
📌 학습목표
1. 데이터 분석을 해야하는 이유
2. 데이터 분석 프로세스
3. 데이터 분석 툴(Google Colab) 소개
4. 데이터 정규화 및 스케일링
데이터 분석을 해야하는 이유
산업의 변화
제조업 → 서비스 기업
- 데이터를 이용한 가치를 판매
- 예시 :
- Amazon : 데이터 분석을 이용한 예측배송 서비스
- Google, Facebook : 데이터 분석을 이용한 온라인 광고 서비스
- Netflix : 데이터 분석을 이용한 콘텐츠 추천 서비스
데이터 분석이란?
: 데이터를 정리/변환/조작/검사 하여 "인사이트"를 만들어내는 작업
데이터 분석을 해야하는 이유
→ 의사결정 판단의 기준이 주관적 직감에서 객관적 데이터로 바뀔 수 있음
- 주어진 데이터로 문제를 해결할 수 있을지 없을지 판단하는 것 또한 데이터 분석
- 단순한 분석보다 어떻게 문제를 해결할지에 대한 고민이 더 중요함
데이터 분석 프로세스
1. 문제 정의
2. 데이터 수집
3. 데이터 전처리
4. 데이터 분석
5. 리포팅 / 피드백
1. 문제 정의
풀고자 하는 문제가 명확해야 함
- 궁극적으로 해결하고자 하는 문제 혹은 달성하려는 목표가 무엇인가?
- 해당 문제를 일으키는 원인은?
- 상황을 판단할 수 있는 지표나 기준은 무엇인가?
문제 정의 프로세스
- 큰 문제(Main Objective)를 작은 단위의 문제들(Sub Objectives)로 나눈다.
- 각각의 작은 문제들에 대해 여러가지 가설을 세운다.
- 데이터 분석을 통해 가설들을 검증하고 결론 도출 및 피드백을 반영한다.
메타 인지 관점에서 '문제 정의'에 대한 충분한 고민이 필요함
🔎 예시
- 인구 감소[문제] ← 저출산 및 인구 유출[원인]
- 노동 인구 부족, 내수시장 구매력 부족 [문제] ← 인구 감소[원인]
► 이처럼 '인구감소'라는 동일한 상황이 [문제]가 될 수도 있고, [원인]이 될 수도 있다.
★ 메타인지
: 어떠한 생각이 꼬리에 꼬리를 무는 체인을 만들어나가는 과정
🔎 예시
- 인플레이션[현상] ← 공급자 비용 증가 ← 노동시장 비용 증가 ← 노동 인구 부족 ← 인구 감소 ← 저출산 및 인구 유출[원인]
► [원인]과 [결과]에 대한 연결고리가 확연하거나 부족하다는 점을 '데이터 분석'을 통해 판단하여 가설을 세우고 증명할 수 있다.
2. 데이터 수집
가설을 해결해줄 데이터를 수집
고려해야할 점
- 가설 검증에 필요한 데이터가 존재하는가?
→ 데이터가 가설 검증에 부적절 혹은 없을 수 있음 - 어떤 종류의 데이터가 필요한지?
→ 흩어져있는 방대한 양의 데이터로부터 얻고자 하는 정보가 무엇인지 명확히 해야 필요한 데이터만 모을 수 있음 - 얻고자 하는 데이터의 지표는 명확한가?
→ 적절해 보이는 데이터라도 지표가 부적절하면 가설 검증 및 결론 도출시 오류를 범할 수 있음
3. 데이터 전처리
- 데이터 추출/필터링/그룹핑/조인 등 (with SQL, DB)
- 데이터 분석을 위한 기본적인 테이블을 만드는 단계
- 테이블과 칼럼의 명칭, 처리/집계 기준, 조인시 데이터 증식 방지 목적 - 이상치 제거/분포 변환/표준화/카테고리화/차원 축소 등 (with Python, R)
- 수집한 데이터를 분석에 용이한 형태로 만드는 단계
4. 데이터 분석
- 탐색적 데이터 분석(EDA)
- 그룹별 기술적 통계치(평균, 합 등) 확인
- 분포 확인
- 변수 간 관계 및 영향력 파악
- 데이터 시각화 - 모델링(머신러닝, 딥러닝)
- Classification(분류 분석) : categorical label
- Regression(회귀 분석) : numerical label
- Clustering(클러스터링) : 비지도학습
5. 리포팅 / 피드백
내용의 초점은 데이터 분석가가 아닌 '상대방'
- 상대가 이해 가능한 언어 사용
- 목적을 수시로 상기하고 재확인
적절한 시각화 방법 활용
- 항목간 비교 - 원그래프 지양 → 막대 그래프 지향 (x, y축 및 단위 주의하기)
- 시계열 - 라인, 실선
- 분포 - 히스토그램, 박스플롯
- 변수간 관계 - 산점도
데이터 분석 툴(Google Colab) 소개
Google Colab
: 클라우드 기반의 Jupyter Notebook 개발 환경
- 웹 브라우저에서 텍스트와 코드를 자유롭게 작성할 수 있는 일종의 '온라인 텍스트 에디터'
- 클라우드 기반이기 때문에 CPU와 RAM을 제공
→ 사용자의 로컬 컴퓨터에 있는 프로세서를 이용하는 것이 아니라 인터넷을 통해 연결된 '서버(Server)'에서 연산들을 진행한다.
→ 따라서, 컴퓨터 성능과 상관없이 프로그램 실습이 가능하다. - Colab에서 사용할 수 있는 프로그래밍 언어는 Python
- 노트북(`.ipynb`) : Colab 파일
Cell
: 코드를 실행시키거나 설명 텍스트를 작성할 수 있는 블록
- 코드 셀(code cell) : 작성된 코드를 실행시키는 블록
- 텍스트 셀(text cell) : 설명에 필요한 텍스트 입력이 가능한 곳으로, 입력 문법은 markdown(마크다운) 문법을 따른다.
유용한 단축키
- `Ctrl` + `Enter` : 작성한 코드를 실행한 후, 키보드 커서가 셀 안에 그대로 유지
- `Shift` + `Enter` : 작성한 코드를 실행한 후, 키보드 커서가 다음 셀로 내려감
- `Alt` + `Enter` : 작성한 코드를 실행한 후, 새 코드셀을 생성하고 키보드 커서가 다음 셀로 내려감
- 코드 셀 클릭 + `a` : 클릭한 코드셀 위로 빈 셀이 생성됨
- 코드 셀 클릭 + `b` : 클릭한 코드셀 아래로 빈 셀이 생성됨
데이터 정규화 (Normalization) & 스케일링(Scaling)
: 여러가지 값(feature)들이 가지는 범위의 차이를 왜곡하지 않으면서 범위를 맞춰주는 과정
정규화가 필요한 이유
데이터에서 하나의 instance(sample)는 그것이 가진 여러 속성값(feature)을 이용해서 표현 가능하다.
이러한 feature들 간의 크기/단위가 들쭉날쭉 하거나, 값의 범위가 크게 다르거나, 이상치(outlier)문제가 심각할 경우,
→ 데이터 분석이 어려워진다.
→ 모델링(ML, DL) 기법의 적용이 어려워진다.
(특히, ML모델에 feature 값들을 input으로 사용하는 경우, feature의 스케일이 일정하지 않으면 모델이 데이터를 이상하게 해석될 수 있음)
► 이때, 정규화와 스케일링을 통해 feature들이 갖는 값의 범위를 일정하게 맞춰줄 수 있다.
1. Min-Max Normalization
: 모든 feature 값이 [0, 1] 사이에 위치하도록 scaling하는 기법

- feature들 간 variance 패턴(퍼져있는 비율)은 그대로 유지한 채 scaling 된다.
- 즉, 특정 feature값의 variance가 매우 큰 경우 혹은 이상치가 존재하는 경우,
Min-Max 정규화를 거쳐도 여전히 feature간의 scaling이 데이터 분석에 적절하지 않을 수 있다.
import numpy as np
import pandas as pd
import seaborn as sns # 데이터 셋을 가져오기 위함
import warnings
warnings.filterwarnings('ignore')# 사이킷런 패키지 불러오기
from sklearn.preprocessing import MinMaxScaler, StandardScaler# titanic 데이터셋 로드
df = sns.load_dataset('titanic')
df = df.loc[df['age'].isna()==False].reset_index(drop=True)
df
# 히스토그램 그려보기 (bins : 히스토그램 막대 하나의 칸 간격)
df['age'].hist(bins=30)
df['fare'].hist(bins=30)
# Min-Max Scaling
scaler = MinMaxScaler() # MinMaxScaler 클래스 (scaler라는 변수에 인스턴스를 넣는다)
# 클래스 내 fit_transform 함수 사용
df['fare_minmax'] = scaler.fit_transform(df['fare'].values.reshape(-1, 1)) # .values : ['fare']컬럼에 해당하는 값들을 numpy array로 변환
df['age_minmax'] = scaler.fit_transform(df['age'].values.reshape(-1, 1))# 분포 확인해보기
df['age_minmax'].hist(bins=30)
# 분포 확인해보기
df['fare_minmax'].hist(bins=30)
2. Z-score Normalization(=Standardization; 표준화)
: feature 값들이 μ(평균) = 0, σ(표준편차) = 1 값을 가지는 정규분포를 따르도록 scaling하는 기법

- 이상치 문제에 상대적으로 robust(문제에 영향을 덜 받는, 민감하지 않은)한 scaliing 기법
- Min-Max 정규화처럼 feature값이 가지는 최소값-최대값 범위가 정해지지 않는 단점이 있다.
- 대부분의 머신러닝 기법들을 활용하는 경우 input에 Standardization을 적용해야하는 경우가 많은데,
이를 통해서 Gradient descent를 활용한 학습 과정(인공신경망, 딥러닝 등)을 안정시켜주고 빠른 수렴을 가능하게 한다. - z-score가 ±1.5σ, ±2σ를 벗어나는 경우 해당 데이터를 이상치로 간주하고 제거할 수 있다.
# Standardization
scaler = StandardScaler()
df['fare_standard'] = scaler.fit_transform(df['fare'].values.reshape(-1, 1))
df['age_standard'] = scaler.fit_transform(df['age'].values.reshape(-1, 1))# 분포 확인해보기
df['age_standard'].hist(bins=30)

# 분포 확인해보기
df['fare_standard'].hist(bins=30)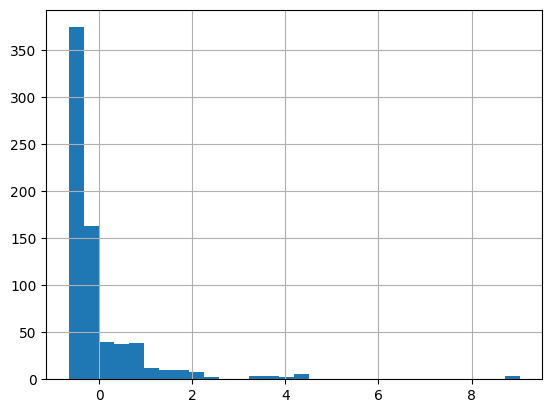
3. Log Scaling
: feature 값들이 exponential한 분포(positive skewed)를 가지는 경우, feature 값들에 log연산을 취하여 scaling하는 기법

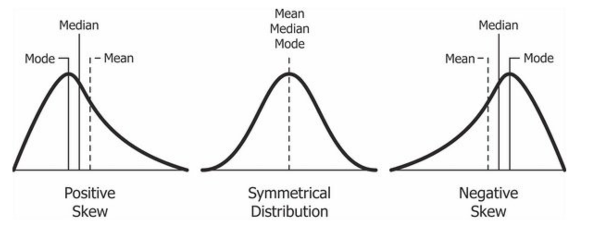
- 비슷한 방식으로 제곱근을 취하거나 반대의 분포를 가지는 경우 power/exponential 연산을 통해 scaling할 수 있다.
- 다양한 scaling을 통해 데이터가 좀 더 정규분포에 가까워지도록 스케일링하며, 이상치 문제도 보다 적극적으로 대응 가능하다.
# np random 함수를 통해 난수 생성
exp_scale_data = np.random.exponential(1,300) # .exponential : 지수적으로 커지는 (positive skewed형태를 따르는 난수 생성을 가능케 한다)
df_exp = pd.DataFrame(columns=['x'])
df_exp['x'] = exp_scale_data # 연속된 값이 나온다
# 확인
df_exp['x'].hist(bins=30)
# Log scaling
df_exp['log_x'] = np.log(df_exp['x'])# 분포 확인해보기
df_exp['log_x'].hist(bins=30)
# 'fare'컬럼에 0값이 존재하는지 확인 -> 존재
0 in df['fare'].valuesTrue
# log(0) = -inf 이기 때문에 log scaling을 진행하기 어려워진다.
# 따라서 log 대신 square root로 scaling해야 한다.
df['fare_sqrt'] = np.sqrt(df['fare'])
# 확인
df['fare_sqrt'].hist(bins=30)