
📌 학습목표
1. 행렬 전치 - transpose
2. 인덱스 레벨 제어 - stack/unstack/droplevel
3. 재구조화 - melt
4. 피벗/피벗테이블 - pivot/pivot_table
5. 그룹화 - groupby
.transpose() 또는 .T()
: 행과 열을 주대각선을 축으로 서로 반사대칭하여 얻게 되는 전치 행렬을 반환한다. (비파괴적 처리)
- `args` : 인자 (튜플이 올수도 있음)
- `copy` : 전치시킨 이후에 행렬을 복제할 것인지 여부
- `False` : 복제 O ← 디폴트
- `True` : 복제 X
[예제]
원본이 아래와 같을 때
# 원본
students
행렬 전치를 수행하면
# 전치를 해보면..
students.transpose()
※ 전치를 2번 시행한것과 원본은 같아보이지만 dtype은 다르다
Pandas의 DataFrame은 하나의 열에 해당하는 데이터들의 dtype이 일치해야 한다.
전치를 1번 하면 모든 dtype이 문자열(object)로 바뀌는데, 전치를 2번해도 원래 dtype으로 원상복귀되지는 않는다.
[예제]
원본 데이터가 아래와 같을 때
# 원본
company.info()
company.head()
전치를 1번 수행하면
# 전치 1회
t1_company = company.T
t1_company.info()
t1_company.head()

전치를 2번 수행하면
# 전치 2회
t2_company = t1_company.T
t2_company.info()
t2_company.head()
.stack()
: columns에 다중 인덱스가 있는 DataFrame에서 사용하면 column index가 row index의 레벨로 이동한다. (열→행)
즉, column(열)을 row(행)로 "압축"하는 작업을 수행한 후, 스택된 DataFrame 또는 Series를 반환
- `level` : column 축에서 index 축으로 스택할 레벨 지정
- -1 : 레벨이 높은 것이 자동 지정(-1은 역순이기 때문) ← 디폴트
- int
- str
- list
- `dropna` : 결과 DataFrame 또는 Series에서 결측치를 갖는 행을 삭제할지 여부
(column 레벨을 index축에 스택하면 원본 DataFrame에 없는 index와 column값의 조합이 생성될 수 있음)
- `True` : 정렬 O ← 디폴트
- `False` : 정렬 X
- `sort` : 결과 multi index의 레벨을 정렬할지 여부
- `True` : 정렬 O ← 디폴트
- `False` : 정렬 X
- `future_stack` : 현재 구현체를 대체할 새로운 구현체를 사용할지 여부
- `True` : 대체 O (`dropna`와 `sort`는 결과에 영향을 미치지 않으며 지정하지 않아야 함)
- `False` : 대체 X ← 디폴트
[예제]
원본 데이터가 아래와 같을 때
# 원본
richest
스택처리하면 Series가 만들어진다.
# Series가 만들어짐
richest.stack()
.unstack()
: 스택 처리에서 다시 되돌아가는 작업, 즉 row index에서 column index의 레벨로 이동함 (행→열)
- 기존 열은 level 0
- `.unstack()`으로 지정된 index는 level 1
- 교차가 되지 않는 값은 NA로 지정된다.
[예제]
원본 데이터가 아래와 같을 때
richest = pd.read_csv('TopRichestInWorld.csv', index_col=['Industry', 'Name'])
richest
디폴트 값은 `level = -1`이다.
# 기본 unstack(level=-1)
richest_industry = richest.unstack()
richest_industry
`level=0`으로 변경해준다면
# 지정 unstack(level=0)
richest_name = richest.unstack(level = 0)
richest_name
.droplevel(level= , axis= )
: 스택/언스택 처리를 하다보면 불필요한 열이 생기기도 하는데, 이를 제거하고 싶을 때 사용하는 메소드(비파괴적 처리)
richest = richest.droplevel(level=0, axis=1)
richest
Unpivot
: 데이터프레임의 구조를 변형하여 넓은(wide) 형식에서 긴(long) 형식으로 데이터를 재구성하는 작업
► 데이터프레임에서 측정 변수를 열 → 행 방향으로 이동시켜 긴(long) 형식으로 변환하는 것
► 이를 통해 데이터의 구조를 변경/분석/시각화 작업에 더 적합한 형태로 재구성 가능
넓은(wide) 형식의 데이터프레임
- 각 행이 고유한 식별자를 갖고 있음
- 각 열은 실제 관측값이 있는 열로 구성
긴(long) 형식의 데이터프레임
- 각 행이 하나의 관측값을 갖고 있음
- 식별자 변수와 측정 변수를 나타내는 열로 구성
.melt()
: 넓은(wide) 형식으로 구성된 데이터프레임을 긴(long) 형식으로 변환하여 데이터를 재구성하여 언피벗된 데이터프레임을 반환
(비파괴적 처리)
► 함수를 사용하면 하나 이상의 열을 식별자 변수(id_vars)로 설정하고, 나머지 열인 측정 변수(value_vars)를 행 방향으로 언피벗하여 두 개의 비-식별자 열인 variable과 value만 남게 되는 형태로 데이터프레임을 변환
- `id_vars` : 식별자 변수(유일한 기준값)로 사용할 열 지정 (tuple, list, ndarray 등)
- `value_vars` : 언피벗 할 열 지정 (지정하지 않으면 `id_vars`로 설정되지 않은 모든 열이 사용)
- `var_name` : 'variable' 열에 사용할 이름 지정
- 스칼라 값
- `None`: `frame.columnsname` 또는 `variable`이 사용됨
- `value_name` : 'value' 열에 사용할 이름 지정
- 스칼라 값
- `'value'` ← 디폴트
- `col_level` : 열이 멀티인덱스인 경우 해당 레벨을 사용하여 언피벗 (int, str 등)
- `ignore_index` : 원래의 인덱스를 무시할지 유지할지 여부 지정
- `True`: 원래의 인덱스 무시 ← 디폴트
- `False`: 원래의 인덱스 유지
[예제]
원본 데이터가 아래와 같을 때
# sample3.csv - 역대한국야구순위
league = pd.read_csv('sample3.csv')
league
cols = league.columns.drop('팀이름')
cols
league.melt(id_vars='팀이름', value_vars=cols, var_name='연도', value_name='순위')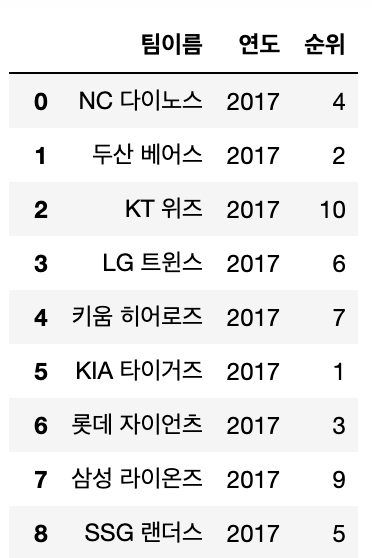
피벗 테이블 (Pivot Table)
: 원본 테이블에서 필요한 데이터를 가지고 집계한 테이블
.pivot()
: 피벗을 통해 데이터 분석과 시각화에 용이한 wide 형태의 DataFrame으로 반환한다. (long → wide)
► `.melt()`와 반대되는 역할
- `columns` : 피벗 테이블의 열을 구성하기 위해 사용할 열 지정
- `index` : 피벗 테이블의 인덱스를 구성하기 위해 사용할 열 지정 (지정하지 않으면 기존 인덱스 사용)
- `values` : 피벗 테이블의 값으로 사용할 열 지정 (지정하지 않으면 나머지 모든 열 사용)
→ 계층적으로 인덱싱된 열을 가진 데이터 프레임이 반환됨
[예제]
원본 데이터가 아래와 같을 때
import pandas as pd
# sample2.csv - 연도별사원성과
company = pd.read_csv('sample2.csv')
company.head()
연도별로 사원 이름 나열해보자. (wide형태로 만들어짐)
# 연도별로 사원 이름 나열(-> wide형태로 만들어짐)
company.pivot(index='연도', columns='사원이름', values='연도별매출')
values를 생략하면 나머지 모든 열들이 multi index로 변환된다.
# values를 생략하면 모든 열이 사용됨 -> 나머지 열들이 멀티인덱스로 변환됨
company.pivot(index='사원이름', columns='연도')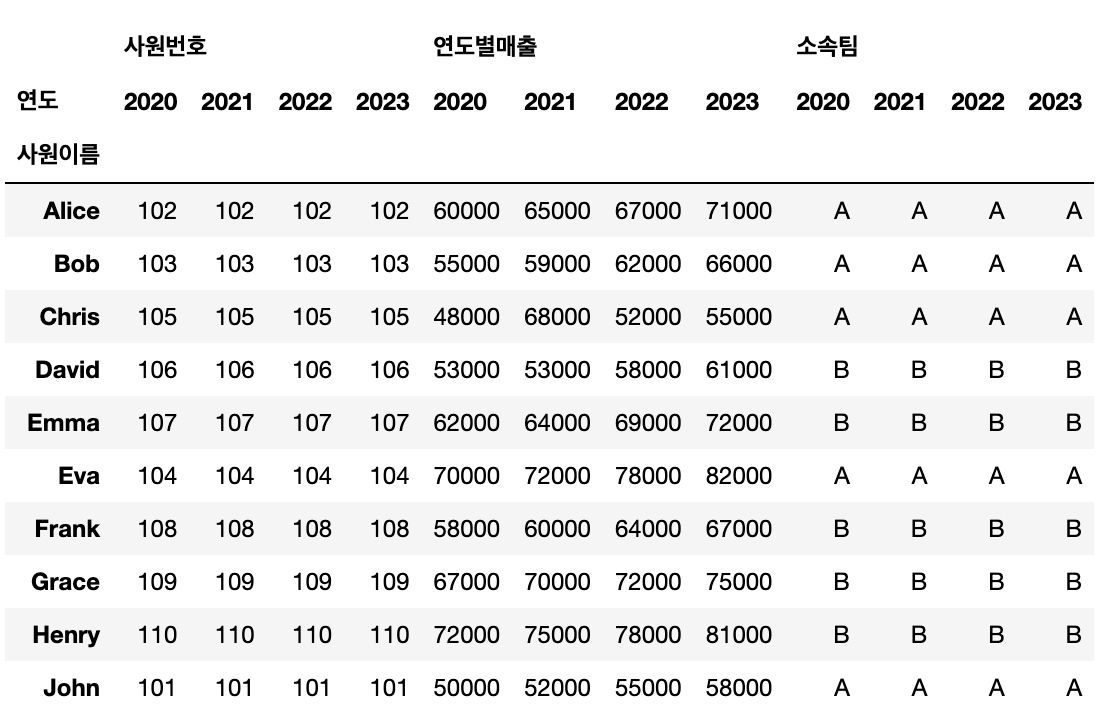
만일 index를 그대로 쓰고 싶다면
# 만일 index를 그대로 쓰고 싶다면
company.set_index('사원이름').pivot(columns='연도')
.pivot_table()
: 집계함수를 활용해서 Excel 스타일의 피벗 테이블을 생성하고, 이를 DataFrame으로 반환한다.
- `values` : 집계할 열을 전달
- `index` : 피벗 테이블에서 그룹하할 키(=열)을 전달
- `aggfunc` : 집계함수를 지정
- `mean` : 평균 계산 ← 디폴트
- list of functions : 여러 개 함수를 전달하며, 계층적인 열이 생성됨
- dict : 키는 집계할 열, 값은 함수/함수목록을 전달
- `margin=False` : `aggfunc`를 사용하여 부분 집계를 계산
- `fill_value` : 결측치의 대체값 지정
- scalar
- None ← 디폴트
- `margins` : 행과 열의 범주에 걸쳐 부분 그룹 집계가 포함된 특수 모든 열과 행이 추가될지 여부 지정
- `True`: 지정함
- `False` : 지정 않함 ← 디폴트
- `dropna` : 결측치 열이 있는 행을 제외할지 여부 지정
- `True` : NA 열이 있는 행은 제외됨 ← 디폴트
- `False` : 제외되지 않음
- `margins_name` : `margins=True`인 경우에 추가되는 행 또는 열의 이름 지정
- str
- `'All'`
- `observed` : 그룹화가 범주형인 경우에만 적용하는 파라미터
- `True` : 범주형 그룹화에 대해 관찰된 값만 표시
- `False` : 범주형 그룹화에 대한 모든 값을 표시 ← 디폴트
- `sort` : 결과를 정렬할지 여부 지정
- `True` : 정렬함 ← 디폴트
- `False` : 정렬 안함
[예제]
원본 데이터가 아래와 같을 때
import pandas as pd
# sample2.csv - 연도별사원성과
company = pd.read_csv('sample2.csv')
company.head()
사원별 '연도별매출'을 누적 통계내보자.
# 사원별 '연도별매출' 누적 통계내기
company.pivot_table(values='연도별매출', columns='사원이름', aggfunc='sum')
소속팀별 연도별매출 평균을 각 연도별로 확인해보자.
# 소속팀별 연도별매출 평균을 연도별(index)로 확인하기
company.pivot_table(values='연도별매출', columns='소속팀', index='연도')
📌 pivot_table 인자가 헷갈리면 이렇게!
"A별 BB의 CCC함수값을 DDDD인덱스로 확인하기"
1. A별 → columns
2. BB의 → values
3. CCC함수값을 → aggfunc
4. DDDD인덱스로 → index
그룹화 .groupby()
: 기준을 정하여 데이터를 그룹화하고, 각 그룹 단위로 연산을 수행하는 기능을 제공하는 메소드
진행 순서
- 그룹으로 나눌 열 또는 열들을 선택
- groupby() 함수에 그룹으로 나눌 열(label or list-like)을 전달.
- 예로 `df.groupby('업종')`은 '업종'열을 기준으로 데이터를 그룹화.
- 그룹 객체에 원하는 연산을 수행
- 그룹 객체를 생성되면 그룹 단위로 집계 함수로 연산을 수행.
- 예로 `df.groupby('업종').mean()`은 '업종'열을 기준으로 그룹화된 데이터 평균을 계산.
.groupby() vs .pivot_table()
- 그룹화를 하면 조건식처럼 하나씩 mask를 만들어 조회하지 않아도 된다.
- 코드와 데이터의 재사용성이 증가한다.
- 그룹별 통계를 낼 수 있게 되어, 집단들의 특징을 파악하기 쉬운 구조가 된다. (`numeric_only= ` 파라미터 사용 가능)
- .pivot_table()을 사용할 때보다 수행능력/편의성에 이득이 있다.
[예제]
원본 데이터가 아래와 같을 때
# 학생 성적 데이터 생성
data = {
'학생명': ['철수', '영희', '민수', '수현', '지영', '동희'],
'과목': ['수학', '영어', '수학', '과학', '영어', '과학'],
'성적': [90, 85, 92, 88, 95, 91]
}
df = pd.DataFrame(data)
df
# 과목별 평균 성적 계산 -> Series로 반환
subject_mean = df.groupby('과목')['성적'].mean()
subject_mean
1) 단일 열 그룹화
[예제]
원본 데이터가 아래와 같을 때
# Pokemon.csv - 포켓몬
pokemons = pd.read_csv('Pokemon.csv', index_col='#')
pokemons
type1_group = pokemons.groupby(by='Type 1')
type1_group
그룹화하면 {키 : 인덱스 객체}가 dict 형태로 반환된다.
# group화 된 상태 보기
type1_group.groups # {키 : 인덱스 객체}가 dict 형태로 묶여있음
그룹화한 것을 DataFrame 형태로 반환하려면 `.get_group()`을 사용하면 된다.
# .get_group(value) -> DataFrame으로 확인
# mask로 조건식 하는 것과 같은 출력 pokemons['Type 1'] == 'Dark'
type1_group.get_group('Dark').head()
그룹화된 데이터에 집계함수를 사용하고 싶다면 `numeric_only = `파라미터를 사용한다.
# pivot_table에는 numeric_only옵션이 없다.
# 따라서 경고를 안띄우려면 열 지정이나 메소드 실행 등 추가 데이터전처리가 필요하다.
# 하지만 group화된 데이터를 집계할 땐 numeric_only 옵션이 있다.
type1_group.mean(numeric_only=True)
특정 그룹에 대한 집계함수를 사용하려면 `.get_group()`으로 그룹을 선택하고 `numeric_only= ` 파라미터를 적용한다.
# 특정 그룹에 대한 집계 함수 수행
type1_group.get_group('Bug').mean(numeric_only=True)
2) 다중 열 그룹화
types = ['Type 1', 'Type 2']
types_groups = pokemons.groupby(by=['Type 1', 'Type 2'], dropna=False)
types_groups
# {키 : 인덱스 객체}의 dict로 반환된다.
# 키가 multi index처럼 튜플 형태로 묶여있다.
types_groups.groups
※ 그룹화되면 한 행의 각 열 데이터는 독립적이다! (SQL에도 적용되는 개념)
# "Bug-Electric 타입에서 제일 좋은 포켓몬을 찾아야지!" -> Joltik?
types_groups.max()
# 하지만 실제로 찾아보면 일치하지 않는다.(실제 : Joltik 472 70 77 60 97 60 108 5 False)
pokemons[pokemons['Name']=='Joltik']
► 각 열에서 그룹화된 열은 여러개의 데이터가 하나의 보따리에 들어간 상태이며, 보따리 안에서 max인 것을 반환한 것이기 때문
3) 그룹화 이후 집계함수 사용시(numeric)
# gropyby() 이후가 Dataframe은 아니지만 agg()를 사용할 수 있다.
pokemons.groupby('Type 1').agg({'Total' : ['max', 'min', 'mean'], 'HP' : ['max', 'min', 'mean', 'std']}).round(2)
4) 그룹화 이후 집계함수 사용시(object)
📌 `.agg()` 메소드에서 문자열(object dtypes)에 사용할 수 있는 키워드
- `unique` : 그룹 내에서 중복을 제거한 고유한 값을 반환
- `nunique` : 그룹 내에서 고유한 값의 개수를 반환
- `first` : 그룹 내에서 첫 번째 값을 반환
- `last` : 그룹 내에서 마지막 값을 반환
- `count` : 그룹 내에서 값의 개수를 반환
[예제]
원본 데이터가 아래와 같을 때
# 학생 성적 데이터 생성
data = {
'학생명': ['철수', '영희', '민수', '수현', '지영', '동희'],
'과목': ['수학', '영어', '수학', '과학', '영어', '과학'],
'성적': [90, 85, 92, 88, 95, 91]
}
df = pd.DataFrame(data)
df
# 그룹 내에서 중복 제거한 고유값만 반환
df.groupby('과목').agg({'성적' : 'max', '학생명' : 'unique'})