
시리즈 (Series)
# pandas 모듈 불러오기
import pandas as pd
1. List → Series 변환
# 숫자로 된 리스트 생성
numbers = list(range(3, 14))
# 생성한 리스트를 시리즈로 변환
pd.Series(numbers)
# 문자로 된 리스트 생성
letters = list('programmers')
# 생성한 리스트를 시리즈로 변환, numbers리스트를 인덱스로 설정
pd.Series(letters, index=numbers)
↑ 이런식으로 인덱스를 설정해도 문제가 생기지 않는다.
pandas에서 사용하는 인덱스는 꼭 숫자 타입이 아니어도 되기 때문이다.
이런 인덱스를 인덱스 레이블(index lable) 이라고 부른다.
※ 주의할 점 : value의 개수와 index의 개수가 같아야 함
# 인덱스 레이블을 문자로 생성
letters_index = [ f"문자{i}" for i in range(1, 12)]
# letters 리스트를 인덱스 레이블 letters_index를 사용해서 시리즈로 변환
pd.Series(letters, index=letters_index)

f string
list comprehension
2. Dictionary → Series 변환
- key는 index로 배치
- value는 value로 배치
# 딕셔너리 생성
user = {
"name" : "Kim",
"age" : 20,
"job" : None
}
# 딕셔너리를 시리즈로 변환 (key -> index, value -> value)
pd.Series(user)
Dictionary 타입을 시리즈화 하면 알아서 index label이 key로 생성된다.
# 딕셔너리를 시리즈로 변환하고, 인덱스를 지정
pd.Series(user, index=['name', 'age', 'address'])
만약 따로 index를 지정해준다면
없는 key에 대해서는 `NaN`을 반환한다.
# 딕셔너리를 시리즈로 변환하고, 인덱스를 지정
pd.Series(user, index=['name', 'age', 'job', 'address'])
있는 value에 대해서만 시리즈화 되고, 그 value에 해당하는 key가 index에도 추가되어져 있어야 한다.
속성 (Attribute)
: 데이터가 만들어진 이후에, dot (`.`)으로 접근했을 때 메소드 혹은 속성값을 사용할 수 있게 한다.
1. `.dtype`
: 시리즈가 반환하는(담고있는) 데이터 타입
- ìnt64`: 정수형 데이터 타입
- `o`: (=object) 문자(열) 데이터 타입
2. `.index`
: 인덱스 정보를 준다.
Pandas에서 시리즈화 할 때 알아서 Index Label을 만들어주는데, 그 때 `RangeIndex`라는 객체를 사용한다.
3. `.value`
: 데이터를 배열(Array) 형태로 반환한다.
** Array (배열)
각각의 데이터 타입이 다를 수 없다.
만약 다양한 데이터 타입이 섞여서 들어가있을 때는 전부 '문자'로 처리한다. → `dtype = object`
4. `.shape`
: 데이터의 구조를 tuple 형태로 알려준다.
- 1차원 구조는 한줄이어도 뒤에 콤마(`,`)를 붙여줘야 튜플로 인식
- Series는 1차원 구조
5. `.size`
: 데이터의 크기를 알려준다.
6. `.hasnans`
: `dtype`의 형태로 인식할 수 없는 `None`이나 `NaN`과 같은 결측치(Missing Data)가 있는지 확인한다.
- 결측치 존재 O → `True`
- 결측치 존재 X → `False`
메소드 (Method)
: 객체 안에 있는 함수
.메소드()
1. `.max()`
: 최댓값
2. `.idxmax()`
: 최댓값이 몇 번째 인덱스에 있는지
※ `NaN`은 순서 고려에서 제외된다.
3. `.min()`
: 최솟값
4. `.idxmin()`
: 최솟값이 몇 번째 인덱스에 있는지
※ `NaN`은 순서 고려에서 제외된다.
5. `.sum()`
: 합계
6. `.mean()`
: 평균
7. `.isnull()`, `.isna()`
: value 중 null 또는 not 유형의 데이터가 없는지 결측치를 체크
(`.isnull()`의 별칭이 `.isna()`)
`isnull` 뒤에 커서 놓고 단축키 `Shift + tab` : docstring

8. `.round()`
: 각 수치 반올림
Q. 왜 90.5는 90이 되고, 55.5는 56이 될까?
A.
Python의 반올림은 오사오입 (Round half to even)
: 반올림할 숫자가 정확히 반절 위치 .5일 경우, 가까운 짝수 쪽으로 반올림하는 규칙
(= 반올림할 숫자가 절반 .5일 경우 그 결과는 무조건 짝수가 된다.)
Q. 반올림은 올림과 내림이 합쳐진 형태이다. 하지만 정확히 반절 지점인 .5에서는 어떻게 공정할까?
A. 학교에서 배운 반올림(사사오입;Round off) 관점에서, .5는 '올림'으로 처리한다.
- 0, 1, 2, 3, 4 → 내림
- 5, 6, 7, 8, 9 → 올림
이 경우, 통계적으로 "중립성"이 어긋나게 된다.
예를 들어,
- 0.5 + 1.5 + 2.5 + 3.5 = 8.5의 각 항목에 위치하는 값을 사사오입 반올림해서 합산하면
- 1 + 2 + 3 + 4 = 10이 되어 오차는 1.5가 된다.
이 경우, 통계학이나 빅데이터와 같은 많은 값을 다루는 학문에서 오차가 크게 발생할 수 있다.
때문에 "반절 위치 .5를 올림으로 처리하는 것은 중립적이지 못하다."라고 보며, 통계학에서는 '오사오입 반올림'을 사용한다.
이번에는 오사오입 반올림으로 계산해보자.
- 0.5 + 1.5 + 2.5 + 3.5 = 8.5의 각 항목에 위치하는 값을 오사오입 반올림해서 합산하면
- 0 + 2 + 2 + 4 = 8로 오차는 0.5가 된다.
즉, "반절 위치 .5가 나올 경우, 반절은 올림 + 다른 반절은 내림으로 처리하여 중립성을 만든다."라고 본다.
Q. 반올림은 왜 하는 것일까?
A. 정확한 값이 필요하지 않은 경우 유용한 처리이며, 정확한 값을 표현하지 못하더라도 내가 원래 얻고자 하는 결과와 동떨어져서는 안된다. 때문에 반올림이 필요한 경우와 그렇지 않은 경우를 구분해가며 사용해야 한다.
1) 소수점 이하 자리수 조절
- 소수점 이하 자리수를 조절하기 위해 반올림을 사용
- 예를 들어, 소수점 둘째 자리까지 표현하려면 반올림을 사용하여 적절한 근사치로 표현 가능하다.
2) 데이터의 정확도 제안
- 데이터의 정확한 값을 표현할 필요가 없는 경우 반올림을 사용
- 예를 들어, 실험 결과를 소수점 둘째 자리까지만 표현하거나, 금액을 소수점 이하 자리를 제한하여 처리할 때 반올림을 사용
3) 통계 분석
- 데이터의 크기를 줄이고 결과를 간소화하기 위해 반올림을 사용
- 예를 들어, 평균 or 중앙값을 소수점 이하 자리수로 표현할 때 반올림 사용
4) 시각화
- 데이터를 시각화할 때, 그래프의 레이아웃을 개선하고 더 깔끔하게 표현하기 위해 반올림 사용
- 예를 들어, 축의 눈금을 반올림하여 그래프를 더 가독성있게 만들 수 있음
Kaggle 실습
🔗 실습 링크 : https://www.kaggle.com/datasets/tarundalal/100-richest-people-in-world
100 Richest People In World
100 Richest People In The World
www.kaggle.com

csv(comma-seperated value) 파일
: 콤마(`,`) 로 값을 구분해놓은 형식

`.read_csv()`는 무조건 DataFrame 형태로 불러오기 때문에
Series화 하기 위해서는 `.squeeze()`메소드를 사용해야한다.
Series화 한 csv파일을 불러와도 DataFrame형태로 인식한다.
`.to_csv('저장할_파일명')`
: csv파일 저장
# csv 파일로 저장
richest_series.to_csv('TopRichestInWorld_new.csv')

만약 index를 빼고 저장하고 싶다면
# index는 제외하고 저장
richest_series.to_csv('TopRichestInWorld_new.csv', index=False)
데이터 간이 확인
1. `.head()`
: 상위 5개 데이터 확인(괄호 안에 넣은 숫자만큼 확인할 수도 있음)
2. `.tail()`
: 하위 5개 데이터 확인(괄호 안에 넣은 숫자만큼 확인할 수도 있음
값 정렬 : .sort_values()
: 값들을 오름차순 정렬해서 반환한다.
`.sort_values()`메소드의 인자
1) axis
: 기준이 되는 축
- 0 : index(행) ← 디폴트
- 1 : columns(열)
2) ascending
: 정렬 방식
- True : 오름차순 ← 디폴트
- False : 내림차순
3) inplace
: 파괴적 처리 여부
- True : 파괴적 처리(원본 변경)
- False : 비파괴적 처리 ← 디폴트
파괴적 처리를 하는 메소드들은 바로 값을 출력하지 않음
python에서 자주 사용하는 `.sort()` 메소드도 동일한 기능을 수행함
이런식으로 원본을 파괴할 경우 다양한 에러에 노출될 수 있으므로, `.copy()` 메소드를 통해 복사본을 만들어 사용하는 것이 안전하다.
rich_set_copy = rich_set.copy()
rich_set_copy.sort_values(inplace=True)
rich_set_copy
4) kind
: 정렬하는 엔진(정렬 알고리즘) 타입 (디폴트 : quicksort)
- 'quicksort' : 퀵정렬 ← 디폴트
- 'mergesort' : 병합정렬
- 'heapsort' : 힙정렬
- 'stable' :
5) na_position
: 결측치의 위치 지정
- 'first' : 앞쪽으로 배치
- 'last' : 뒤쪽으로 배치 ← 디폴트
6) ignore_index
: 정렬 시 index 컬럼도 같이 정렬할지 여부
- True : 유지하고 정렬
- False : 같이 정렬 ← 디폴트
7) key
: 정렬에 함수를 적용하고 싶을 때 사용 → 정렬 기준을 세부적으로 지정할 수 있음
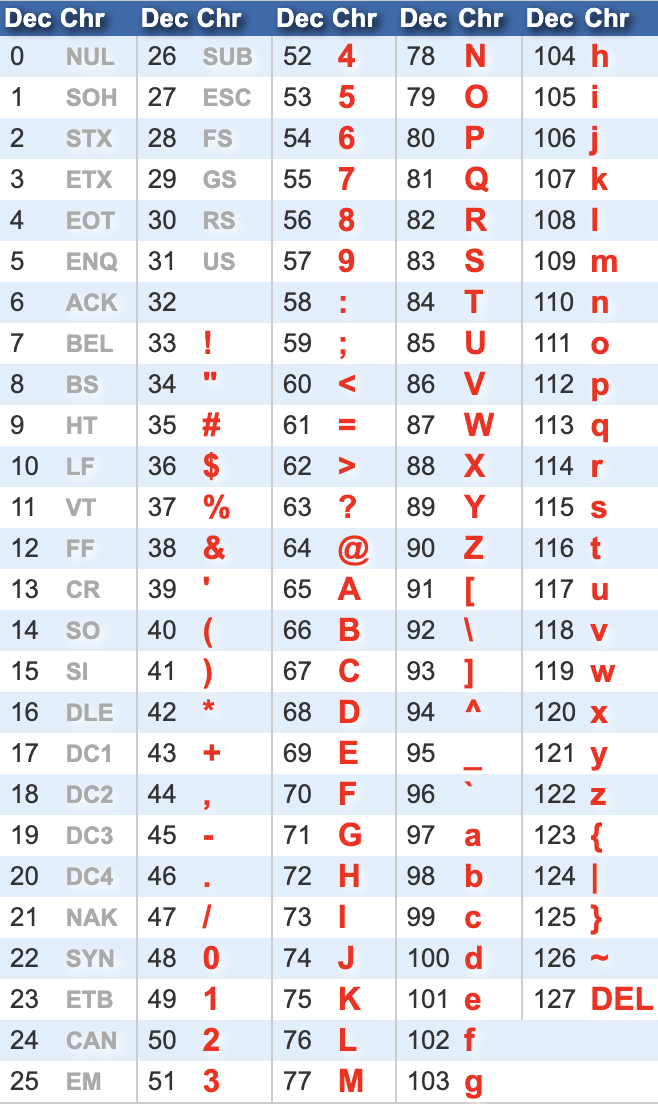
문자의 크기를 판단할 때, ASCII 코드 내 해당하는 숫자로 판단하게 되므로
알파벳 상 대문자가 먼저, 소문자가 나중에 나오게 된다.
index가 포함된 Series 데이터를 불러오기 때문에 에러가 발생한다.
따라서 시리즈에 맞는 코드를 작성해 주어야 한다. → `x.str.lower()`
Q. `lambda` 인자에 들어오는 `x`값이 문자열이면 바로 `len(x)` 나 `lower(x)`를 사용해도 되지 않을까?
A. Series엣어는 불가능하다.
# 에러발생
rich_set.sort_values(key=lambda x:len(x))
의미 : key function이 배열구조를 바꿀 수 없다
→ 즉, `len()` 함수 자체가 배열 형태의 모양을 바꿀 수 없으니까 에러가 발생한 것이다.
# 올바른 코드
rich_set.sort_values(key=lambda x:x.str.len())
인덱스 정렬 : .sort_index()
`.sort_index()`의 인자는 `.sort_values()` 와 100% 동일하지만, 몇 가지 추가되는 파라미터가 있다.
8) level
:
9) sort_remaining
:
Q. `.sort_index()`의 인자가 더 많은 이유는?
A. List의 인덱스는 0과 자연수만 가능하지만,
Pandas Series의 인덱스는 인덱스의 기능을 할 뿐이지 숫자 외 다양한 형태의 값이 들어갈 수 있기 때문이다.
Pandas Series는 엄연히 1차원 리스트가 맞지만, 인덱스 레이블을 별도의 객체라고 표현한다.
이러한 객체를 '인덱스 배열(색인 객체열; Index Object)' 이라 부른다.
값 세기 : .value_counts()
1) normalize
: 정규화(백분율로 환산해줌)
- False : 환산 X ← 디폴트
- True : 환산 O
2) sort
: 빈도별로 정렬할지 여부
- True : 빈도로 정렬 ← 디폴트
- False : 순서 유지
3) ascending
: 정렬 방식
- True : 오름차순 ← 디폴트
- False : 내림차순
4) bins
: 지정한 숫자만큼 범위를 나누어서 범위별로 해당되는 개수를 반환
- bins가 지정되지 않았다면, 고유 값의 빈도로 카운트한다.
- 숫자처럼 '연속형 데이터'만 가능하다.
5) dropna
: NaN 처리
- True : 결측치 카운트 X ← 디폴트
- False : 결측치 카운트 O
값 접근 방법 (Access)
RangeIndex
: 순차적인 정수로 구성된 인덱스 객체로, DataFrame 또는 Series 생성시 명시적으로 인덱스를 지정하지 않은 경우에 기본적으로 생성되는 인덱스
- 0부터 시작
- 데이터의 길이 또는 행 개수에 따라 자동으로 생성
- 변경할 수 없는 (immutable) 객체로, 크기가 고정
- 메모리 사용을 최적화하여 데이터 검색 및 접근 속도를 향상
Index
: 일련의 값으로 구성된 인덱스 객체
- 문자열, 정수, 날짜 등의 다양한 데이터 타입
- 명시적으로 저장되거나 다른 데이터의 인덱스로부터 생성 가능
- 변경 가능한 (mutable) 객체로, 크기가 가변
- 인덱스의 값, 순서 변경 및 인덱스 추가/삭제 가능
- 데이터의 레이블링, 인덱싱, 슬ㄹ라이싱 등 다양한 데이터 조작 작업에 활용
Q. Pandas Series도 Python List 처럼 인덱스 순환이 가능할까?
A. 불가능(에러 발생)
Series의 인덱스는 숫자로 접근하는 것이 아니라 글자(레이블)로 접근하는 것이기 때문이다.
이는 Key Error을 보고 '지원을 안한다.' 가 아니라 '방식이 잘못되었다.'는 것을 알 수 있다.
Q. `del user_set['name']`은 되고 `del user_set[0]`은 안되는 이유?
- `del user_set['name']` : 인덱스 레이블을 사용하여 해당하는 인덱스&값을 삭제
- 인덱스가 문자열일 경우 Series객체는 인덱스를 사용할 수 있다는 원칙이 있다.
- Series 객체는 인덱스 레이블 기준 연산이 우선이다.
- `del user_set[0]` : 정수 인덱스를 사용하여 삭제하는 것이 불가능
- `user_set[0]` 가능 : 조회는 데이터를 파괴하지 않기 때문에 정수 인덱스로 조회는 가능
- del을 이용한 삭제는 정수 인덱스 사용이 불가능
▶ RangeIndex는 이미 정수로 레이블을 사용하고 있기 때문에 정수 인덱스 사용이 불가능하다.
# 정수 인덱스와 인덱스 레이블이 일치하는 상황
data = ['banana', 'apple', 'coconut']
data_set = pd.Series( ['banana', 'apple', 'coconut'], index = [0, 1, 2])
data_set.index
▶ 문자열로 만들어진 Series객체가 인덱스로 사용될 경우, 인덱스를 구성하는 배열의 정수 인덱스는 조회할 때는 사용 가능하지만 삭제, 수정 등의 연산은 사용 불가능하다.
# 정수 인덱스와 인덱스 레이블이 다른 상황
user = {"name":"Spencer", "age":20, "job":None}
user_set = pd.Series({"name":"Spencer", "age":20, "job":None}, index = ["name", "age", "job"])
user_set.index