
Snowflake
클라우드 기반의 데이터 웨어하우스로 시작되었으며 현재는 데이터 클라우드 수준
Snowflake 특징
- 멀티 클라우드 : AWS, GCP, Azure와 같은 글로벌 클라우드 위에서 모두 동작함
- Data Sharing(=Share, Don't Move) : 데이터 셋을 사내 혹은 파트너에게 스토리지 레벨에서 공유하는 방식
- Data Marketplace : 데이터 판매를 통한 매출을 가능하게 해줌
- ETL과 다양한 데이터 통합 기능 제공
- 가변 비용 모델 : 스토리지와 컴퓨팅 인프라가 별도로 설정됨(=내가 사용한 만큼 비용 지불)
- Redshift 고정 비용처럼 노드 수를 조정할 필요 X
- distkey 등 최적화 필요 X
- SQL 기반 빅데이터 저장/처리/분석 가능
- 비구조화된 데이터 처리, 머신러닝 기능 제공
- 다양한 데이터 포맷 지원 : CSV, JSON, Avro, Parquet 등
- 배치 데이터 중심 + 실시간 데이터 처리 지원
- Time Travel : 과거 데이터 쿼리 기능으로 트렌드 분석이 용이
- 웹 콘솔 + Python API를 통한 관리/제어 가능
- 자체 스토리지 이외 클라우드 스토리지를 외부 테이블로 사용 가능
- Cross-Region Replication : 다른 지역에 있는 데이터 공유기능 지원
- 대표 고객 : Siemens, Flexport, Iterable, Affirm, PepsiCo 등
Snowflake의 계정 구성도
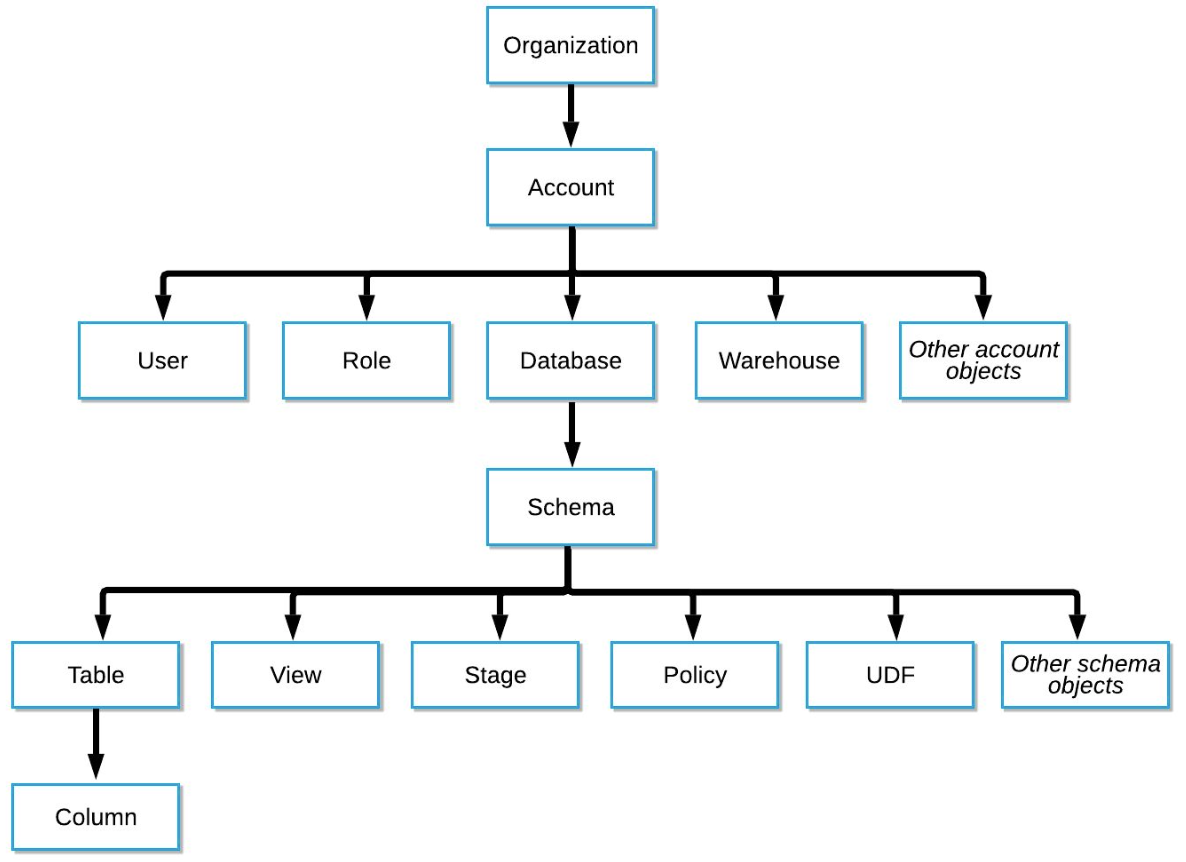
Organization → 1 + Account → 1 + Databases (→ Schemas → Tables)
- 기업의 규모에 따라 달라짐
- 대기업의 경우 : Organization부터 시작
- 중소기업의 경우 : Account부터 시작
Organizations
- 한 고객이 사용하는 모든 Snowflake 자원들을 통합하는 최상위 레벨 컨테이너
- 하나 혹은 그 이상의 Account들로 구성되며 이 모든 Account들의 접근권한, 사용트래킹, 비용들을 관리하는데 사용됨
Accounts
- 하나의 Account는 자체 사용자, 데이터, 접근권한을 독립적으로 가짐
- 한 Account는 하나 혹은 그 이상의 Database로 구성됨
Databases
- 하나의 Database는 한 Account에 속한 데이터를 다루는 논리적인 컨테이너
- 한 Database는 다수의 스키마와 거기에 속한 테이블과 뷰등으로 구성되어 있음
하나의 Database는 PB단위까지 스케일 가능하고 독립적인 컴퓨팅 리소스를 갖게 됨 - 컴퓨팅 리소스를 Warehouses라고 부름. Warehouses와 Databases는 일대일 관계가 아님
가변비용 데이터 웨어하우스는 스토리지와 컴퓨팅 리소스가 분리되어있음
Snowflake의 경우 컴퓨팅 리소스를 데이터 웨어하우스, 스토리지를 데이터베이스라고 부름
Snowflake 구조
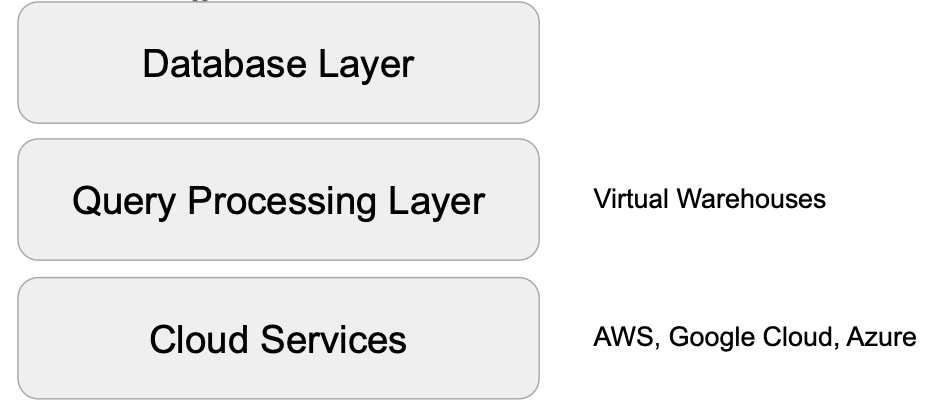
- 맨 밑층 : Cloud Services (ex. AWS, Google Cloud, Azure)
- 2층 : Query Processing Layer (가상 웨어하우스)
- 3층 : Database Layer
Snowflake 30일 무료 시험판 시작하기
Snowflake Trial
signup.snowflake.com
※ 유의사항
- 30일 동안 $400까지 사용 가능
- 30일이 지나면 자동으로 정지됨
- 추가로 더 사용하고 싶다면 신용카드 정보 입력
1단계. 계정 생성하기
각자의 개인 정보를 입력하자.
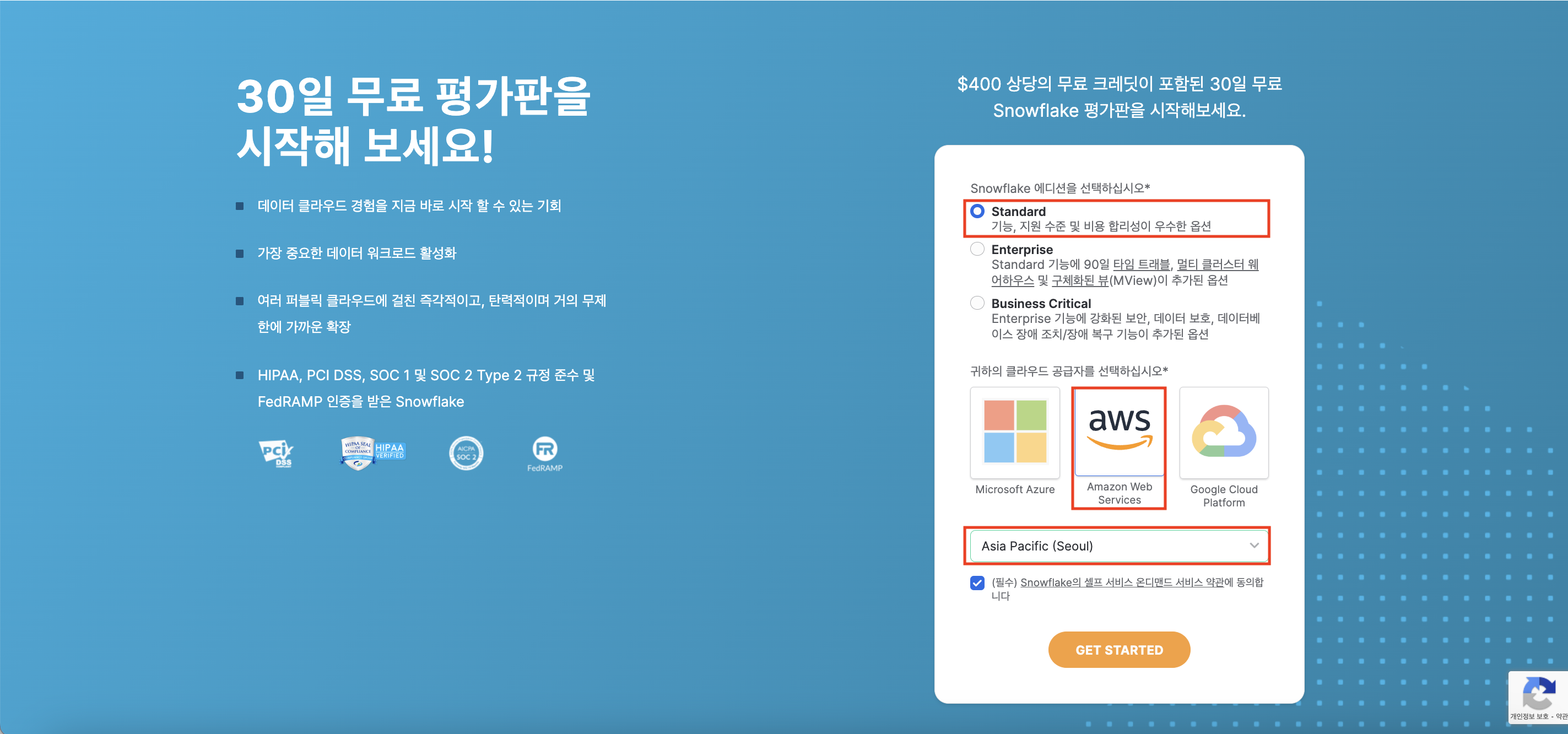
에디션과 클라우드 공급자(Snowflake는 모든 클라우드 위에서 동작), 국가를 설정하자.
필자는
- 에디션 : Standard
- 클라우드 공급자 : AWS
- 국가 : Asia Pacific(Seoul)
로 각각 설정해줬다.
등록 완료!
이제 본인이 입력한 이메일 수신함으로 가서 접속 전용 URL을 확인해보자.
※ 계정 생성 이후에는 Snowflake 공식 홈페이지에 접속해서 사용하는 것이 아니라,
등록된 이메일에서 별도로 수신받은 로그인 URL에 접속해서 사용 해야 한다.
그러므로 전용 URL 주소를 꼭 북마크 해둘것!
2단계. Username(ID) 및 Password 설정
Snowflake에서 사용할 ID와 비밀번호를 각각 설정해주자.
※ 비밀번호는 8~256자 사이이며, 특수문자 불가, 대문자와 소문자, 숫자가 각각 1개 이상씩 포함되어 있어야 한다.
3단계. Worksheets 살펴보기
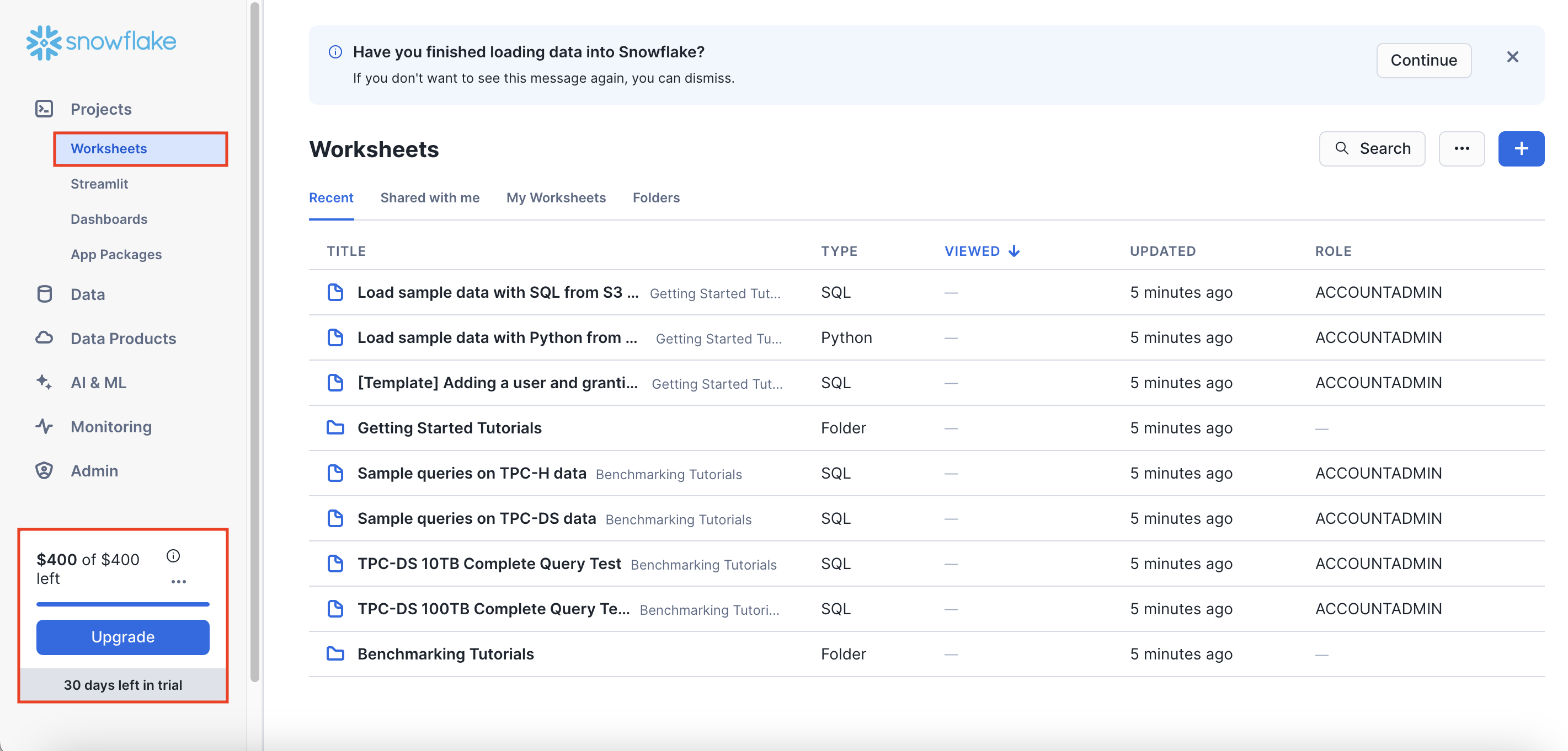
계정을 생성하게 되면 아래와 같은 화면이 가장 먼저 보이게 된다.
Worksheets 페이지는 Jupyter Notebook과 같은 일종의 노트북 개념이라고 생각하면 된다.
왼쪽 하단에는 본인의 무료 체험판 계정이 몇일 남았는지 보여준다.
4단계. Database 만들어보기
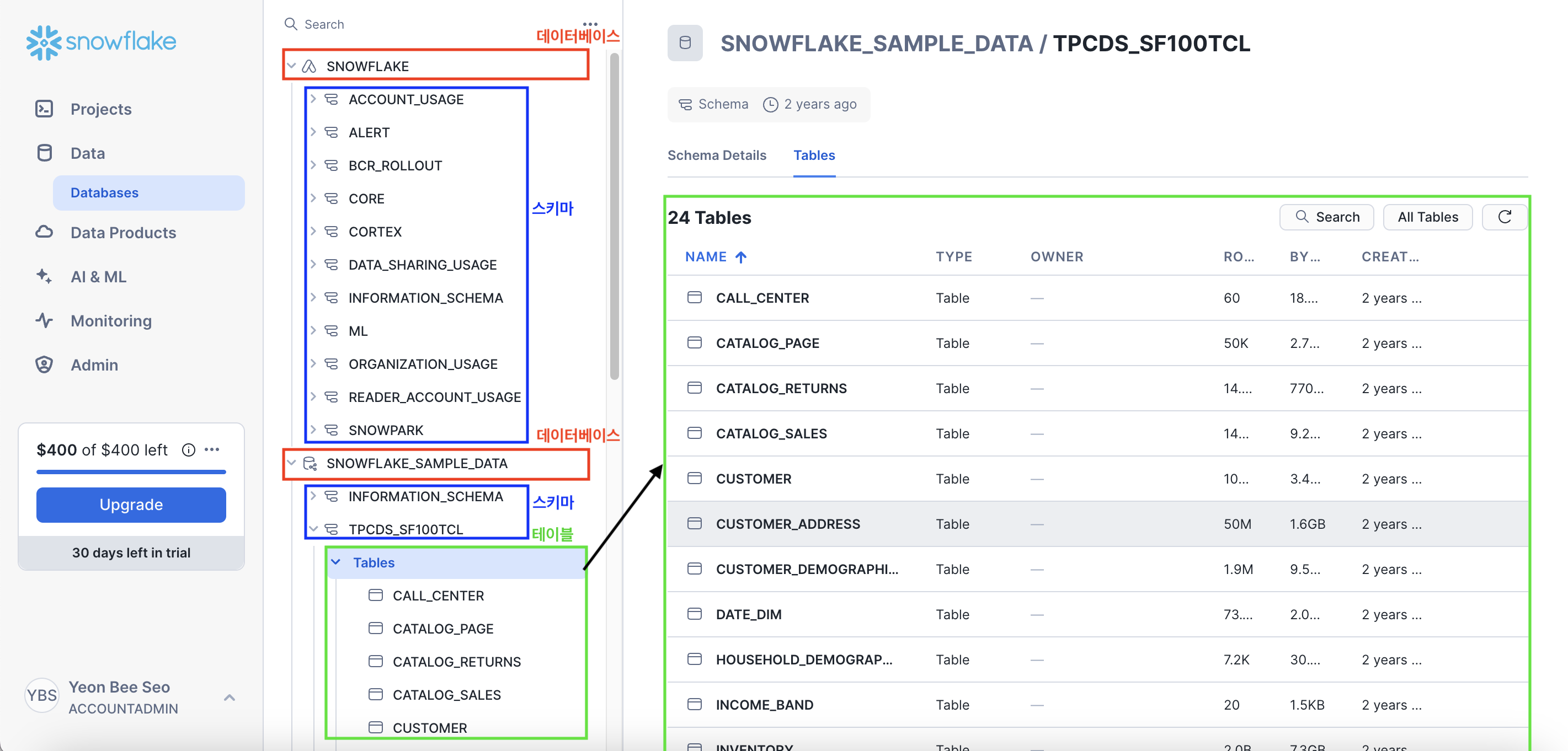
왼쪽 메뉴에서 [Data] - [Databases]를 클릭해보자.
기본적으로 2개의 데이터베이스가 존재한다.
전체적인 구조는 아래와 같다.
- 가장 상단의 토글이 '데이터베이스(Database)'
- 그 밑에 하위 토글이 '스키마(Schema)'
- 그 밑에 하위 토글이 '테이블(Table)'
5단계. Warehouses 살펴보기
왼쪽 메뉴에서 [Admin] - [Warehouses]를 클릭해보자.
기본적으로 'COMPUTE_WH' 라는 1개의 웨어하우스가 제공된다.
- 데이터베이스들이 갖고 있는 데이터 = 스토리지
- 스토리지에 있는 데이터를 프로세싱 해주는 컴퓨팅 리소스 = 데이터 웨어하우스
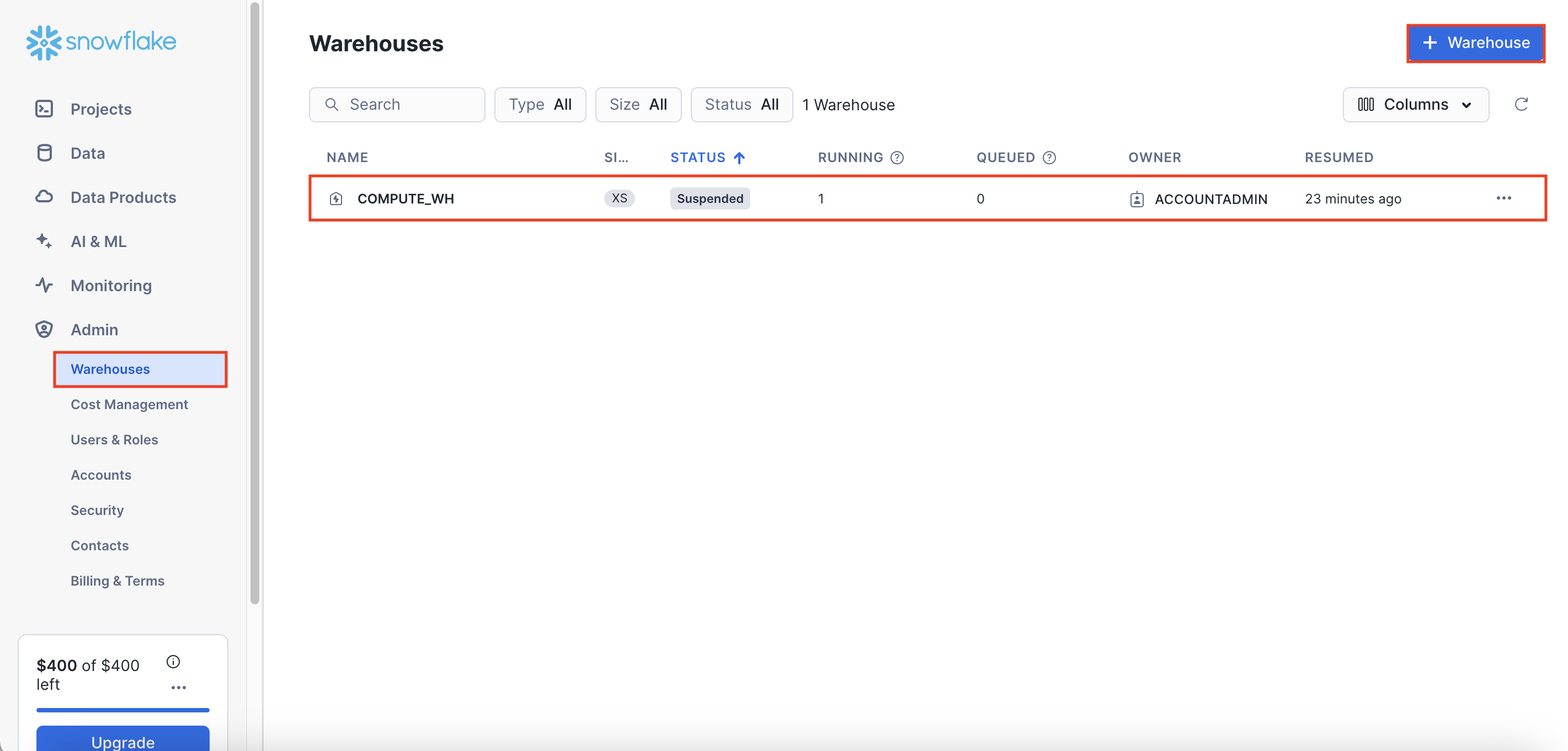
새로운 웨어하우스를 생성하고 싶다면 오른쪽 상단에 [+ Warehouse] 버튼을 클릭하면 된다.
먼저 [Warehouse Name]에 웨어하우스의 이름을 지정해주고,
본인이 하고 있는 업무의 성격에 따라서 [Type]과 [Size]를 지정해주면 된다.
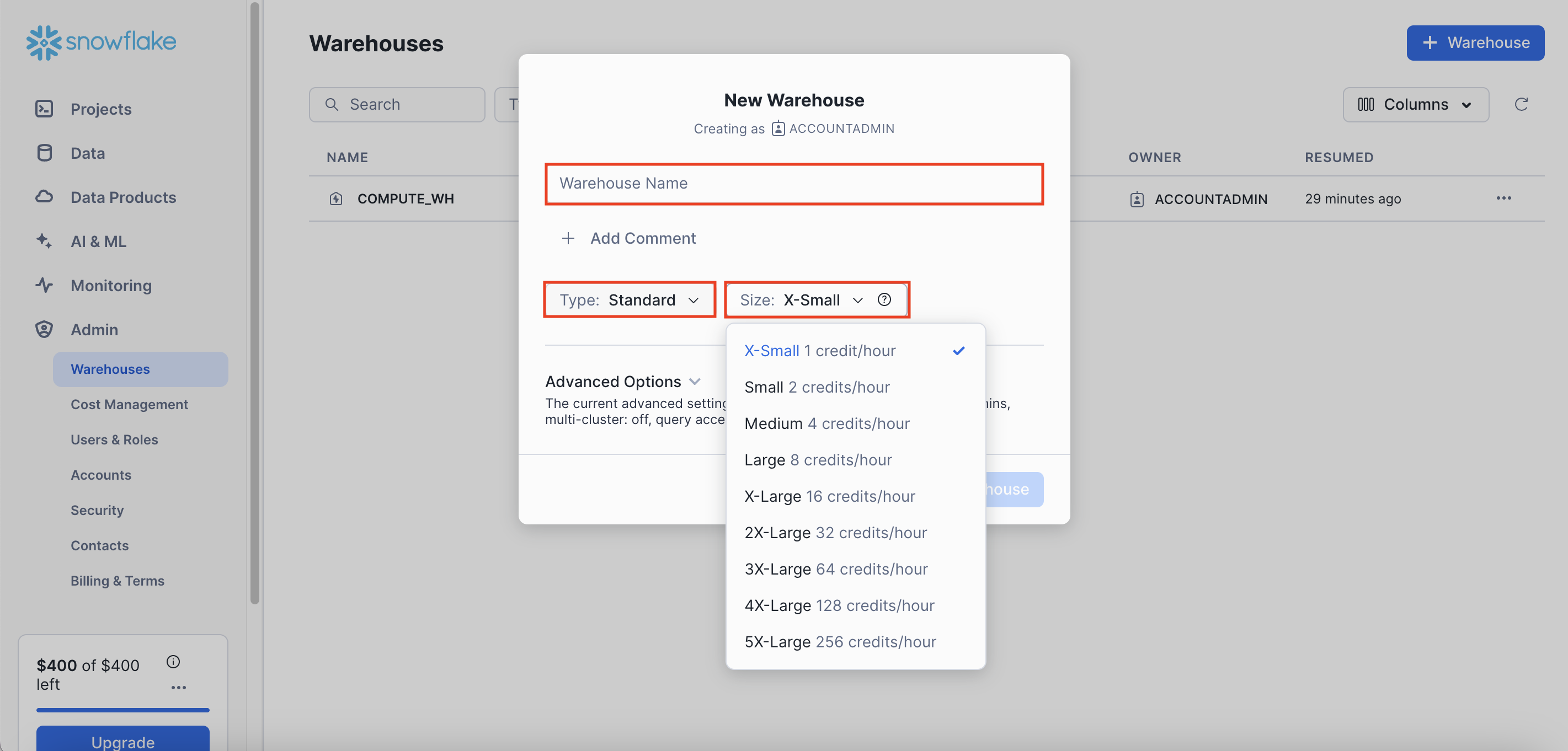
📌 Credit
각 사이즈마다 오른쪽에 써져있는 [credit/hour]에서 credit의 의미는 무엇일까?
► computing power을 의미한다.
즉, 쿼리 실행과 데이터 로드, 기타 작업 수행에 소비되는 계산 리소스를 측정하는 단위이다.
(1 credit는 상황에 따라 다르지만 대략 $2-$4의 비용을 발생시킴)
📌 Snowflake의 비용 구조
- 컴퓨팅 비용 : 앞서 크레딧으로 결정됨
- 스토리지 비용 : TB 당으로 계산
- 네트워크 비용 : 지역간 데이터 전송 혹은 다른 클라우드간 데이터 전송시 TB 당 계산
Snowflake 실습을 위한 초기 환경 설정
📌 실습 목표
1. Setup-Env라는 이름의 새로운 SQL Worksheet 생성
2. dev라는 이름의 데이터베이스 생성
3. dev밑에 raw_data, analytics, adhoc라는 이름의 3개의 스키마를 생성
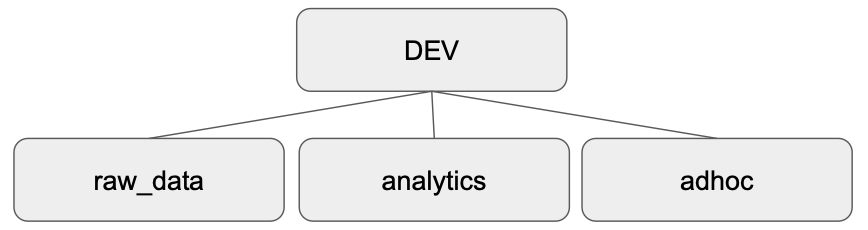
- `raw_data` : ETL로 읽어온 테이블들이 들어가는 스키마
- `analytics` : 이미 데이터웨어하우스 안에 들어온 테이블들을 바탕으로 ELT로 새로운 테이블을 만드는 경우 들어가는 스키마(CTAS 사용)
- `adhoc` : 개발용 혹은 테스트용으로 테이블을 잠깐 만들때 사용하는 스키마
4. raw_data 스키마 밑에 user_session_channel, session_timestamp, session_transaction라는 이름의 테이블 3개 생성
5. 각 3개의 테이블에 값 넣기
6. analytics 스키마 밑에 분석에 활용할 mau_summary라는 이름의 새로운 테이블 생성
1단계. 새로운 SQL Worksheets 생성하기
왼쪽 메뉴에서 [Projects] - [Worksheets]를 클릭해보자.
새로운 워크시트를 생성하기 위해 오른쪽 상단의 [+] - [SQL Worksheet]를 선택한다.
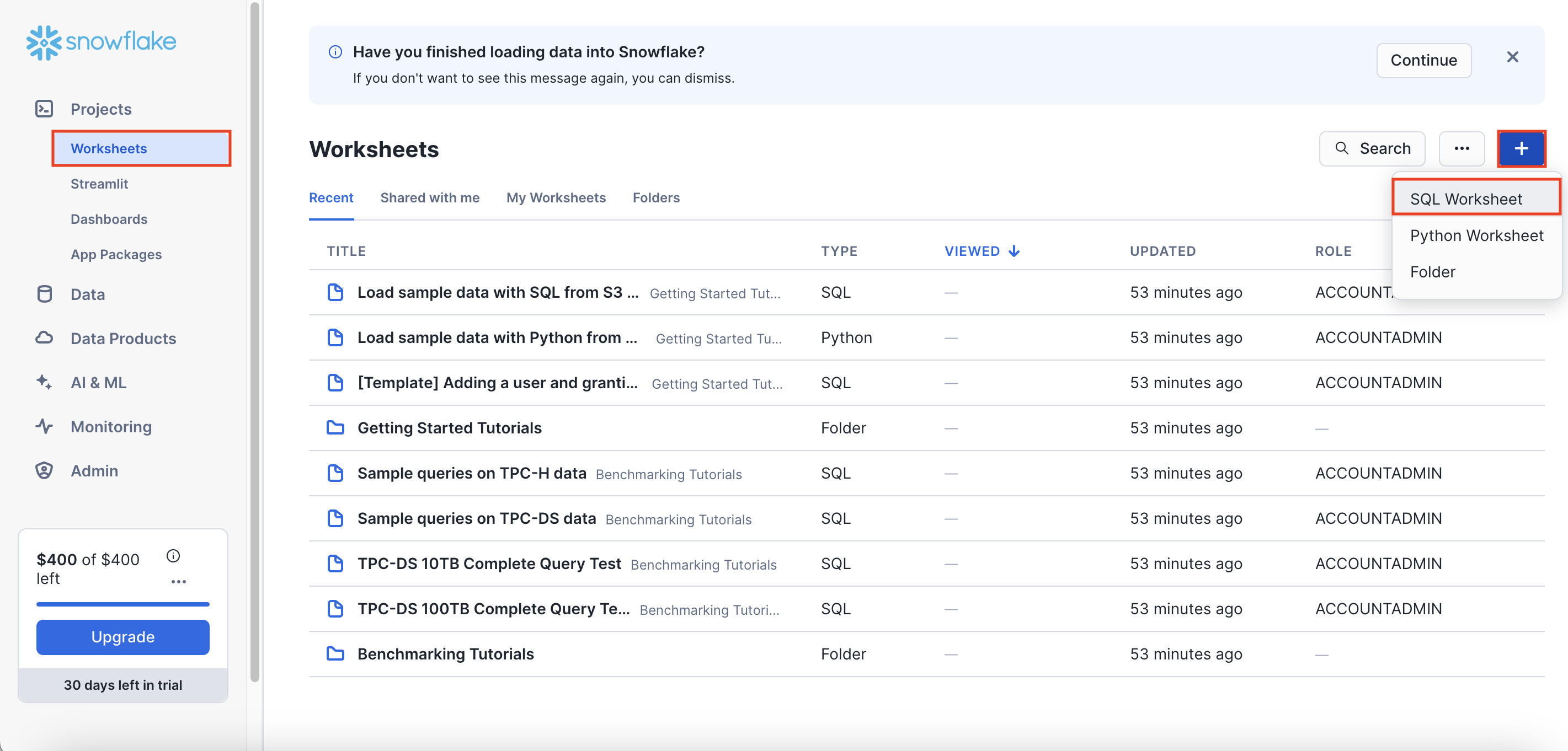
생성 직후에는 아래 스크린샷처럼 생성 시간으로 워크시트 이름이 자동으로 정해진다.
[...] - [Rename] 버튼을 눌러 원하는 이름으로 리네이밍 해준다.
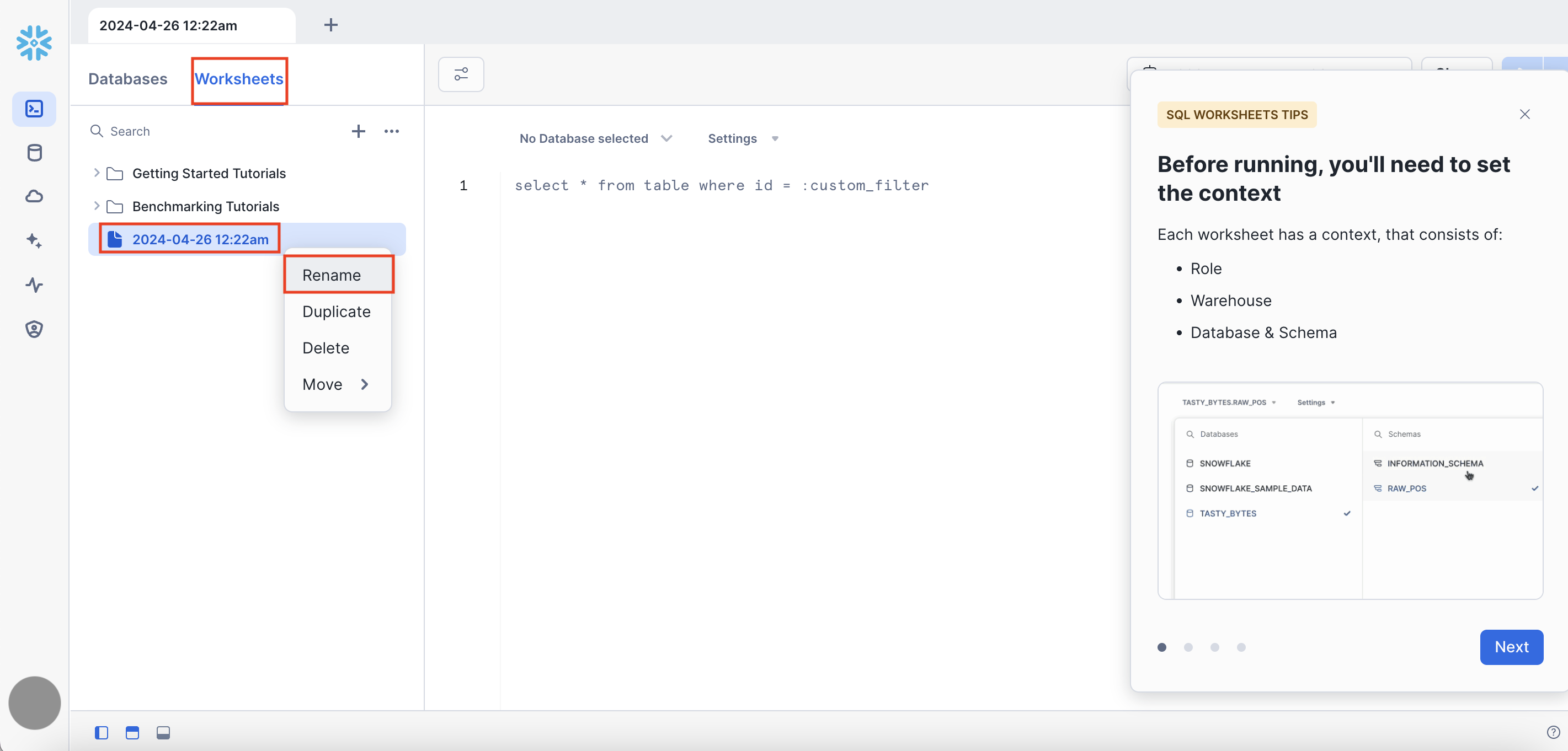
오른쪽 상단에 여러 버튼들이 있는데
- `ACCOUNTADMIN` : 현재의 역할(필자는 현재 ACCOUNTADMIN 권한)
- `COMPUTE_WH` : 사용중인 컴퓨팅 리소스(필자는 현재 COMPUTE_WH 이름의 데이터 웨어하우스를 사용중)
- `Share` : 작업중인 워크시트를 Snowflake 내 다른 사용자들과 공유
- `►` : 쿼리를 입력할 경우 실행 버튼(▿ 버튼을 누르면 커서가 있는곳만 실행할 것인지/전체를 실행할 것인지 등을 선택할 수 있음)
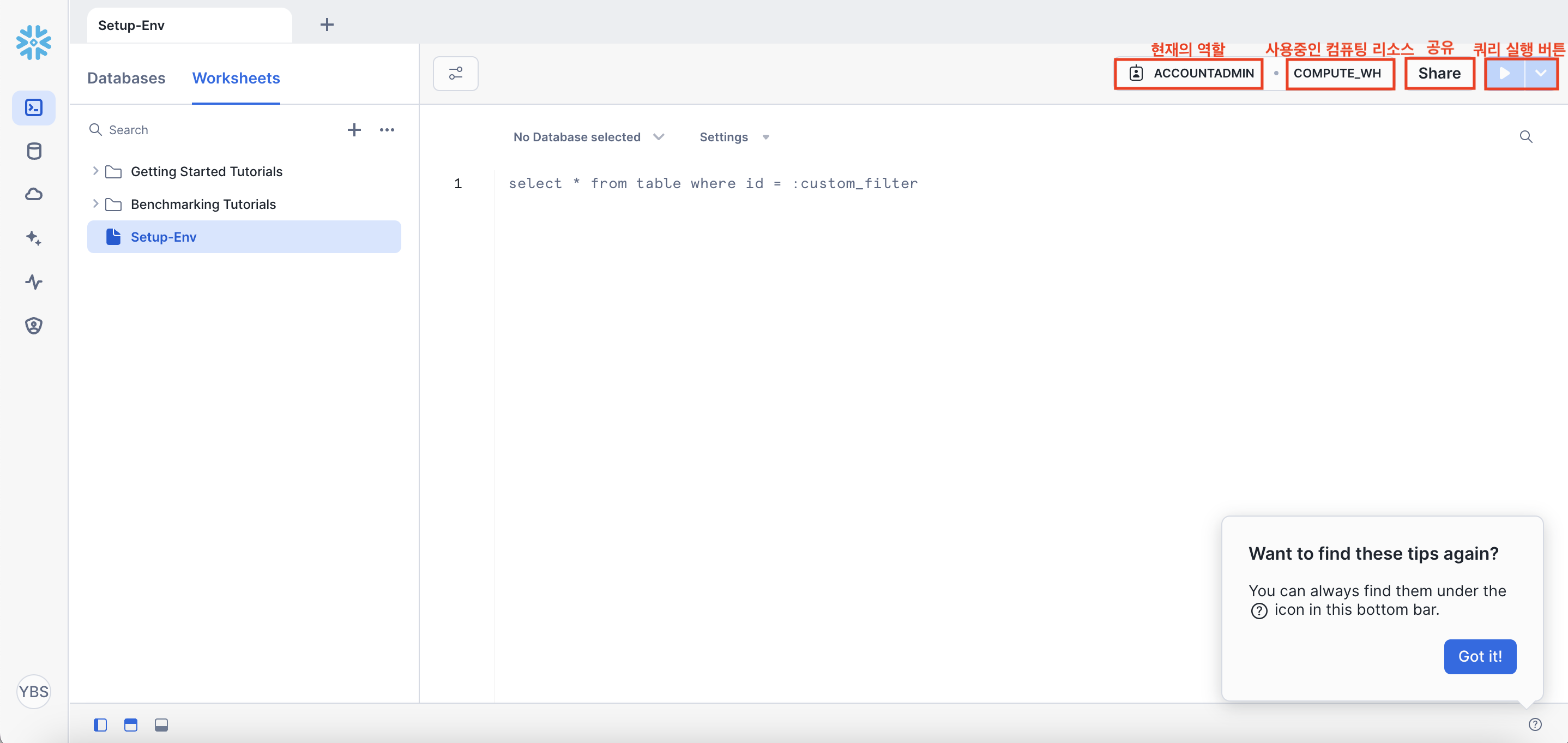
- `No Database selected` : 앞으로 실행할 해당 SQL Worksheet가 어떤 Database 밑에 있는 Table을 대상으로 하는 것인지 선택
(선택을 안한 경우 : 사용자가 Table을 지정할 때 Database부터 시작해서 Schema, Table까지 하나하나 지정해줘야 함)
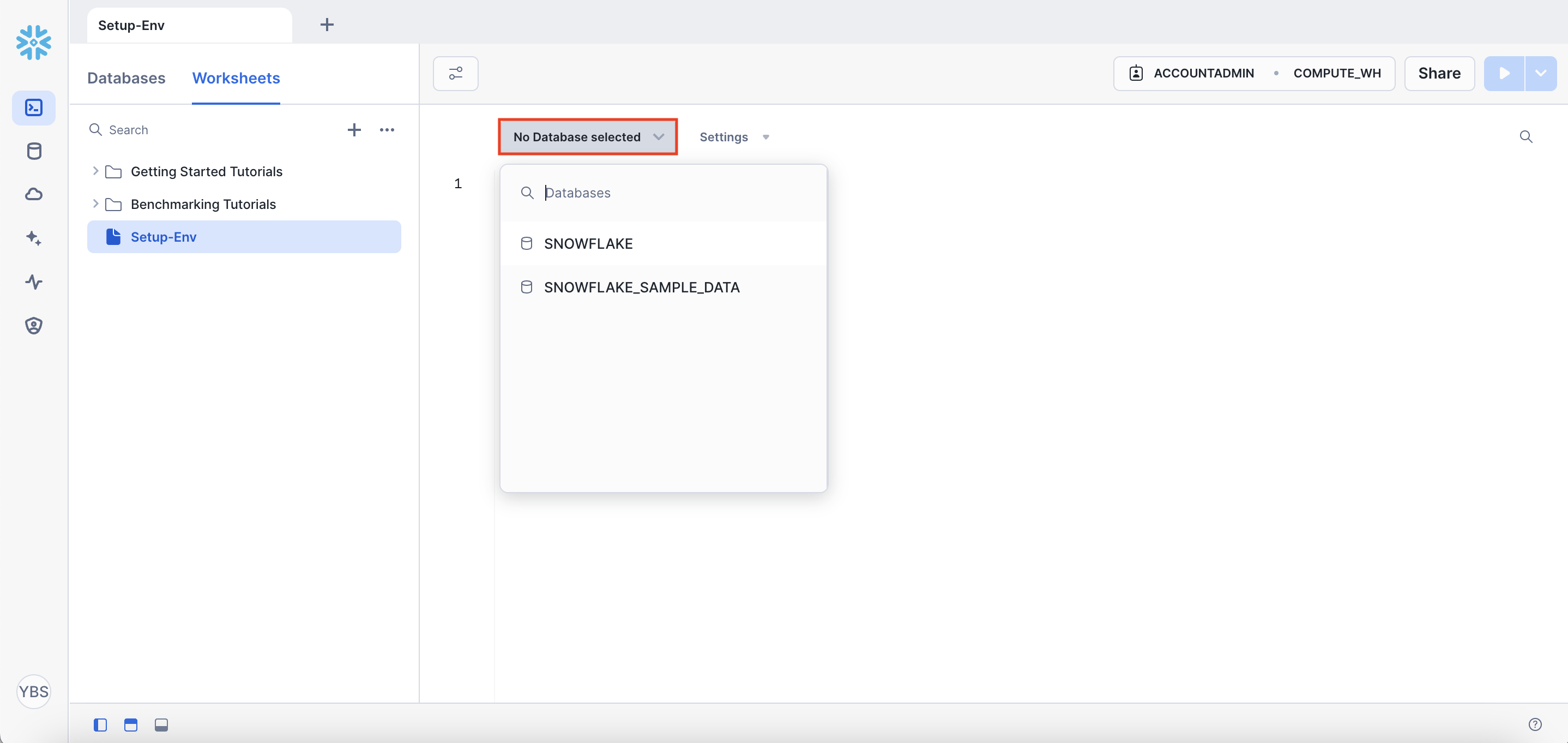
2단계. 데이터베이스와 스키마 생성
데이터베이스와 스키마를 생성하는 명령어는 아래와 같다.
CREATE DATABASE dev;
-- 먼저 3개의 스키마를 생성한다
CREATE SCHEMA dev.raw_data;
CREATE SCHEMA dev.analytics;
CREATE SCHEMA dev.adhoc;
만약 위에서 `No Database selected`에 DEV라는 데이터베이스를 선택해주었다면
쿼리에서 `dev.raw_data` 대신 `raw_data`로 바꿔주면 된다. (`dev.analytics`, `dev.adhoc`도 마찬가지)
Snowflake 에디터로 가서, 왼쪽 상단의 [Projects] - [Worksheets]를 눌러보자.
1단계에서 만들었던 새로운 워크시트인 'Set-Env'를 클릭해서 위의 명령어들을 복사 붙여넣기 한다.
오른쪽 상단의 실행 버튼(►)을 눌러준다.

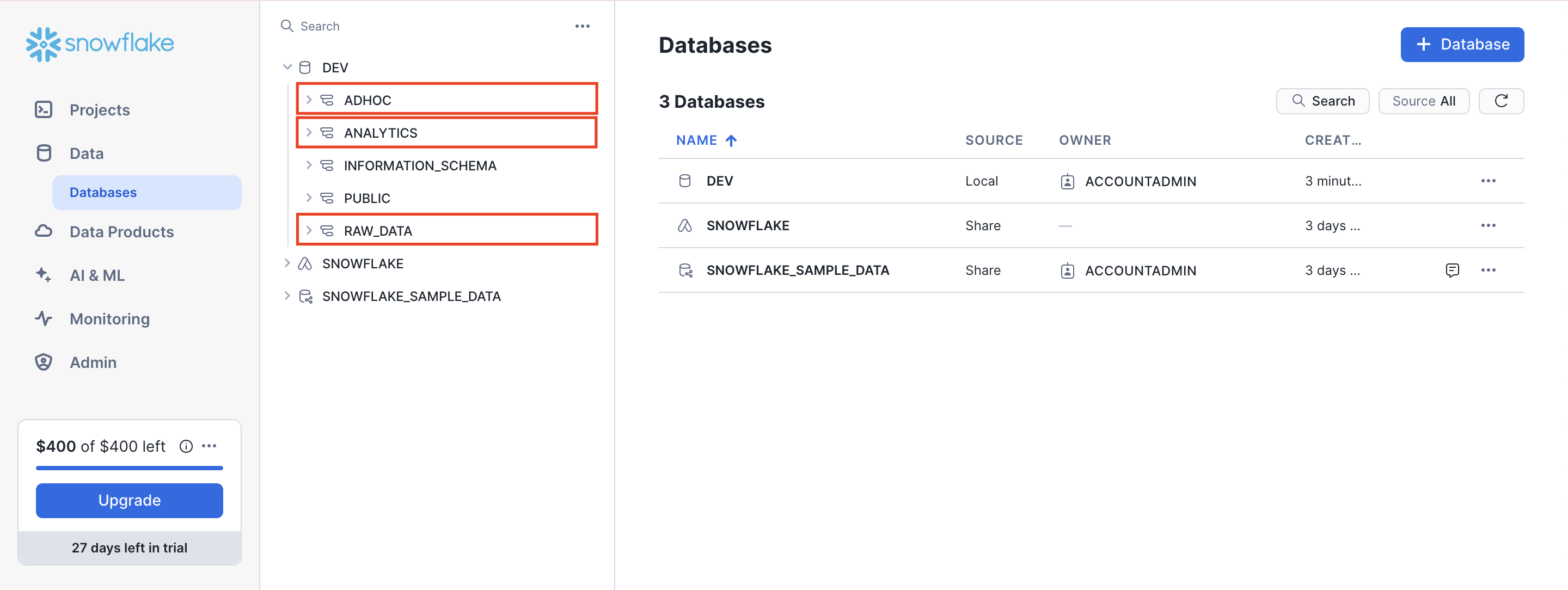
왼쪽상단 메뉴에 [Data] - [Databases]로 들어가 확인해보자.
아래와 같이 DEV라는 데이터베이스 밑에 ADHOC, ANALYTICS, RAW_DATA 스키마 3개가 만들어진 것을 확인할 수 있다.
3단계. AWS Console S3 버킷 생성 후 csv 파일 업로드
AWS Console에 로그인해서 에서 S3를 검색 후 클릭하자.
[버킷 만들기] 클릭
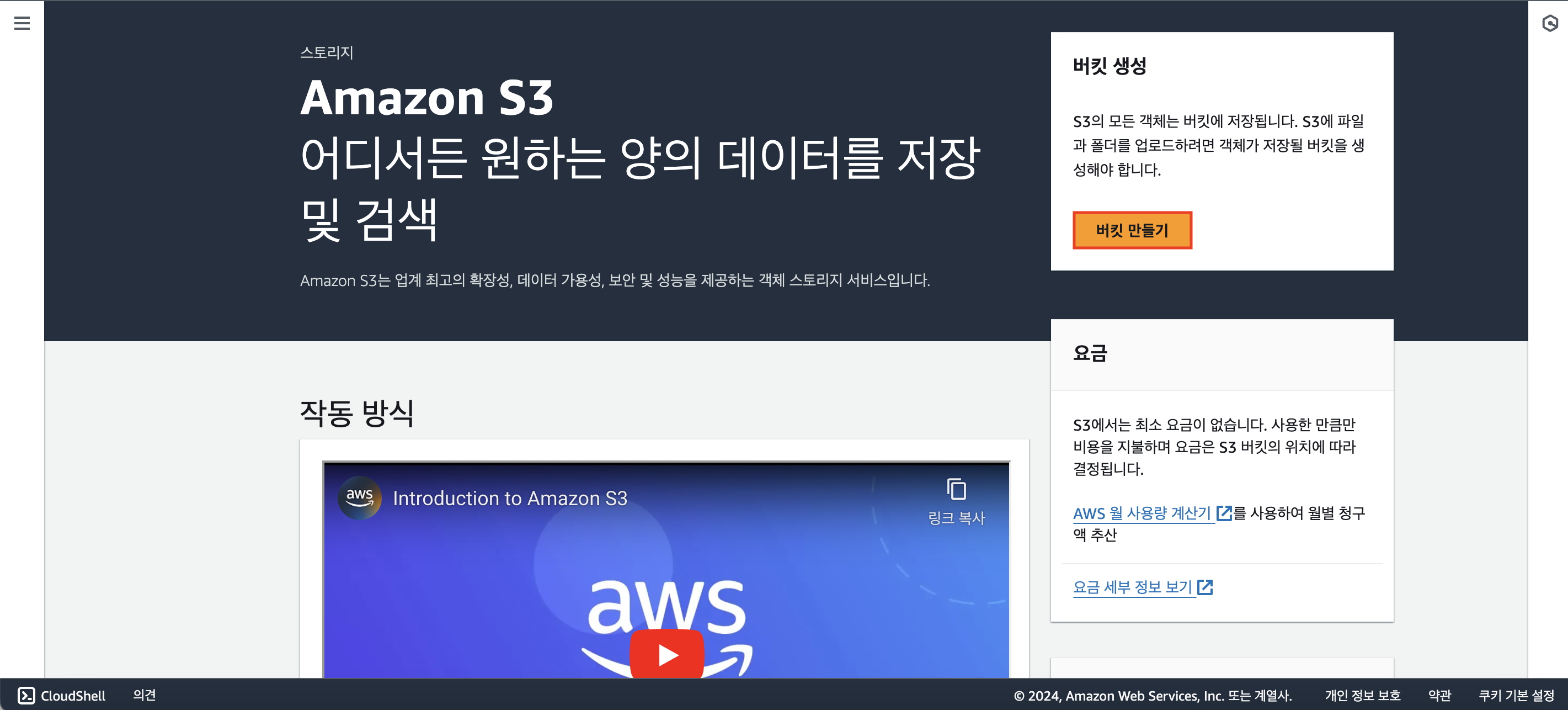
[버킷 이름]을 설정해주자.
[AWS 리전]은 Snowflake 만들 때 지정했던 지역과 동일하게 되어있으면 된다.
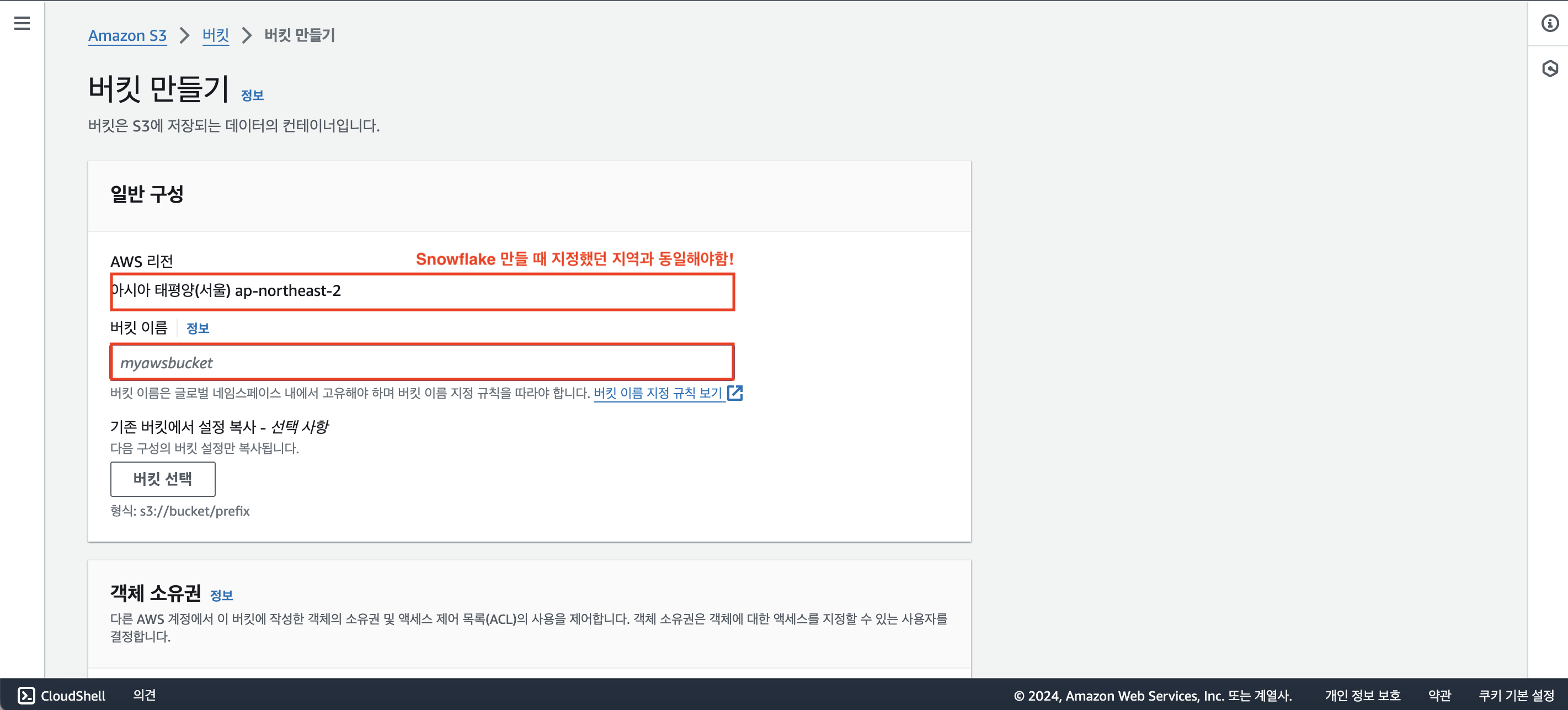
나머지 옵션들은 기본적으로 지정된 것으로 유지해서 진행하면 된다. 전부 체크된 것 확인했다면 [버킷 만들기] 클릭!
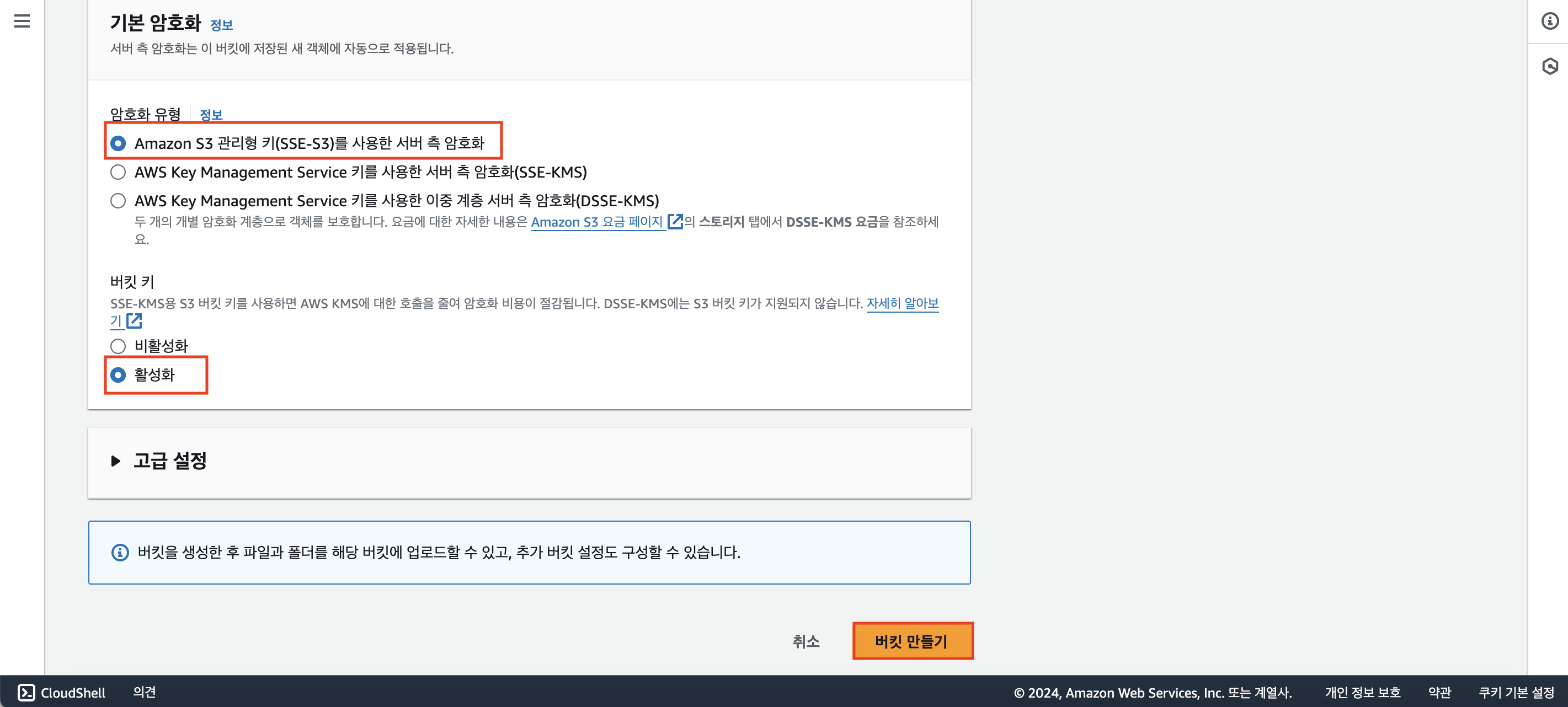
버킷이 잘 생성되었다면 아래와 같은 화면이 뜰 것이다.
버킷 이름을 클릭해보자
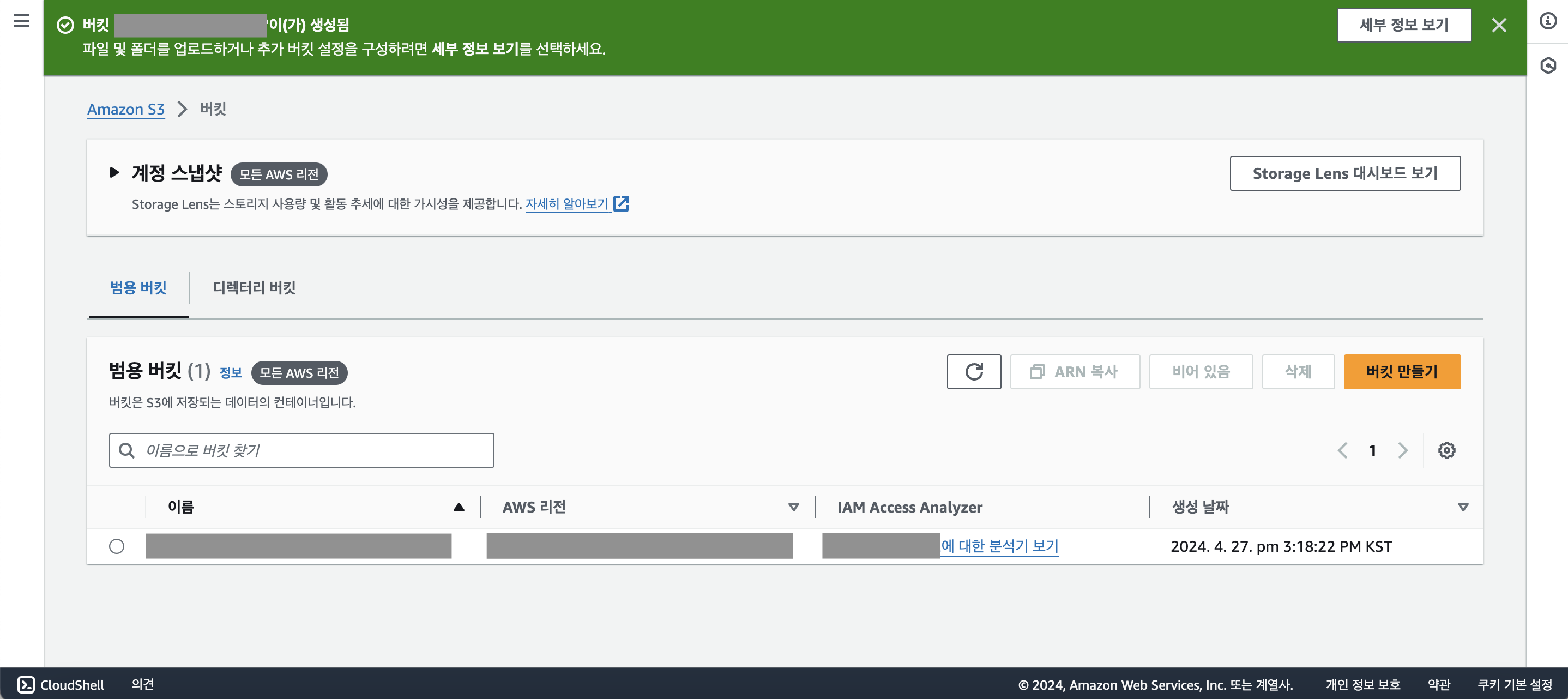
이제 막 생성된 버킷이기 때문에 어떠한 객체도 없음을 확인할 수 있다.
오른쪽 상단에 [폴더 만들기]를 클릭하자.
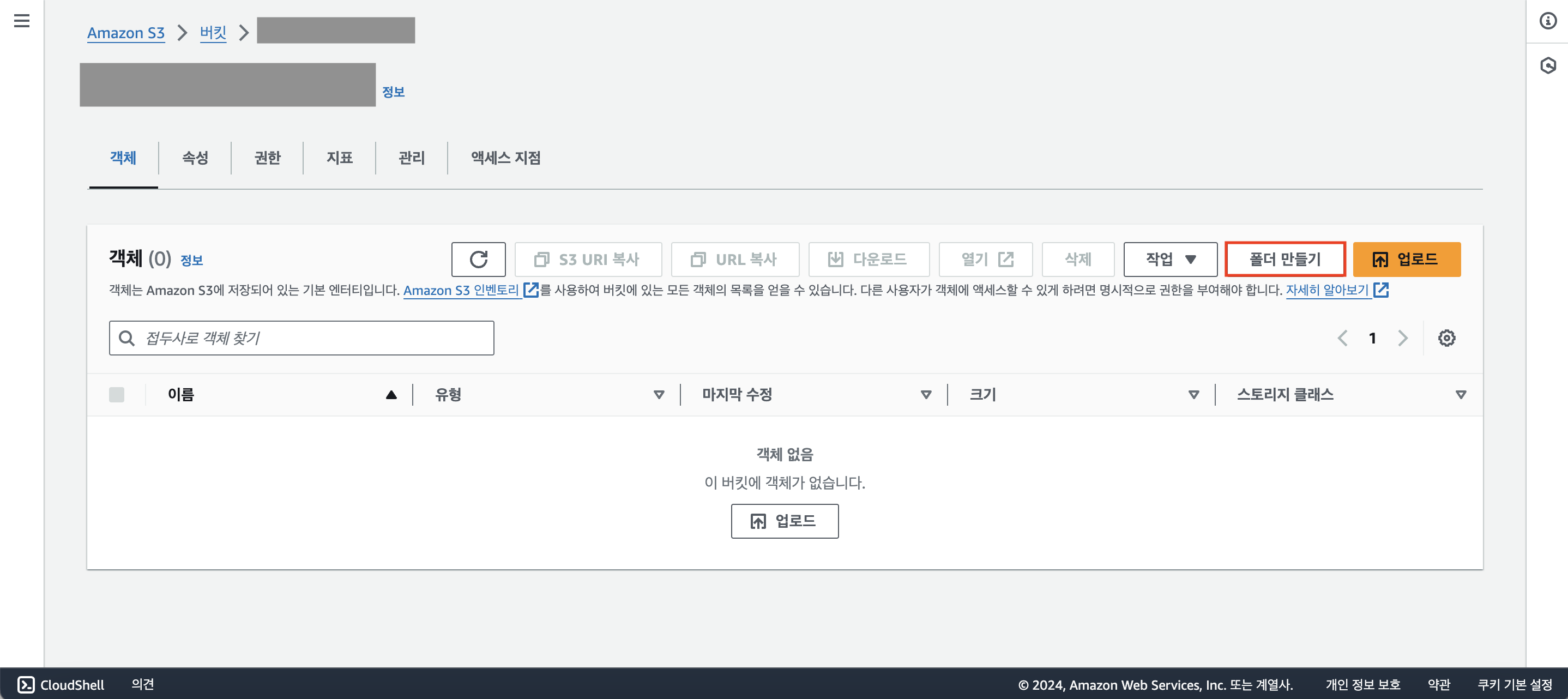
'test_data'라고 새로운 폴더의 이름을 지정해준 후, [폴더 만들기]를 눌러 폴더를 생성하자.

test_data 폴더가 정상적으로 생성된 것을 확인할 수 있다.
test_data 폴더를 클릭해보자.
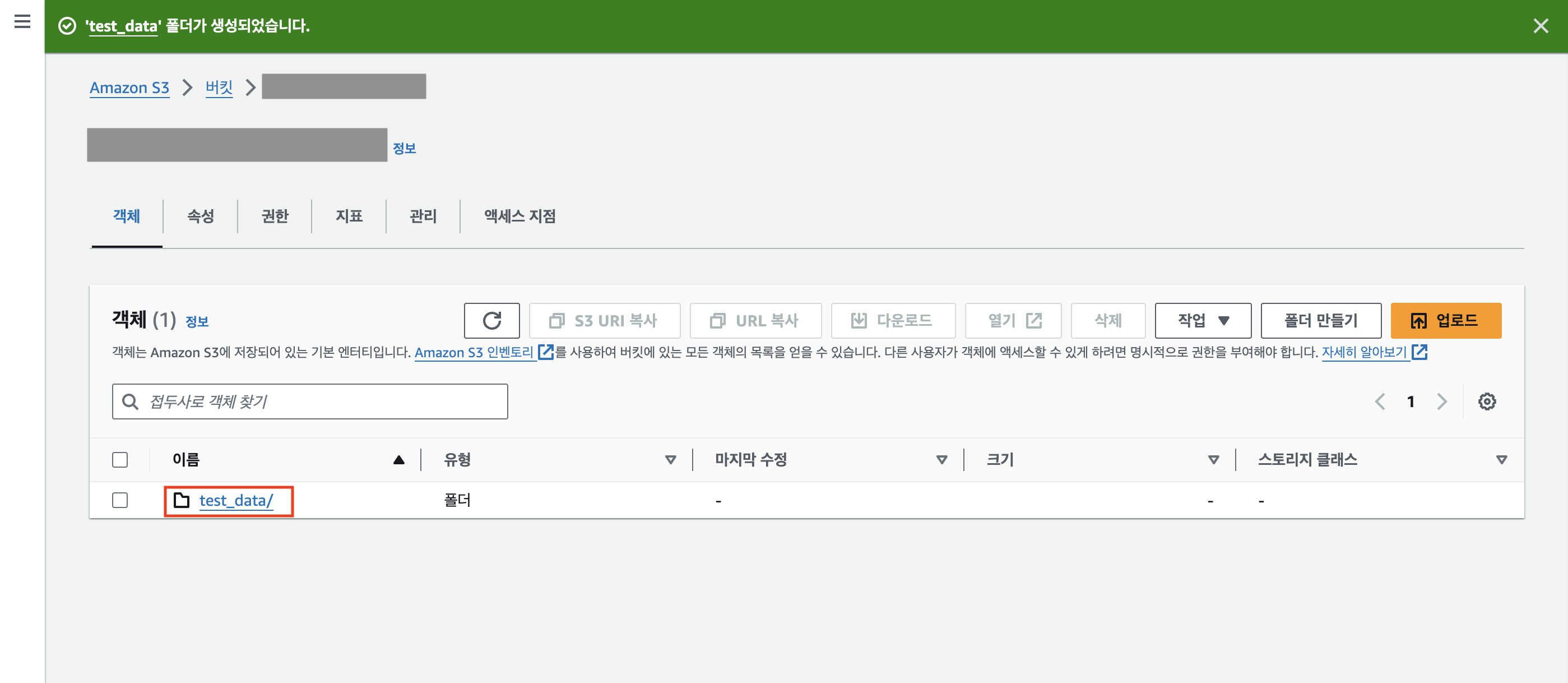
오른쪽 상단에 [업로드] 버튼을 클릭한다.
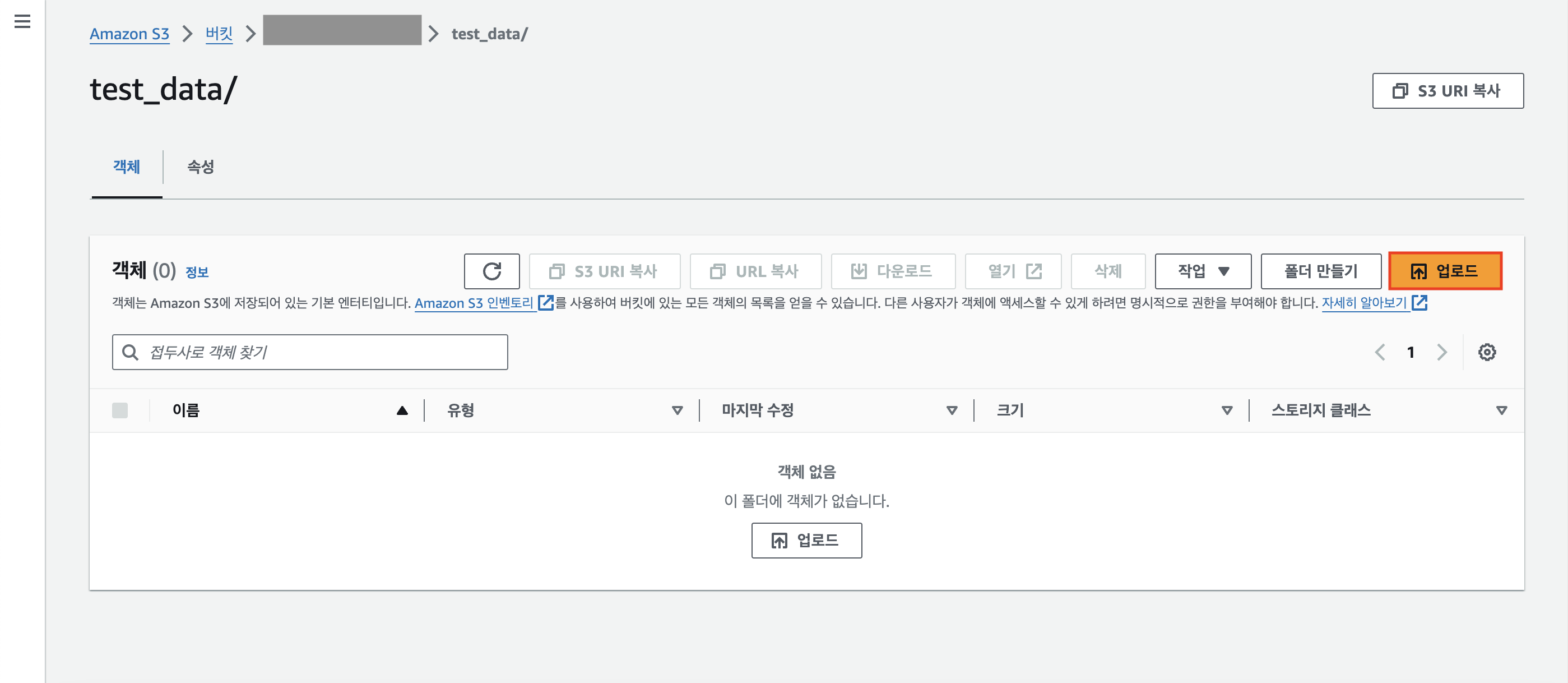
미리 다운로드 받은 4개의 csv 파일을 드래그해서 업로드한다.
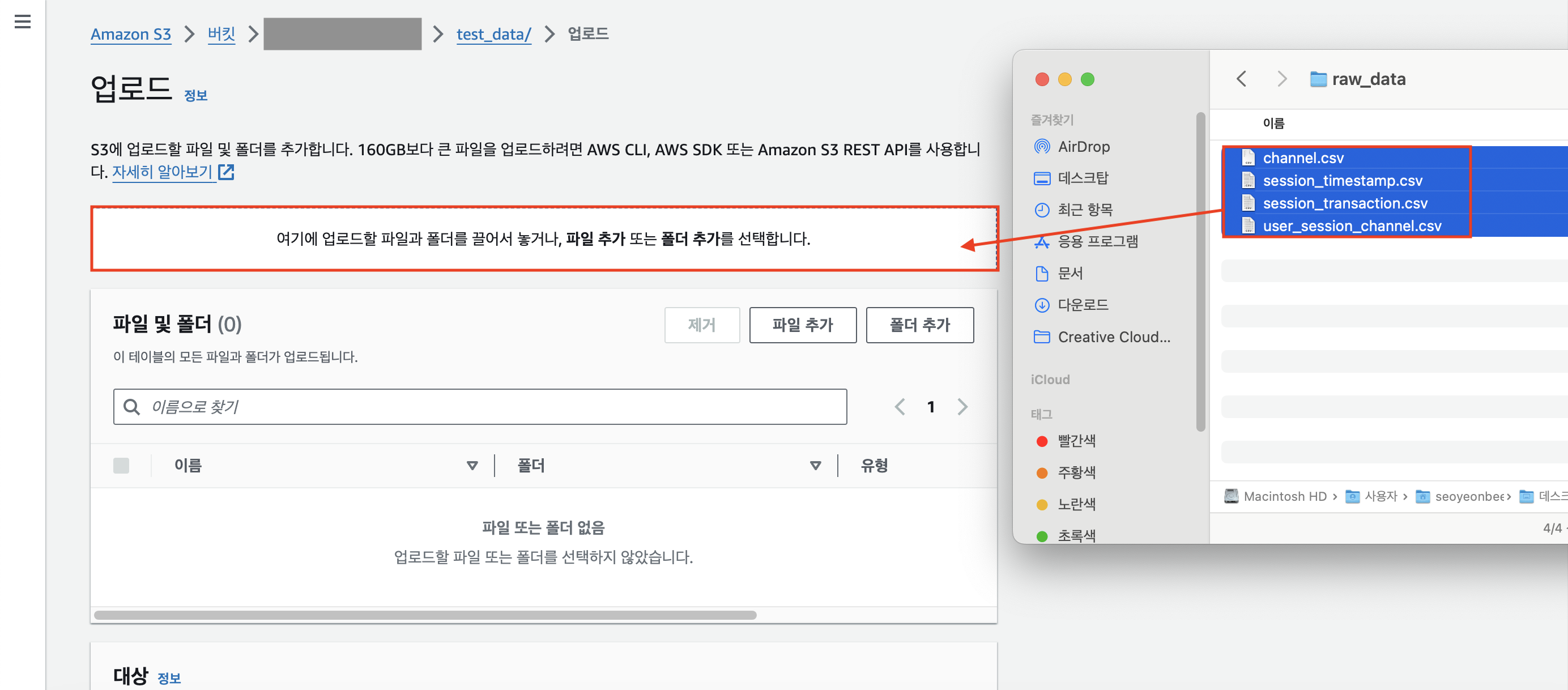
하단에 [업로드] 버튼을 누른다.
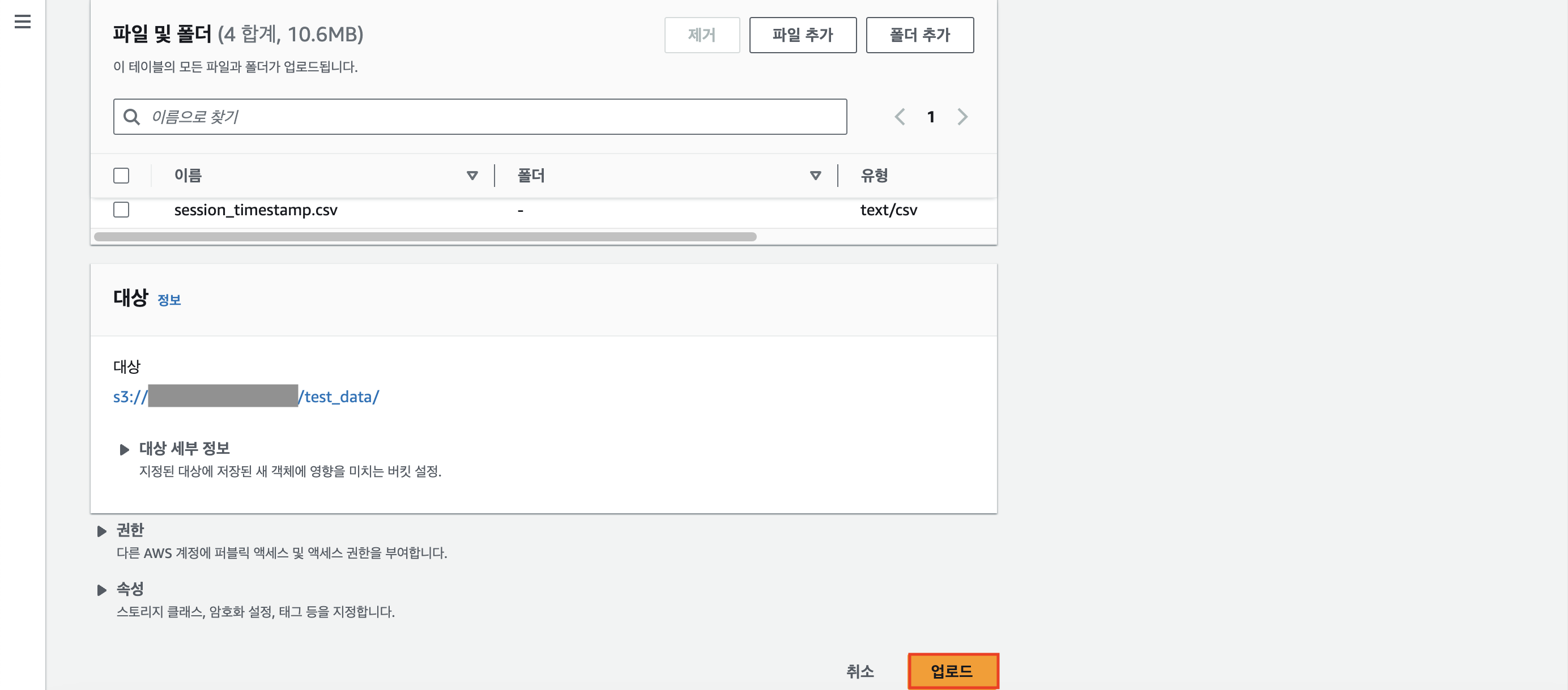
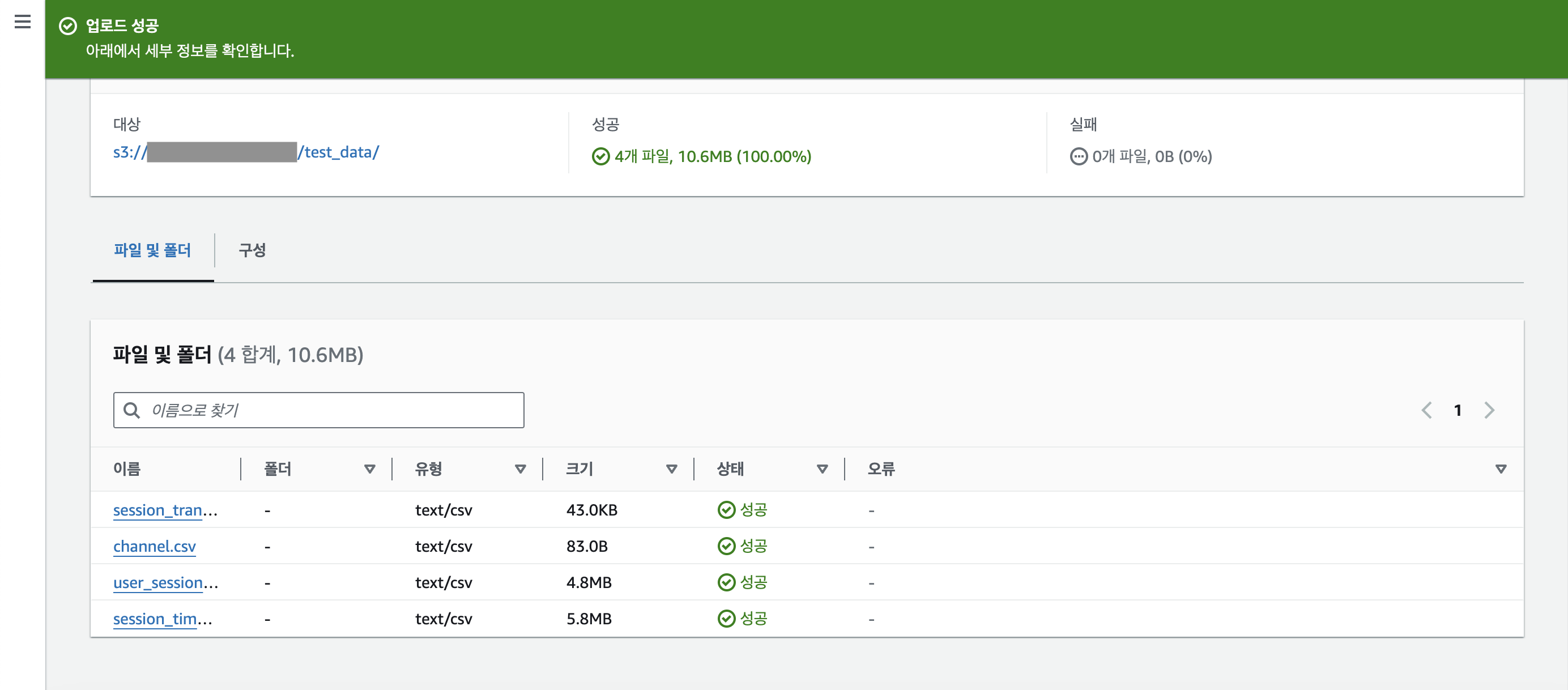
파일 업로드를 성공적으로 마쳤다면 아래와 같이 뜰 것이다.
화면을 살짝 위로 올려 [닫기] 버튼을 누르자.
4단계. IAM Role 설정
AWS Console 홈 에서 IAM을 검색 후 클릭하자.
(IAM의 역할 : Admin이 AWS Console 위에 새로운 계정을 만들 수 있게 한다.)
아직 새로운 사용자 계정을 생성한 적이 없다면 아래와 같이 0으로 표시될 것이다. 숫자를 클릭해보자.
새로운 사용자 계정을 생성하기 위해 [사용자 생성] 버튼을 클릭한다.
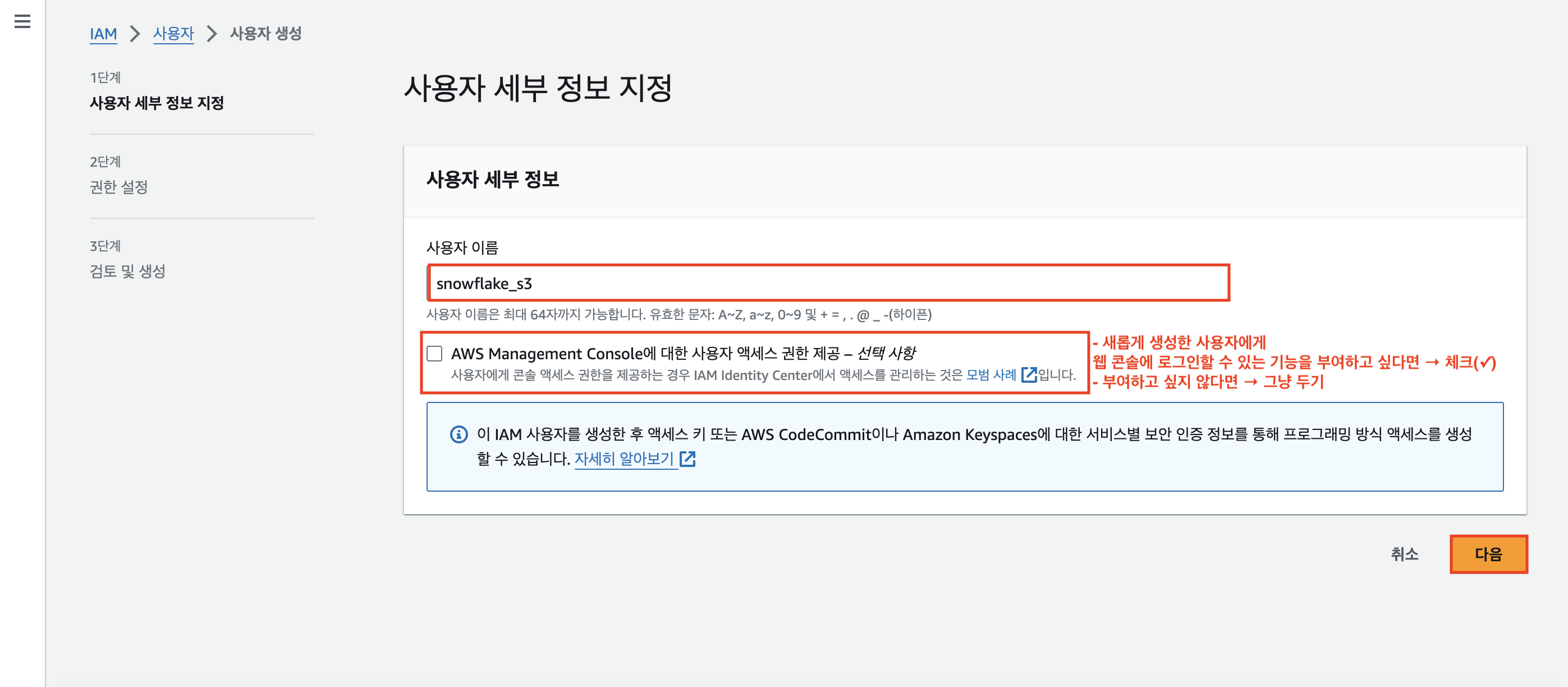
이번 실습에서 사용할 사용자 이름을 지정해주고(필자는 'snowflake_s3'로 설정했다.), [다음]버튼을 누른다.
사용자 이름 밑에 있는 [AWS Management Console에 대한 사용자 액세스 권한 제공] 체크박스의 경우,
새롭게 생성한 사용자에게 AWS 웹 콘솔에 로그인 할 수 있는 기능을 부여하고 싶다면 체크하면 되지만 그렇지 않은 경우 그냥 두면 된다.
이번 실습에서는 부여하지 않을 것이기 때문에 그냥 두고 넘어갔다.
다음으로 권한 설정 페이지로 넘어가게 되는데, [권한 옵션]은 [직접 정책 연결]로 체크해준다.
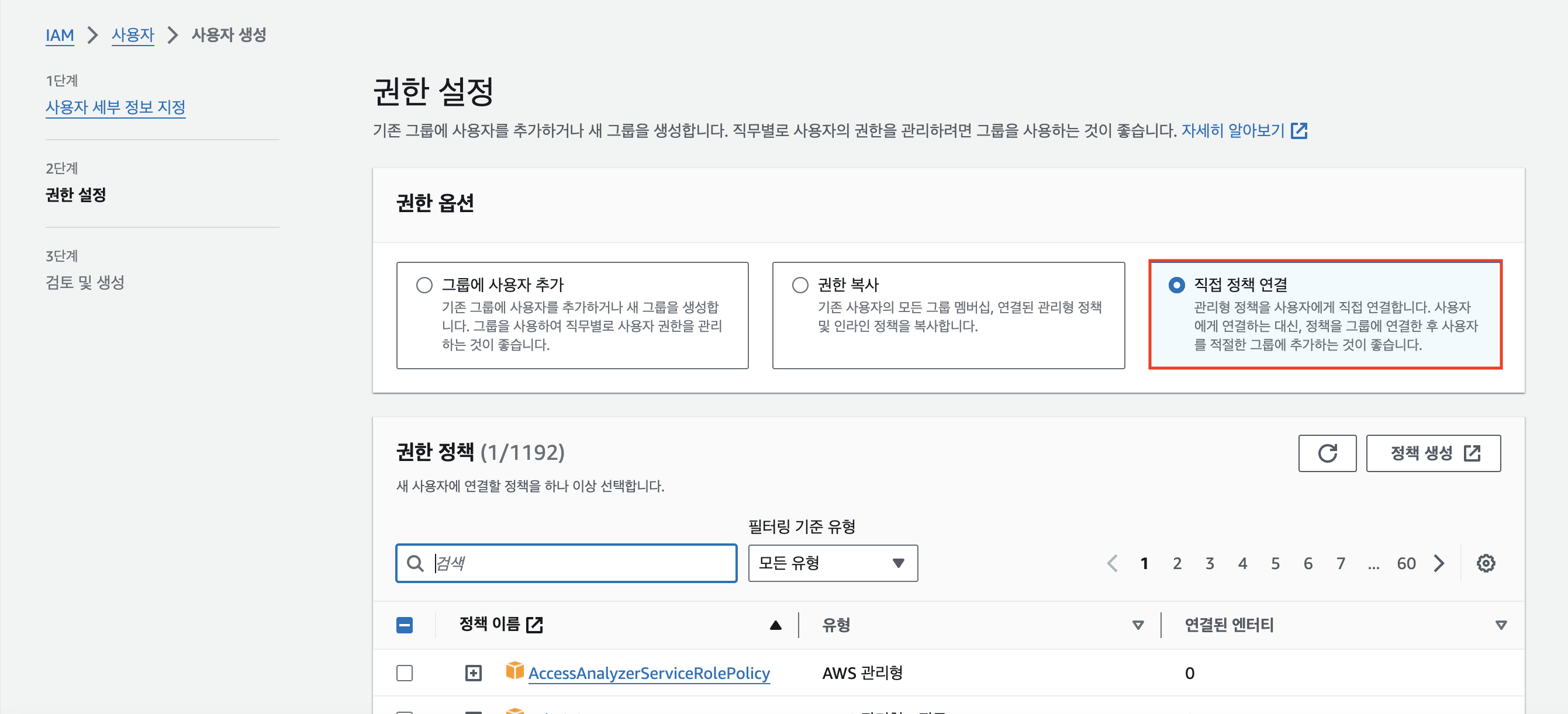
우리는 S3와 관계된 '읽기' 권한만 필요하기 때문에 검색창에 'S3Read'를 검색하고,
[AmazonS3ReadOnlyAccess] 정책에 체크한 후 [다음] 버튼을 눌러주면 된다.
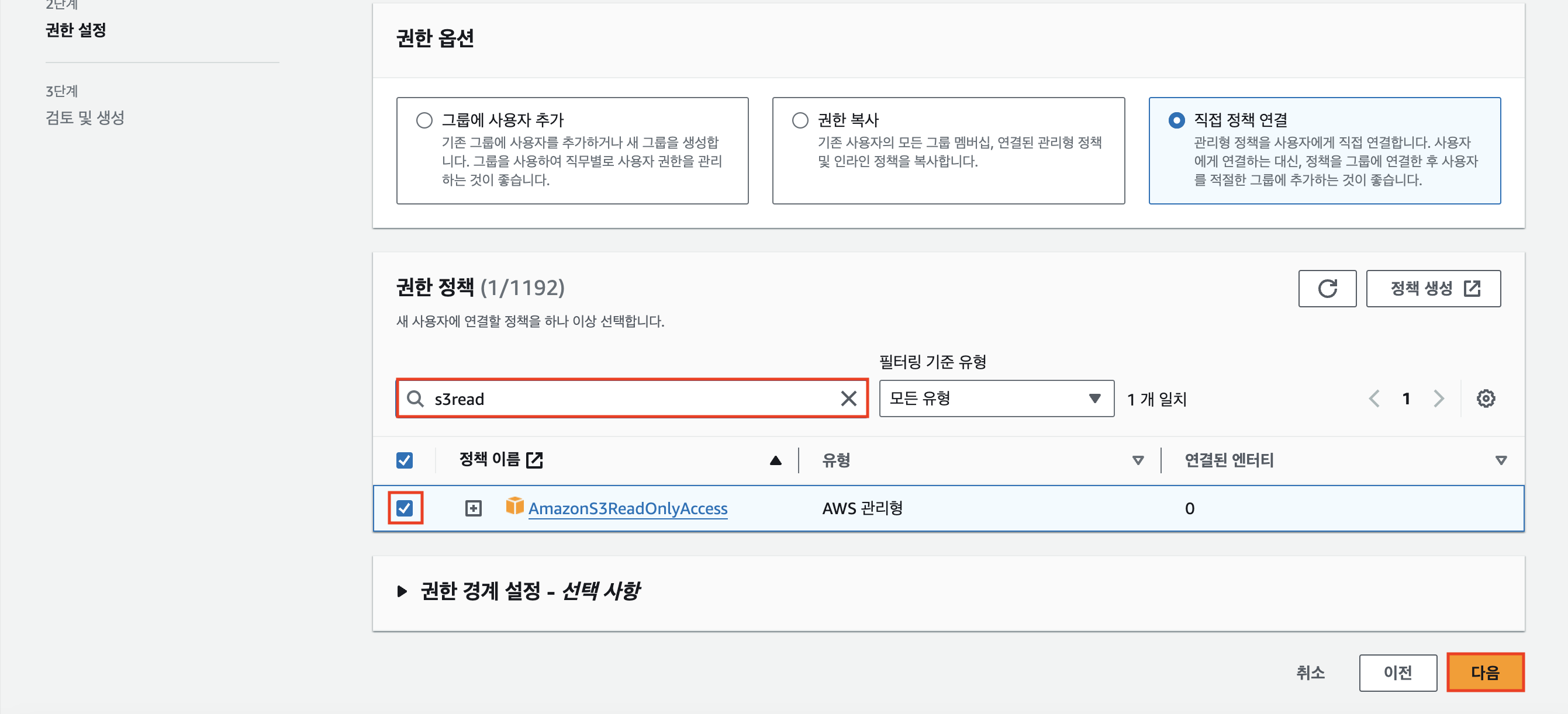
자, 이제 snowflake_s3라는 계정 내에 있는 모든 S3 버킷의 내용을 읽을 수 있게 된다.
아래와 같이 사용자 세부 정보와 권한 요약을 확인했다면 [사용자 생성] 버튼을 눌러
최종적으로 새로운 사용자 계정 snowflake_s3를 생성해준다.
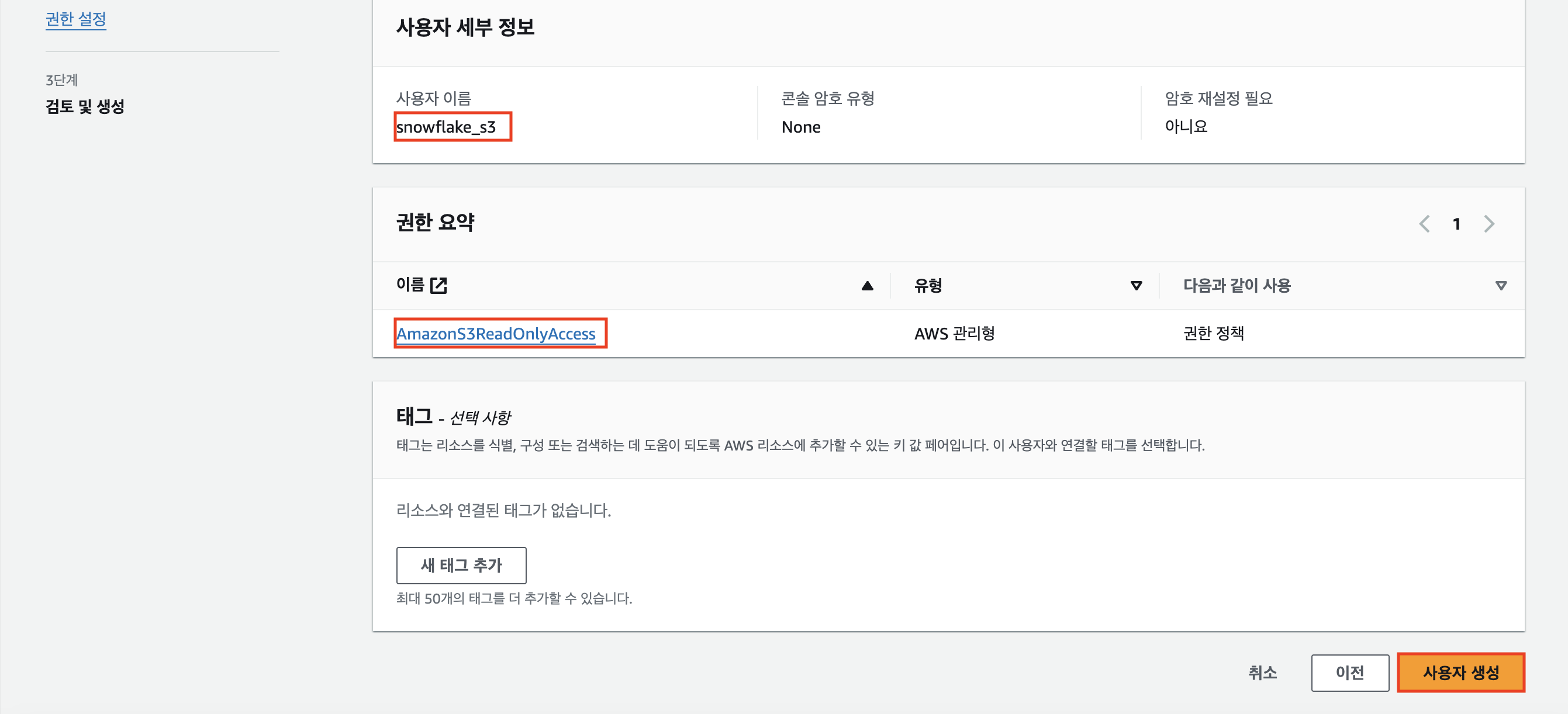
아래의 페잉지에서 생성한 사용자 이름을 클릭해보자.
[보안 자격 증명] 페이지를 클릭한다.
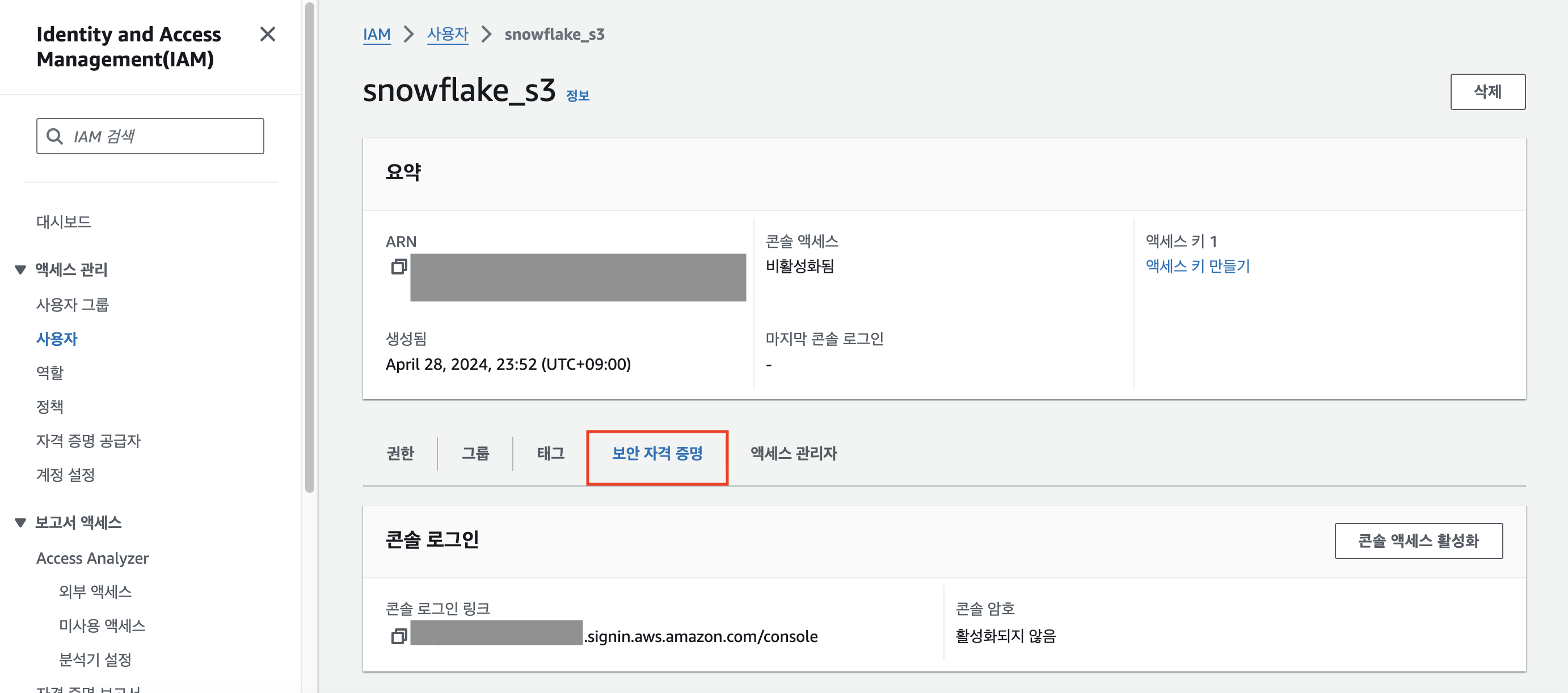
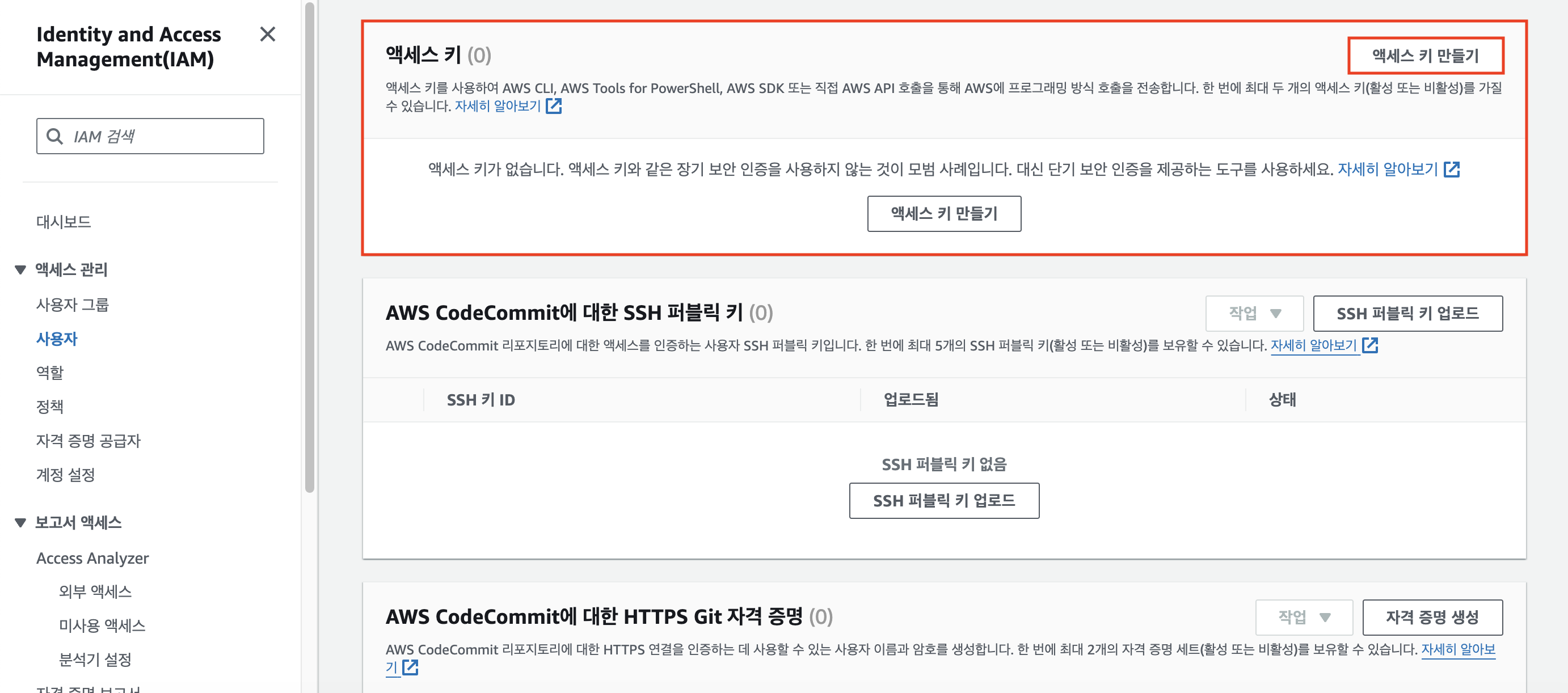
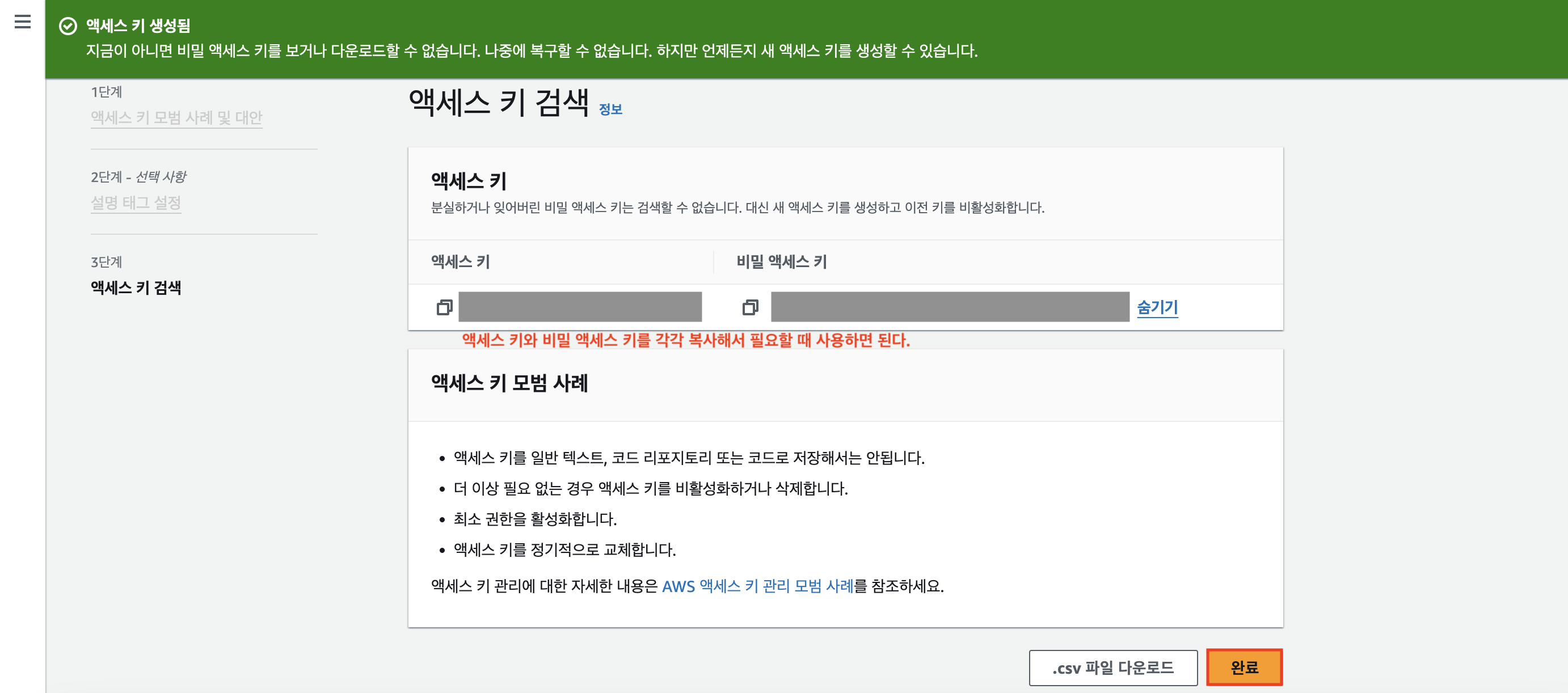
스크롤을 조금 내려보면 [액세스 키]에 대한 설정 칸이 있을 것이다. [액세스 키 만들기]를 클릭한다.
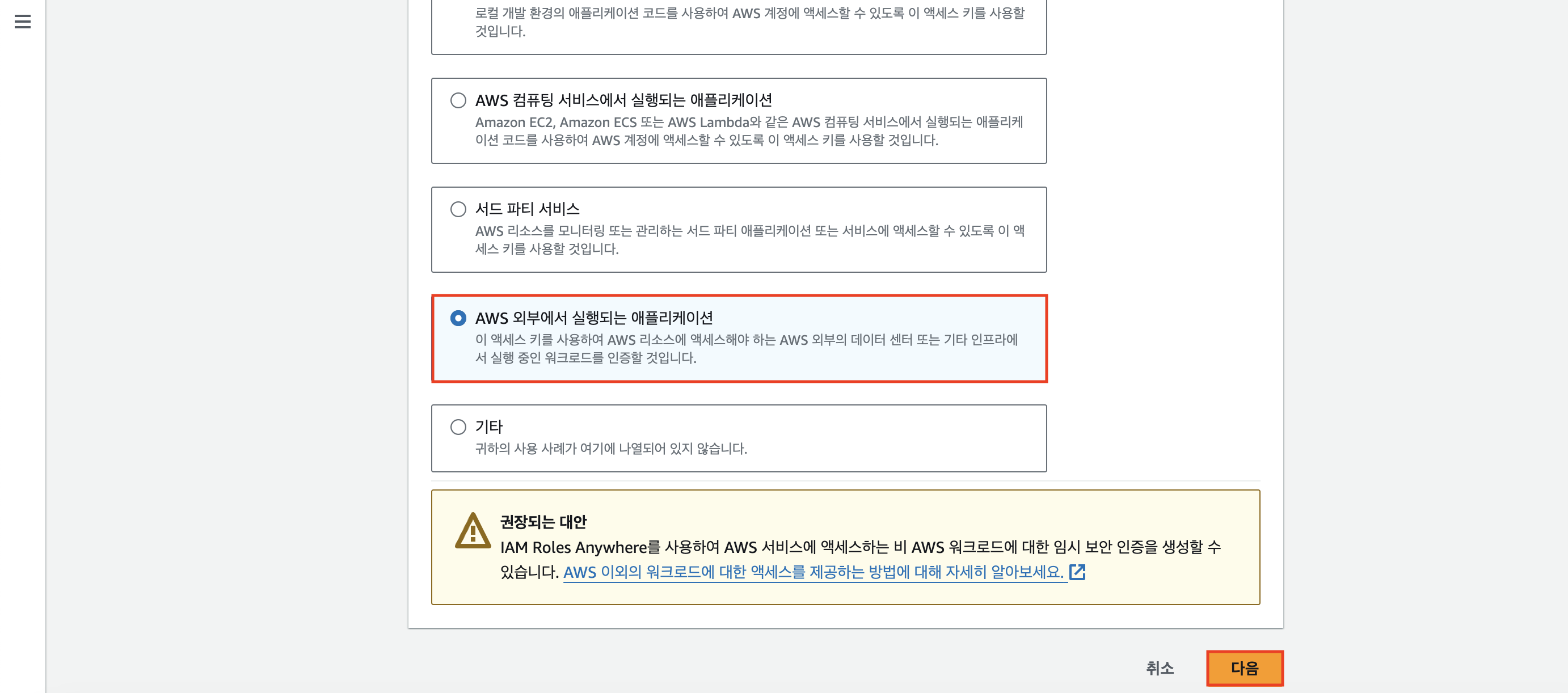
스크롤을 조금 내려서 [AWS 외부에서 실행되는 애플리케이션] 체크박스를 체크하고 [다음] 버튼을 눌러 진행한다.
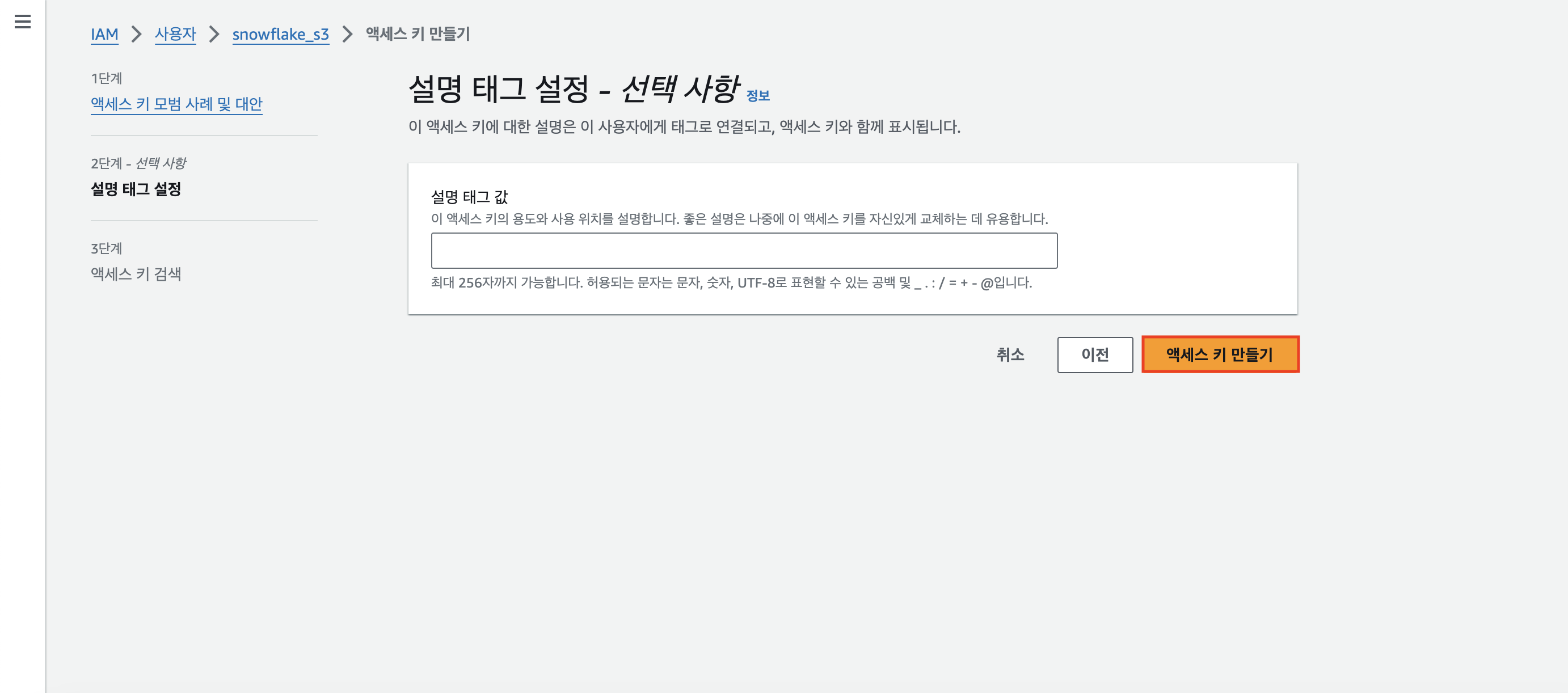
설명 태그 값 설정 없이 우리는 그냥 [액세스 키 만들기] 버튼을 클릭하면 된다.
그럼 만들어진 액세스 키에 대한 정보를 알 수 있다.
`AWS_KEY_ID`에 해당하는 [액세스 키]와 `AWS_SECRET_KEY`에 해당하는 [비밀 액세스 키]를 각각 복사해서 필요할 때 붙여넣어 사용하면 된다.
복사해서 북마크까지 완료했다면 [완료] 버튼을 눌러보자.
5단계. Snowflake 에디터에서 스키마 밑에 테이블 생성 후 COPY
`COPY INTO 테이블명`
: 레코드를 하나씩 적재하지 않고, 벌크로 레코드들이 있는 파일(csv, json 등)을 통째로 적재하는 방식
- 레코드들이 있는 파일들을 S3와 같은 클라우드 스토리지에 업로드
- 스토리지에 있는 파일들을 `COPY INTO 테이블명` 명령어로 목적 테이블에 벌크로(통째로) 적재
- Redshift, BigQuery에도 동일한 형태의 명령어 존재
- 클라우드 스토리지와 접근 권한 설정이 중요
우리가 해야하는 것
- 입력이 되는 csv파일을 적당한 위치에 다운로드 받기
(user_session_channel.csv, session_timestamp.csv, session_transaction.csv) - AWS에 로그인
- AWS 콘솔에서 고유한 이름으로 S3 버킷 하나 만들고 test_data라는 폴더 생성
- 해당 버킷에 3개의 csv 파일 업로드 하기
s3://고유한버킷명/test_data/user_session_channel.csv
s3://고유한버킷명/test_data/session_timestamp.csv
s3://고유한버킷명/test_data/session_transaction.csv - raw_data 스키마 밑에 3개의 테이블을 생성
- 3개의 테이블을 `COPY INTO` 명령어를 사용해서 벌크 업데이트
`credentials = ()` : Snowflake가 S3에 있는 파일을 접근할 수 있는 권한이 있는지 검증하는 파라미터
AWS 로그인할 때 사용하는 계정 정보로 로그인 - [내 정보] - [credentials] - 아래 두개의 키 정보가 있음
두 개의 키는 AWS 웹 콘솔 사용자마다 기본적으로 부여되는 것.
※ AWS 어드민 사용자의 AWS KEY ID와 AWS SECRET KEY를 사용하면 안됨!
► 따라서 가장 좋은 방법은 AWS 웹 콘솔이 어드민 사용자로 로그인 - [IAM] - 새로운 사용자 생성 - 해당 사용자는 S3 읽기 권한만 부여됨 - 해당 사용자의 AWS_KEY_ID와 AWS_SECRET_KEY를 사용하면 된다.
- `AWS_KEY_ID` :
- `AWS_SECRET_KEY` :
`FILE_FORMAT = ()` : 입력이 되는 파일의 포맷을 지정하는 파라미터
- `type` : 타입 지정 (필자는 `'CSV'`로 함)
- `skip_header` : 헤더를 생략할지 여부를 지정 (`1` : 생략 O, `0` : 생략 X)
- `FIELD_OPTIONALLY_ENCLOSED_BY` : string값이 쌍따옴표로 둘러싸여진 경우 쌍따옴표를 빼고 적재 (필자는 `""`로 함)
- (S3의 경우) 입력 레코드들이 있는 파일들이 적재될 버킷을 생성 후, 그 버킷에 파일 업로드
- 클라우드 스토리지(S3)를 접근할 수 있는 권한을 IAM을 통해 설정
- 해당 권한 정보를 `COPY INTO ` 명령에서 사용
📌 버킷(bucket) : SQL 최상위 디렉토리
`CREATE OR REPLACE TABLE` : 이미 기존에 테이블이 존재한다면 지우고 새로 생성
자 이제, Snowflake 에디터로 접속해보자.
왼쪽 상단의 [Projects] - [Worksheets]에서 'Setup-Env'라는 파일을 클릭해보자.
6단계. Snowflake 사용자 권한 설정 - Role과 User 생성
기본적으로 Snowflake는 Group을 지원하지 않는다.
일단, `analytics_users`, `analytics_authors`, `pii_users` 3개의 ROLE을 생성해보자.
-- 3개의 ROLE을 생성한다
CREATE ROLE analytics_users;
CREATE ROLE analytics_authors;
CREATE ROLE pii_users;
-- 여기까지는 3개의 ROLE이 어느 누구에게 할당된 것도 아니고, ROLE 자체도 아무런 권한이 없는 상태
-- 사용자 생성
CREATE USER keeyong PASSWORD='Keeyong99';
-- 사용자에게 analytics_users 권한 지정
GRANT ROLE analytics_users TO USER keeyong;
| analytics_authors | analytics_users | |
| 활용하는 사람들 | 데이터 분석가 | 데이터 소비자들 |
| raw_data 테이블들 | 읽기 | 읽기 |
| analytics 테이블들 | 읽기, 쓰기 | 읽기 |
| adhoc 테이블들 | 읽기, 쓰기 | 읽기, 쓰기 |
`analytics_users`와 `analytics_authors`의 ROLE을 설정해보자.
-- set up analytics_users
GRANT USAGE on schema dev.raw_data to ROLE analytics_users;
GRANT SELECT on all tables in schema dev.raw_data to ROLE analytics_users; GRANT USAGE on schema dev.analytics to ROLE analytics_users;
GRANT SELECT on all tables in schema dev.analytics to ROLE analytics_users; GRANT ALL on schema dev.adhoc to ROLE analytics_users;
GRANT ALL on all tables in schema dev.adhoc to ROLE analytics_users;
-- set up analytics_authors
GRANT ROLE analytics_users TO ROLE analytics_authors;
GRANT ALL on schema dev.analytics to ROLE analytics_authors;
GRANT ALL on all tables in schema dev.analytics to ROLE analytics_authors;
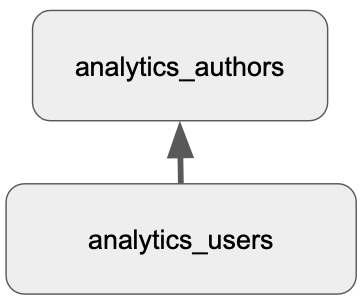
► `analytics_authors` 위에 레이어가 쌓일수록 편리해진다.
📌 컬럼 레벨 보안 (Column Level Security)
: 테이블내의 특정 컬럼(들)을 특정 사용자나 특정 역할(Role)에만 접근 가능하게 하는 것
- 보통 개인정보 등에 해당하는 컬럼을 권한이 없는 사용자들에게 감추는 목적으로 사용됨
📌 레코드 레벨 보안 (Row Level Security)
: 테이블내의 특정 레코드(들)을 특정 사용자나 특정 역할에만 접근 가능하게 하는 것
- 특정 사용자/그룹의 특정 테이블 대상 SELECT, UPDATE, DELETE 작업에 추가 조건을 다는 형태로 동작
Data Governence
: 필요한 데이터가 적재적소에 올바르게 사용됨을 보장하기 위한 데이터 관리 프로세스
목적
- 품질 보장
- 데이터 기반 결정에서 일관성
- 예. KPI 등의 지표 정의와 계산에 있어 일관성
- 데이터를 이용한 가치 만들기
- Citizen data scientist가 더 효율적으로 일할 수 있게 도와주기
- Data silos를 없애기
- 데이터 관련 법규 준수
- 개인 정보 보호 → 적절한 권한 설정과 보안 프로세스 필수
관련 기능
※ 아래의 기능들은 Standard에서는 사용 불가하고 Enterprise에서만 사용 가능하다.
1. Object Tagging
: 객체에 태그(system_tag, user_defined_tag)를 걸어서 관리를 용이하게 함(ex. 메타 데이터 생성)
- 매뉴얼하게(사람이 일일이) 관리하기 쉽지 않음 ► Data Classification
- 문자열을 Snowflake object에 지정 가능 (계정, 스키마, 테이블, 컬럼, 뷰 등등)
- 시스템 태그도 있음 (뒤의 Data Classification에서 다시 이야기)
- 지정된 tag는 구조를 따라 계승됨
📌 Object : Snowflake 내 다양한 객체들
2. Data Classfication
: 자동으로 특정 컬럼의 내용을 살펴보고 개인정보 유무, 특징 등을 자체적으로 분류해줌
3가지 스텝으로 구성
- Analyze : 테이블에 적용하면 개인정보나 민감정보가 있는 컬럼들을 분류해냄
- Review : 이를 사람(보통 DE)이 보고 최종적으로 리뷰(결과 수정 가능)
- Apply : 최종 결과를 시스템 태그(아래 2종류)로 적용
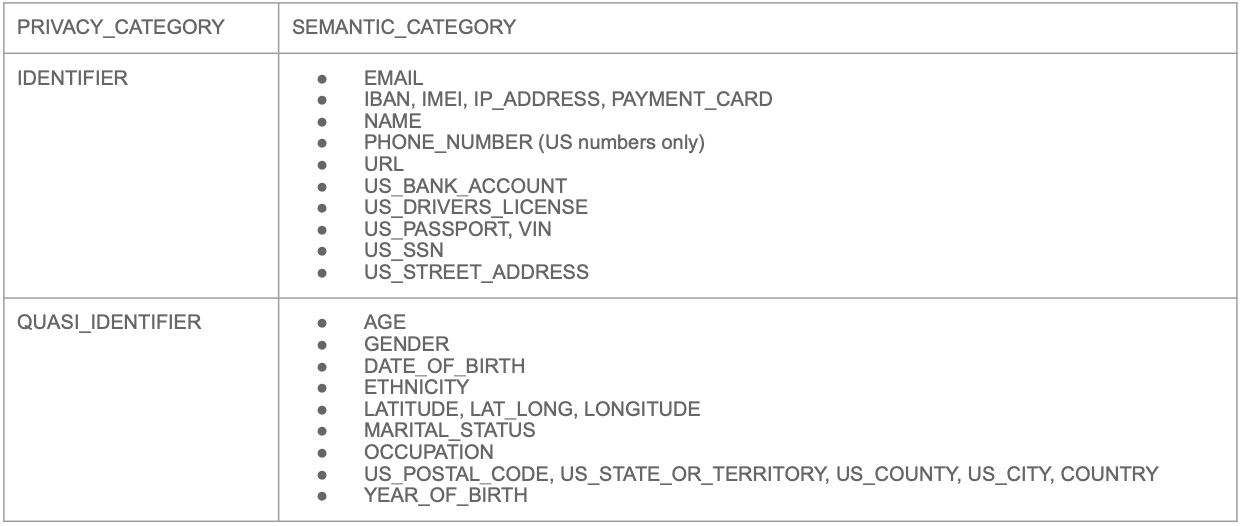
- `SNOWFLAKE.CORE.PRIVACY_CATEGORY` : (상위레벨)
► 가능한 값 : `IDENTIFIER`(개인식별자), `QUASI_IDENTIFIER`(개인 준식별자), `SENSITIVE`(개인정보는 아닌 민감정보)
- `SNOWFLAKE.CORE.SEMANTIC_CATEGORY` : (하위레벨 = 더 세부정보)
📌 `IDENTIFIER`(개인식별자) : 개인을 바로 지칭하는 식별자
📌 `QUASI_IDENTIFIER`(개인 준식별자) : 몇 개의 조합으로 지칭 가능한 식별자
3. Tag based Masking Policies
: 태그를 바탕으로 접근 권한을 지정해줌 (Tag Lineage가 여기에도 적용됨)
4. Access History
: 사용자의 모든 행동을 컬럼 기준으로 기록하는 것
- 목적 : Audit (데이터 접근에 대한 감사 추적을 제공하여 보안과 규정 준수)
- 다른 모든 클라우드 데이터 웨어하우스에서도 제공됨
5. Object Dependencies
: 원본 테이블에 있는 속성들로 조인해서 새로운 테이블을 생성할 때 따라가야 하는 것
- 목적 : 데이터 거버넌스와 시스템 무결성 유지
- 테이블 or 뷰를 수정할 경우 이로 인한 영향을 자동으로 식별
- 계승 관계 분석을 통해 더 세밀한 보안 및 액세스 제어 가능
Snowflake 기타 기능
Marketplace
: 사용자가 원하는 데이터 소스를 검색해서 유료로 제공되는 기능을 사용할 수 있음
Data Sharing
: 오른쪽 상단에 [Share] 버튼의 기능
Activity - Query / Copy / Task History
1) Query History : Select, Create, Update. 어떤 SQL이 언제 생성되었는지에 대한 히스토리
2) Copy History : 벌크업 데이터 히스토리
3) Task History : 특정 SQL을 주기적으로 실행된 히스토리
무료 체험판을 종료시키는 방법
1. 무료 시험 기간이 끝나면 계정은 자동으로 “Suspended” 모드로 변경됨
- 첫 신청 시 신용카드 정보를 입력하지 않음
- Suspended 모드에서 벗어나려면 크레딧 카드 정보 입력이 필요
2. 그전에 끝내고 싶다면 Snowflake 서포트에 이메일을 보내서 종료 가능
https://docs.snowflake.com/en/user-guide/admin-trial-account#canceling-a-trial-account
Trial accounts | Snowflake Documentation
A Snowflake trial account lets you evaluate/test Snowflake’s full range of innovative and powerful features with no cost or contractual obligations. To sign up for a trial account, all you need is a valid email address; no payment information or other qu
docs.snowflake.com