 습득하고 이해하는 과정에서 사용 ► 학습 데이터 (train data)
- 모의고사 : 습득한 정보를 연습하고 중간중간 학습상태를 확인 ► 검증 데이터 (validation data)
- 시험 : 모의고사를 통해 최적의 공부상태를 만들고 시험을 진행 ► 평가 데이터 (test data)

# 전체 데이터를 기준으로
All_data = Load_All_dataset()
# 학습 데이터 준비 (80%) = 이론지
train_dataset = split_from(All_data, 0.8)
# 검증 데이터 준비 (10%) = 모의고사
val_dataset = split_from(All_data, 0.1)
# 평가 데이터 준비 (10%) = 실제 시험
test_dataset = split_from(All_data, 0.1)
1. 학습 데이터(Train data) = 이론지
: 순수하게 학습을 하는 과정에서 사용하는 데이터
- 갖고 있는 전체 데이터 중 가장 많은 비율을 차지함
- 정해진 정답은 없지만 약 80% 정도를 사용
- 이 분류에 속한 데이터가 많으면 많을수록 성능이 좋아질 가능성이 커짐
2. 검증 데이터(Validation data) = 모의고사
: 학습을 진행하는 중간 과정에서 머신 러닝 모델이 어느 정도 학습 되었는지를 주기적으로 확인하는데 사용하는 데이터
- 검증 과정은 학습 중간에 진행되는 평가라고 생각할 수 있음
- 모의고사를 통해 전체 시험범위 중 부족한 단원을 찾는 것과 같이, 학습의 정도를 판단할 수 있음
- 전체 데이터 중 약 10% 정도를 할당
3. 평가 데이터(Test data) = 시험
: 학습의 과정과는 별도의 과정으로, 최종 머신러닝 모델이 생성된 후 학습한 모델의 최종 성능을 평가하기 위해 사용되는 데이터
- 시험공부 기간 중 중간/기말고사 시험지를 미리볼 수 없듯, 평가 데이터는 학습 과정에서는 절대 사용되지 않음
- 완성된 머신러닝 모델이 서비스 혹은 제품과 같이 실제 사용 시나리오 과정에서 보게 될 데이터라는 가정으로 만들어진 데이터
- 전체 데이터 중 약 10% 정도를 할당
과적합 (Overfitting)
: 머신러닝 모델이 특정 훈련 데이터에 지나치게 학습되어 새로운 데이터 or 테스트 데이터에서 잘 작동하지 않는 상태(문제)
= 일반화 능력이 떨어진 상태
일반화 능력(Generalization)
: 새로운 데이터에서 잘 작동하는 상태

- 학습 데이터에 포함된 특정 패턴이나 디테일 그리고 작은 노이즈까지 학습해서 '단순히 데이터를 외워버린 경우'
- 머신 러닝 모델이 경계해야하는 현상
- 해결 방법 :
- 데이터 양 늘리기
- 머신 러닝 모델의 복잡도를 줄이기
- 규제와 같은 정규화 기법 사용하기
손실 함수 (Loss Function)
: 머신러닝 모델의 손실을 구하는 함수
📌 손실(Loss)
: 학습한 모델이 잘 하고 있는지 or 못하고 있는지를 수치적으로 표현한 것
= 모델의 예측값과 실제 정답 사이의 차이를 측정하는 지표
※ 손실이 작을수록 모델의 성능이 좋다고 볼 수 있음
► 머신 러닝 모델을 학습하는 과정은 손실(Loss)를 줄이는 과정으로 진행 됨
✓ 손실 함수의 종류
해결하고자 하는 문제의 유형(회귀, 분류 등)에 따라 다름
- 회귀 문제 : 평균 제곱 오차 (Mean Squared Error; MSE)
- 분류 문제 : 교차 엔트로피 (Cross Entropy)
- 이진 분류 문제 : 로그 손실(LogLoss)
파라미터 (Parameter)
: 머신러닝 모델이 내부적으로 갖고 있는 변수
- 변수 :
- 모델이 데이터로부터 학습하는 패턴 관계를 표현
- 모델의 예측 성능에 직접적인 영향을 미침
- 파라미터의 구조와 조합은 모델마다 다양하며 이 변수의 값은 학습의 과정으로 찾아야 함
- 성능이 좋은 모델은 적절한 구조의 파라미터로 구성됨
- 파라미터의 구체적인 값은 데이터를 이용한 학습으로 찾게됨
최적화 (Optimization)
: 머신ㄴ러닝에서 모델의 성능을 최대화하거나, 오류를 최소화하기 위해 모델의 파라미터를 조절하는 과정
= 손실(Loss) 값이 최소가 되는 파라미터를 찾는 것이 목표
최적화 적용 과정은 머신러닝 모델에 따라 다름
- 최적의 해를 한번에 구하는 경우
- 점진적이고 반복적으로 해를 구하는 경우