
JOIN
: 두 개 이상의 테이블들을 공통 필드(컬럼)를 중심으로 합치는데 사용된다.
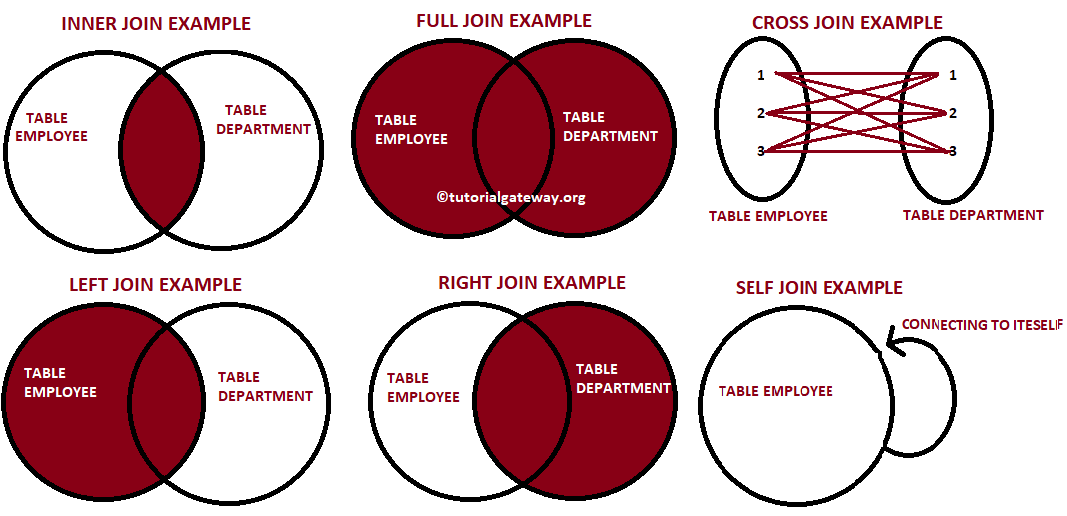
- 이는 Star Schema로 구성된 테이블들로, 분산된 정보를 통합하는데 사용된다.
- JOIN의 결과는 방식에 상관없이 양쪽의 필드를 모두 가진 새로운 테이블을 만들어낸다.
- 조인 방식에 따라 다음 두 가지가 달라진다
- 어떤 레코드들이 선택되는가?
- 어떤 필드들이 채워지는가?
JOIN의 종류
1. INNER JOIN
- 양쪽 테이블에서 서로 매치되는 레코드들만 리턴한다.
- 양쪽 테이블의 필드가 모두 채워진 상태로 리턴된다.
- JOIN 앞에 아무것도 없으면 디폴트로 INNER JOIN이라 생각하면 된다.
SELECT *
FROM raw_data.Vital v
JOIN raw_data.Alert a ON v.VitalID = a.VitalID;
2. LEFT JOIN
- 왼쪽 테이블(Base)의 모든 레코드들을 리턴한다.
- 오른쪽 테이블의 필드는 왼쪽 레코드와 매칭되는 경우에만 채워진 상태로 리턴된다.
- 왼쪽 레코드들과 매칭되지 않는 오른쪽 레코드들은 NULL로 채워진다. (Python Notebook에서는 None으로 채워짐)
SELECT *
FROM raw_data.Vital v
LEFT JOIN raw_data.Alert a ON v.vitalID = a.vitalID
3. RIGHT JOIN
- 오른쪽 테이블(Base)의 모든 레코드들을 리턴한다.
- 왼쪽 테이블의 필드는 오른쪽 레코드와 매칭되는 경우에만 채워진 상태로 리턴된다.
- 오른쪽 레코드들과 매칭되지 않는 왼쪽 레코드들은 NULL로 채워진다. (Python Notebook에서는 None으로 채워짐)
4. FULL OUTER JOIN
- 왼쪽 테이블과 오른쪽 테이블의 모든 레코드들을 리턴한다.
- 매칭되는 경우에만 양쪽 테이블들의 모든 필드가 채워진 상태로 리턴된다.
- 매칭되지 않는 레코드들은 NULL로 채워진다. (Python Notebook에서는 None으로 채워짐)
SELECT *
FROM raw_data.Vital v
FULL JOIN raw_data.Alert a ON v.vitalID = a.vitalID
5. CROSS JOIN (CARTESIAN JOIN)
- 왼쪽 테이블과 오른쪽 테이블의 모든 레코드들의 조합을 리턴한다.
- 조합 개수 = (왼쪽 테이블 레코드 수) x (오른쪽 테이블 레코드 수)
- 매칭되지 않는 레코드들은 NULL로 채워진다. (Python Notebook에서는 None으로 채워짐)
SELECT *
FROM raw_data.Vital v
CROSS JOIN raw_data.Alert a;
6. SELF JOIN
- 동일한 테이블을 alias(별칭)를 달리하여 자기 자신과 조인한 결과를 리턴한다.
SELECT *
FROM raw_data.Vital v1
JOIN raw_data.Vital v2 ON v1.vitalID = v2.vitalID;
JOIN 문법
SELECT A.*, B.*
FROM raw_data.table1 A
_____ JOIN raw_data.table2 B ON A.key1 = B.key1 and A.key2 = B.key2
WHERE A.ts >= '2019-01-01';
JOIN시 고려해야 할 점
- 중복 레코드가 없고 Primary Key Uniqueness가 보장됨을 먼저 체크해야 한다.
- 조인하는 테이블들 간 관계를 명확히 정의해야 한다.
- One-to-One : 조인 대상이 되는 두 테이블 간 조인 필드가 양쪽 테이블에 한번씩만 나오는 관계
- One-to-Many : 중복이 존재하면 증폭하는 문제가 발생할 수 있음
- Many-to-One : (방향만 바꾸면)중복이 존재하면 증폭하는 문제가 발생할 수 있음
- Many-to-Many : one-to-one 이나 one-to-many로 변환해서 조인하는 것이 덜 위험함
- 어떤 테이블을 FROM에 사용할지 결정해야 함(베이스가 되는 테이블 결정)
BOOLEAN 타입 처리
동일한 표현
- `flag = TRUE`
- `flag is TRUE`
다른 표현
- `flag is TRUE`
- `flag is not FALSE`
∵ 수학적으로 `TRUE`는 `not FALSE`와 같지만,
`flag`라는 필드에 `True`, `False`만 있는게 아니라 `NULL`이 존재할 수도 있기 때문이다.
SELECT
COUNT(CASE WHEN flag = True THEN 1 END) true_cnt1,
COUNT(CASE WHEN flag is True THEN 1 END) true_cnt2,
COUNT(CASE WHEN flag is not False THEN 1 END) not_false_cnt
FROM raw_data.boolean_test;→ `not_false_cnt`의 경우 `NULL`까지 포함해서 카운트하게 된다.
NULL 비교
- `NULL` 비교는 항상 `IS` 또는 `IS NOT`으로 수행한다.
- `NULL` 비교를 `=` 또는 `!=`또는 `<>`으로 수행하면 잘못된 결과가 나온다.
예제)
| flag |
| True |
| False |
| True |
| NULL |
| False |
-- 올바른 NULL 비교
SELECT COUNT(1)
FROM raw_data.boolean_test
WHERE flag is NULL;-- 잘못된 NULL 비교
SELECT COUNT(1)
FROM raw_data.boolean_test
WHERE flag = NULL;
COALESCE
: `NULL` 값 대신에 다른 백없값을 리턴해주는 함수
SELECT COALESCE(exp1, exp2, exp3, ....)
FROM 테이블명▶ exp1부터 인자를 하나씩 살펴보면서 `NULL`이 아닌 값이 나오면 그걸 리턴하는 방식
▶ 끝까지 갔는데도 모두 `NULL`이면 최종적으로 `NULL`을 리턴
예제)
SELECT
value,
COALESCE(value, 0) -- value가 NULL이면 0을 리턴
FROM raw_data.count_test;
공백 or 예약키워드를 필드명으로 사용하는 방법
→ `""`로 둘러싸서 사용
CREATE TABLE abc.test(
group int primary key, -- 에러1. group은 이미 sql내 예약키워드로 사용중
'mailing address' varchar(32) -- 에러2. 공백이 포함되면 필드명으로 사용 불가
);
사용할 때도 `""`로 둘러싸서 사용해야 함.
CREATE TABLE abc.test(
"group" int primary key, -- 에러1. group은 이미 sql내 예약키워드로 사용중
"mailing address" varchar(32) -- 에러2. 공백이 포함되면 필드명으로 사용 불가
);
과제 #1 실습하기
과제 목표 : 채널별 월 매출액 테이블 만들기 (본인 스키마 밑에 CTAS로 테이블 만들기)
필드 구성 : month, channel, uniqueUsers(총방문 사용자), paidUsers(구매 사용자: refund한 경우도 판매로 고려), conversionRate(구매사용자/총방문사용자), grossRevenue(refund 포함), netRevenue(refund 제외)
새로운 테이블
1) session_transaction : 구매 정보를 담은 테이블
- sessionid varchar(32) # 세션아이디(pk)
- refunded boolean # 환불여부
- amount int # 구매 가격
** session_transaction의 경우, 모든 sessionid가 존재하는 것은 아니다.
→ `LEFT JOIN`(혹은 `RIGHT JOIN`)을 사용해야함
→ `FROM`절에 사용하는 테이블은 `user_session_channel`혹은 `session_timestamp`가 되어야함
| 테이블명 | 필드명(타입) |
| session_timestamp | sessionid(string), ts(timestamp) |
| user_session_channel | userid(integer), sessionid(string), channel(string) |
| session_transaction | sessionid(string), refunded(boolean), amount(integer) |
| channel | channelname(string) |
DROP TABLE IF EXISTS adhoc.ybseo_session_transacition;
CREATE TABLE adhoc.ybseo_session_transaction AS
SELECT B.*, A.ts FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid;
SELECT month, channel, uniqueUsers, paidUsers, conversionRate, grossRevenue, netRevenue
FROM session_timestamp ts
INNER JOIN user_session_channel sc ON ts.sessionid = sc.sessionid
LEFT JOIN session_transaction st ON ts.sessionid = st.sessionid
GROUP BY 2, 1
ORDER BY
과제 # 1 리뷰하기
0단계. 혹시 OUT JOIN이 필요한지, 테이블 점검하기
`session_timestamp`와 `user_session_channel`의 공통된 필드인 `sessionid` 값 중에 한 쪽 테이블에만 존재하는 것들이 있는지 확인해야한다.
→ `MINUS`(혹은 `EXCEPT`) 함수 활용하기
함수 앞쪽 테이블의 레코드에서 함수 뒷쪽 테이블의 레코드를 다 빼면 매칭이 안되는 레코드만 추출된다.
SELECT DISTINCT sessionid FROM raw_data.session_timestamp
MINUS -- EXCEPT도 가능
SELECT DISTINCT sessionid FROM raw_data.user_session_channel;
SELECT DISTINCT sessionid FROM raw_data.user_session_channel
MINUS -- EXCEPT도 가능
SELECT DISTINCT sessionid FROM raw_data.session_timestamp;
1단계. 유일한 사용자 수 카운트하기
SELECT
LEFT(ts, 7) "month",
usc.channel,
COUNT(DISTINCT userid) uniqueUsers -- 유일한 사용자 수
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
2단계. `session_transaction` 테이블을 추가하기
SELECT
LEFT(ts, 7) "month",
usc.channel,
COUNT(DISTINCT userid) uniqueUsers
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
LEFT JOIN raw_data.session_transaction st ON st.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
3단계. `paidUsers`필드 추가하기
SELECT
LEFT(ts, 7) "month",
usc.channel,
COUNT(DISTINCT userid) uniqueUsers,
-- paidUsers: 물건을 구매한 적이 있는 사용자수
COUNT(DISTINCT CASE WHEN amount > 0 THEN usc.userid END) paidUsers
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
LEFT JOIN raw_data.session_transaction st ON st.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
4단계. `conversionRate` 계산하기
※ `paidUsers/uniqueUsers` 계산 과정에서 0으로 나눌 경우 divide by 0 에러가 발생한다.
→ `NULLIF`를 사용해서 0을 `NULL`로 변경해야 함 (사칙 연산에 `NULL`이 들어가면 결과도 `NULL`이기 때문)
SELECT
LEFT(ts, 7) "month",
usc.channel,
COUNT(DISTINCT userid) uniqueUsers,
-- paidUsers: 물건을 구매한 적이 있는 사용자수
COUNT(DISTINCT CASE WHEN amount > 0 THEN usc.userid END) paidUsers,
-- conversionRate: 퍼센트 값으로 나와야 함
ROUND(paidUsers::float*100/NULLIF(uniqueUSers, 0), 2) conversionRate,
SUM(amount) grossRevenue,
SUM(CASE WHEN refunded is Fale THEN amount END) netRevenue
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
LEFT JOIN raw_data.session_transaction st ON st.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
5단계. 조건을 만족하는 테이블 생성하기
-- 이미 있는 테이블이라면 삭제
DROP TABLE IF EXISTS adhoc.본인이름_monthly_channel_summary;
-- CTAS 사용해서 Summary Table 생성
CREATE TABLE adhoc.본인이름_monthly_channel_summary AS
SELECT
LEFT(ts, 7) "month",
usc.channel,
COUNT(DISTINCT userid) uniqueUsers,
-- paidUsers: 물건을 구매한 적이 있는 사용자수
COUNT(DISTINCT CASE WHEN amount > 0 THEN usc.userid END) paidUsers,
-- conversionRate: 퍼센트 값으로 나와야 함
ROUND(paidUsers::float*100/NULLIF(uniqueUSers, 0), 2) conversionRate,
SUM(amount) grossRevenue,
SUM(CASE WHEN refunded is Fale THEN amount END) netRevenue
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
LEFT JOIN raw_data.session_transaction st ON st.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
-- 정상적으로 생성되었는지 확인
SELECT * FROM adhoc.본인이름_monthly_channel_summary;
과제 #2 사용자별로 세션이 만들어진 시간순의 처음 채널과 마지막 채널 알아내기
Hint 1. ROW_NUMBER 사용하기
: SELECT된 필드에 특정 기준으로 일련번호를 추가하는 함수

SELECT ROW_NUMBER() OVER (PARTITION BY field1 ORDER BY field2) nn
-- PARTITION BY field1 : field1을 기준으로 그룹핑한 그룹내에서 일련번호를 붙일 수 있음
-- ORDER BY field2 : 일련번호를 붙이는 기준이 field2가 됨
Hint 2. FIRST_VALUE/LAST_VALUE 사용하기
과제 #3 : Gross Revenue가 가장 큰 UserID 10개 찾기
Hint1. user_session_channel sessino_transaction sessino_timestamp 테이블 사용
Hint2. Gross revenue = Refund를 포함한 매출
과제 #4 : raw_data.nps 테이블을 바탕으로 월별 NPS 계산하기
Hint1. NPS = promoter (%) - detractor(%)
- promoter(홍보자) : 9 또는 10점
- passive(소극자) : 7 또는 8점
- detractor(비추천자) : 0~6점
** NPS (Net Promoter Score): 서비스에 대해 사용자들이 어떻게 생각하는지를 의미있게 계산(0: 의향없음, 10: 의향 아주 높음)
'데이터 분석 Data Analytics > 프로그래머스 데이터분석 데브코스 2기' 카테고리의 다른 글
| [TIL] 데이터분석 데브코스 26일차 - Pandas/ (0) | 2024.03.25 |
|---|---|
| [TIL] 데이터분석 데브코스 25일차 - 트랜잭션/고급SQL문법/과제리뷰 (1) | 2024.03.23 |
| [TIL] 데이터분석 데브코스 23일차 - GROUP BY/AGGREGATE(집계) 함수/CTAS/CTE/데이터 품질 확인 방법 (0) | 2024.03.21 |
| [TIL] 데이터분석 데브코스 22일차 - AWS 콘솔을 활용한 Redshift 론치/DDL/DML/SQL실습 (0) | 2024.03.20 |
| [TIL] 데이터분석 데브코스 21일차 - 관계형 데이터베이스/SQL/데이터 웨어하우스(Data Warehouse)/클라우드(Cloud)/AWS/Redshift (0) | 2024.03.18 |