
회귀분석이란?
특정 변수가 다른 변수에 어떤 영향을 미치는지를 수학적 모형으로 설명&예측하는 기법
변수 종류
독립변수 = 설명변수 = 예측변수
영향을 주는 변수 (x)
종속변수 = 반응변수 = 결과변수
영향을 받는 변수 (y)
회귀 모형의 가정
- 선형성 : 독립변수와 종속변수가 선형적이어야 함
- 독립성 : 잔차와 독리변수의 값이 서로 독립적이어야 함
- 등분산성 : 잔차의 분산이 독립변수와 무관하게 일정해야 함
- 비상관성 : 관측치와 잔차는 서로 상관이 없어야 함
- 정상성(정규성) : 잔차항이 정규분포의 형태를 이뤄야 함
헷갈리는 용어
| 용어 | 설명 |
| 편차 | 관측치와 평균의 차이 |
| 오차 | 모집단에서 실젯값이 회귀선과 비교해볼 때 나타나는 차이 |
| 잔차 | 표본에서 나온 관측값과 회귀선과의 차이 |
회귀분석 유형
1. 단순선형 회귀 (Simple Linear Regression)
독립변수와 종속변수가 각각 1개씩으로 이뤄져 있으며 종속변수와의 관계가 선형임

회귀계수(회귀선)
- 독립변수가 주어질 때 종속변수의 기댓값
- '최소제곱법'으로 추정함
최소제곱법(최소자승법, Method of Least Squares)
잔차 제곱의 합이 최소가 되게 하는 직선을 찾는 방법

👉 최소제곱법 = RSS가 가장 작아지도록 회귀계수(β0, β1, …)를 선택하는 방법
👉 최소제곱법에 의해 추정된 회귀식은 x와 y의 평균을 지난다
Q. 회귀계수를 추정해야 하는 이유?
A. 회귀 방정식에서 β0(절편), β1(기울기, 회귀계수)는 모집단의 “진짜” 값이다.
하지만, 우리는 모집단 전체를 알 수 없고 표본 데이터만 가지고 있다.
그래서 실제로는 “진짜 계수”를 알 수 없고, 데이터를 이용해서 추정치(estimate)를 얻어야 한다.
👉 즉, 회귀계수를 추정한다는 건 데이터에 가장 잘 맞는 직선을 찾는 것이라고 이해하면 됨
단순 선형 회귀분석의 검정
회귀분석 결과가 적합한지 검증하는 과정
1) 회귀계수(β1)
- β1 = 0 → x와 y는 인과관계가 없음 (적합된 추정식이 의미가 없다)
2) 결정계수(
- 전체 데이터를 회귀모형이 얼마나 잘 설명하고 있는지를 보여주는 지표 (회귀선의 정확도)


3) 회귀직선의 적합도 검토
- 결정계수를 통해 추정된 회귀식이 얼마나 타당한지 검토
- 결정계수가 1에 가까울수록 회귀모형이 자료를 잘 설명함
- 독립변수가 종속변수 변동의 몇 퍼센트를 설명하는지 나타내는 지표
2. 다중선형 회귀
독립변수가 K개이며 종속변수와의 관계가 선형임
통계적 유의성
- 모집단에 대한 가설이 가지는 통계적 의미
👉 "통계적으로 유의하다" = 어떤 실험의 결과가 확률적으로 의미가 있다.
- F- 통계량으로 확인 (F = MSR / MSE)
👉 유의수준 5%하에서 F-통계량의 p-value < 0.05 → 귀무가설 기각 → 추정된 회귀식은 통계적으로 유의하다
다중 선형 회귀분석의 검정
1) 회귀계수의 유의성
- t-통계량으로 확인
2) 결정계수
3) 수정된 결정계수 (Adjusted R^2)
- 결정계수는 독립변수의 유의성과 관계없이 독립변수가 많아질수록 증가하는 성질이 있기 때문에 이를 보완하기 위해 다중 선형 회귀분석에서는 수정된 결정계수를 사용한다.
- 수정된 결정계수는 일반 결정계수보다 작게 계산되는 특징이 있음

- n : 표본 크기
- p : 독립변수 개수
4) 모형의 적합성
- 잔차와 종속변수의 산점도로 확인
5) 다중공선성
- 다중 회귀 분석에서는 설명변수들 사이에 선형관계가 존재하면 회귀 계수의 정확한 추정이 난해해기 때문에 다중공선성을 검사해야 함
- 다중 공선성 검사 방법 :
- 분산팽창 요인(VIF) : VIF > 4 → 다중공선성 존재, VIF > 10 → 심각한 문제
- 상태지수 : 상태지수 > 10 → 문제 있음, 상태지수 > 30 → 심각한 문제
3. 다항 회귀
독립변수와 종속변수와의 관계가 1차 함수 이상인 관계
(단, 독립변수가 1개일 경우는 2차 함수 이상)
4. 곡선 회귀
독립변수가 1개이며 종속 변수와의 관계가 곡선
5. 로지스틱 회귀
독립변수가 수치형이고 종속변수가 범주형(2진 변수)인 경우 적용되는 모형
👉 즉, 확률을 예측해서 그 확률이 기준(임곗값, 보통 0.5)보다 크면 “1”, 아니면 “0”으로 분류하는 방법
- 사용 목적 : 새로운 독립변수 값이 주어질 때, 종속변수의 각 범주에 속할 확률이 얼마인지를 추정하여 추정 확률을 기준치에 따라 분류하기 위함
- 사후확률(Posterior Probability) : 모형의 적합을 통해 추정된 확률
오즈 (Odds)
사건이 일어날 확률 대 일어나지 않을 확률의 비 (0~∞)

로짓 (Logit)
오즈에 로그를 취한 값 (–∞~∞)

시그모이드 함수(Sigmoid Function)
로짓을 다시 확률 p로 되돌리는 함수 (0~1)
6. 비선형 회귀
회귀식의 모양이 미지의 모수들의 선형관계로 이뤄져 있지 않은 모형
최적 회귀방정식의 선택
모든 가능한 독립변수들의 조합에 대한 회귀 모형을 생성한 뒤 가장 적합한 회귀 모형을 선택한다
변수 선택 방법
| 유형 | 설명 |
| 전진 선택법 (Forward Selection) |
β0(절편)만 있는 상수모형부터 시작해서, 중요하다고 생각되는 설명변수(x)를 차례로 모형에 추가하는 방식 |
| 후진 소거법 (Backward Elimination) |
- 독립변수 후보를 전부 포함한 모형에서 시작해 제곱합의 기준으로 가장 적은 영향ㅇ르 주는 변수부터 하나씩 제거하는 방식 - 더 이상 유의하지 않은 변수가 없을 때 까지 제거 |
| 단계적 방법 (Stepwise Method) |
변수를 추가하면서 추가된 변수때문에 기존 변수의 중요도가 약화되면 해당 변수를 제거하거나, 제거되는 변수의 여부를 검토해 더 이상 없을 때 중단하는 방법 |
벌점화된 선택 기준
모형의 복잡도에 패널티를 주는 방법
AIC (Akaike Information Criterion)
실제 데이터의 분포와 모형이 예측하는 분포 사이의 차이를 나타내는 방법
- 낮은 AIC 값 = 모형의 적합도가 높음(=좋은 모델)
- 단점 : 표본이 커질수록 부정확함

- L : 모델의 최대우도(모델이 데이터를 설명하는 정도)
- k : 모델에 포함된 파라미터 수
- 의미:
- 첫 번째 항 −2ln(L) : 모델이 데이터를 얼마나 잘 설명하는지(적합도)
- 두 번째 항 2k : 파라미터가 많아질수록 패널티 → 과적합 방지
BIC (Bayesian Information Criterion)
표본 크기까지 고려해서 더 강하게 패널티를 주는 지표
- 낮은 BIC 값 = 좋은 모델
- 표본의 크기가 커질수록 복잡한 모형(=불필요한 변수가 있는 모형)에 더 강한 패널티를 부여하기 때문에 진짜 좋은 모델을 고를 수 있음
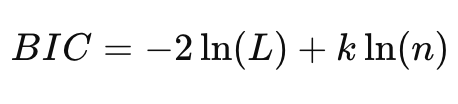
- n : 표본 크기
- k ln(n) : 포본 크기가 클수록 변수 추가에 더 큰 불이익을 줌
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사 필기] 3-2. (1) 인공신경망(Artificial Neural Network; ANN)_지도학습/분류, 비지도학습 (0) | 2025.09.05 |
|---|---|
| [빅데이터분석기사 필기] 3-2. (1) 의사결정 나무 (Deicision Tree)_지도학습/분류&예측 (0) | 2025.09.05 |
| [빅데이터분석기사 필기] 3-2. (1) 분석기법 개요 (0) | 2025.09.04 |
| [확률통계론] 이산확률분포(Discrete Probability Distribution) (0) | 2025.08.31 |
| [확률통계론] 체비셰프(Chebyshev) 정리 (0) | 2025.08.30 |