
📌 학습주제
1. 데이터 타입 변환
2. 조건절 - IF, IFNULL, CASE WHEN
3. 그 외 함수
데이터 타입 변환
- 같은 의미의 데이터라도 서로 다른 조직에서 데이터를 관리하는 경우, 데이터 타입 불일치 문제가 발생할 수 있다.
- 데이터 타입 불일치로 인한 연산/비교 오류를 피하기 위해 데이터 타입을 변환한다.
- 다양한 데이터 소스 간의 호환성을 유지하기 위해 데이터 타입을 변환한다.
1) CAST() 함수
-- 문자열 -> 정수
SELECT CAST('20231014' AS SIGNED INTEGER) AS int_date
-- 정수로 변환했기 때문에 연산이 가능하다
SELECT CAST(date AS SIGNED INTEGER) + 3 AS int_date
FROM orders
2. CONVERT() 함수
-- 정수 -> 문자열
SELECT CONVERT(20231101, CHAR) AS int_date
문자열의 글자수를 지정해줄 수도 있다.
지정한 글자수보다 초과된 문자열을 변환하려고 하면 문자열이 잘리게 된다.(뒷쪽부터)
-- 정수 -> 문자열
SELECT CONVERT(20231101, CHAR(4)) AS int_date
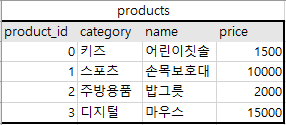
-- 정수 데이터를 문자열로 변환한 후, 'ON SALE'이라는 문자열을 추가로 이어붙인다.
SELECT CONCAT(CONVERT(price, CHAR), 'ON SALE') AS sale_price
FROM products
orders 테이블의 date는 문자열 타입이지만 orders_v2테이블의 date는 정수 타입이다.
-- orders 테이블
CREATE TABLE IF NOT EXISTS `orders` (
`odr_index` int unsigned NOT NULL,
`product_id` int unsigned NOT NULL,
`user_name` varchar(20) NOT NULL,
`date` char(8) NOT NULL,
PRIMARY KEY (`odr_index`)
) DEFAULT CHARSET=utf8;
INSERT INTO `orders` (`odr_index`, `product_id`, `user_name`, `date`) VALUES
(0, 0, '영희', '20231014'),
(1, 2, '길순', '20231014'),
(2, 3, '길동', '20231015'),
(3, 1, '길동', '20231015')
;
-- orders_v2 테이블
CREATE TABLE IF NOT EXISTS `orders_v2` (
`odr_index` int unsigned NOT NULL,
`product_id` int unsigned NOT NULL,
`user_name` varchar(20) NOT NULL,
`date` int unsigned NOT NULL,
PRIMARY KEY (`odr_index`)
) DEFAULT CHARSET=utf8;
INSERT INTO `orders_v2` (`odr_index`, `product_id`, `user_name`, `date`) VALUES
(0, 3, '철수', 20231101),
(1, 0, '민수', 20231103),
(2, 3, '갑동', 20231103),
(3, 2, '갑순', 20231104)
;
두 테이블의 특정 컬럼 데이터 타입이 다르더라도,
DB에서 자체적으로 데이터 타입 변환을 해주기 때문에 UNION 연산이 정상적으로 작동하는 것을 알 수 있다.
원칙적으로 UNION은 컬럼 개수와 타입이 모두 일치해야 작동하므로 타입이 서로 다른 것을 알고 사용하는 것이 좋다.
SELECT *
FROM orders
UNION
SELECT *
FROM orders_v2
조건문
: 조건에 따라 데이터를 처리하고 반환하기 위해 사용한다.
1. IF
: 조건에 따라 참 혹은 거짓을 만족할 때의 값을 반환하는 함수
IF(조건, 참일 때 반환 값, 거짓일 때 반환 값)

SELECT name,
IF(managing in ('스포츠', '디지털'), '3층', '2층') AS floor, -- managing 컬럼값이 '스포츠' 혹은 '디지털'이라면 '3층' 아니라면 '2층'을 반환
IF(off LIKE '%토%', '토요일 휴무', '토요일 근무') AS sat_off -- off 컬럼값에 '토'라는 글자가 포함되어있다면 '토요일 휴무' 아니라면 '토요일 근무'를 반환
FROM managers

IF문을 중첩해서 사용할 수도 있다.

-- price가 10000 초과이면 '고가', 10000 미만이면서 4000 초과이면 '중가', 4000미만이면 '저가'를 반환
SELECT product_id,
IF(price > 10000, '고가', IF(price > 4000, '중가', '저가')) AS price_class
FROM products_B
2. IFNULL
: 값이 NULL일 때 지정하는 값으로 채워서 반환하는 함수
IFNULL(컬럼명, 컬럼값이 NULL일 때 반환 값)
SELECT name, odr_index -- LEFT JOIN을 사용했기 때문에 값이 없으면 (null)로 채워짐
FROM managers m LEFT JOIN orders o ON m.name = o.user_name
GROUP BY 1
SELECT name, IFNULL(odr_index, -1) -- IFNULL 함수를 사용했기 때문에 값이 없으면 -1로 채워짐
FROM managers m LEFT JOIN orders o ON m.name = o.user_name
GROUP BY 1
SELECT user_name, price_class, count(1) AS cnt
FROM clicks c
INNER JOIN (SELECT product_id, IF(price > 5000, '고가', '저가') AS price_class FROM products) p
ON c.product_id = p.product_id
GROUP BY 1, 2
ORDER BY 1, 2
IF문 조건 범위의 구간 개수가 4개를 넘어가면 IF문 만으로 관리하기에는 지나치게 복잡해진다.
이때 사용할 수 있는 함수가 바로 CASE WHEN이다.
3. CASE WHEN()
: 조건에 따라 값을 반환하는 함수로, IF문과 비슷하지만 쿼리 작성 방식이 다르다.
IF문처럼 중첩하지 않아도 3개 이상의 조건 구간으로 분리할 수 있다.
[방법1]. 특정 조건을 기준으로 해당 그룹을 구분하고자 할 때 사용하는 방법
SELECT 컬럼명,
CASE WHEN 조건1 THEN 조건1이 참일 때 반환값
WHEN 조건2 THEN 조건2이 참일 때 반환값
...
ELSE 위의 조건들에 모두 충족되지 않았을 때 반환값
END
FROM 테이블명
[방법2]. 특정 컬럼값을 기준으로 해당 그룹을 구분하고자 할 때 사용하는 방법 (SWITCH 함수와 유사)
SELECT 컬럼명,
CASE 컬럼명
WHEN 값1 THEN 컬럼이 특정 값1일 때 반환값
WHEN 값2 THEN 컬럼이 특정 값2일 때 반환값
...
ELSE 위의 모든 값이 아닐 때 반환값
END
FROM 테이블명
[방법3]. WHERE 구문에 CASE WHEN을 사용하는 방법
: 조건이 복잡하게 걸려있는 경우, CASE WHEN에 따라 구분한 값만 서로 다르게 지정을 해주면 필터링 조건을 쉽게 바꿀 수 있다는 점에서 편리하다.
예를 들어, 아래 코드에서 마지막 = 1을 =2로 바꿀 경우
전체 조건을 변경할 필요 없이 name에 '보호대'가 포함되어있거나 category가 '디지털'인 품목만 추출할 수 있다.
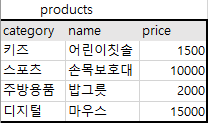
SELECT *
FROM products
WHERE (CASE WHEN category = '키즈' THEN 1
WHEN name like '%어린이%' THEN 1
WHEN name like '%보호대%' THEN 2
WHEN category = '디지털' THEN 2
ELSE 3
END
) = 1
[방법4]. ORDER BY 구문에 CASE WHEN을 사용하는 방법
: 직접 반환 순서를 정하고 싶을 때 유용하게 사용된다.
SELECT *
FROM products
ORDER BY (CASE WHEN category = '디지털' THEN 1
WHEN category = '주방용품' THEN 2
WHEN name like '%보호대%' THEN 3
ELSE 4
END
) DESC
[방법5]. CASE WHEN을 중첩하여 사용하는 방법


SELECT category, name, date, price,
CASE date WHEN '20231014' THEN -- (1) date를 기준으로 구분 (20231014일 때)
CASE WHEN price > 5000 THEN '첫째날-고가' -- (2) price를 기준으로 구분
ELSE '첫째날-저가'
END
ELSE -- (1) date를 기준으로 구분 (20231014가 아닐 때)
CASE WHEN price > 5000 THEN '둘째날-고가' -- (2) price를 기준으로 구분
ELSE '둘째날-저가'
END
END AS date_price_class
FROM clicks c INNER JOIN products p ON c.product_id = p.product_id

그 외 유용한 SQL 함수
1-1. RANK()
: 특정 컬럼을 기준으로 등수를 매기는 함수
MySQL 8버전부터 지원한다.
ex. 1번과 2번이 동점이라 할 때, 1번, 2번 = 1등, 3번 = 3등
SELECT RANK() OVER (ORDER BY 컬럼명)
1-2. DENSE_RANK()
: 동점을 랭킹했을 때 랭크 숫자를 건너뛰지 않고 빽빽하게 채워서 랭크를 하나씩 올리는 함수
ex. 1번과 2번이 동점이라 할 때, 1번, 2번 = 1등, 3번 = 2등
SELECT DENSE_RANK() OVER (ORDER BY 컬럼명)
1-3. PERCENT_RANK()
: 몇 퍼센트의 다른 값들이 지금 보고있는 값보다 작은지를 비율로 나타내는 함수
SELECT PERCENT_RANK() OVER (ORDER BY 컬럼명)
예제를 통해 살펴보자.

SELECT age,
RANK() OVER (ORDER BY age) AS asc_rank,
RANK() OVER (ORDER BY age DESC) AS desc_rank,
DENSE_RANK() OVER (ORDER BY age) AS dense_rank,
PERCENT_RANK() OVER (ORDER BY age) AS percent_rank
FROM Customers
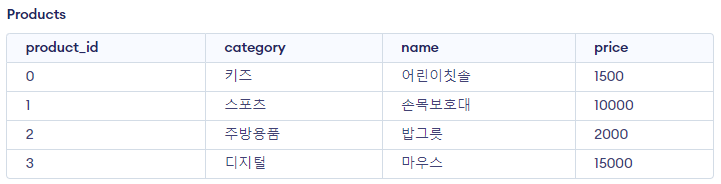
CREATE TABLE IF NOT EXISTS `products` (
`product_id` int unsigned NOT NULL,
`category` varchar(40) NOT NULL,
`name` varchar(50) NOT NULL,
`price` int unsigned NOT NULL,
PRIMARY KEY (`product_id`)
);
INSERT INTO `products` (`product_id`, `category`, `name`, `price`) VALUES
(0, '키즈', '어린이칫솔', 1500),
(1, '스포츠', '손목보호대', 10000),
(2, '주방용품', '밥그릇', 2000),
(3, '디지털', '마우스', 15000);
CREATE TABLE IF NOT EXISTS `clicks` (
`clk_index` int unsigned NOT NULL,
`product_id` int unsigned NOT NULL,
`user_name` varchar(20) NOT NULL,
`date` char(8) NOT NULL,
PRIMARY KEY (`clk_index`)
);
INSERT INTO `clicks` (`clk_index`, `product_id`, `user_name`, `date`) VALUES
(0, 0, '영희', '20231014'),
(1, 0, '철수', '20231014'),
(2, 0, '영희', '20231014'),
(3, 0, '길순', '20231014'),
(4, 1, '철수', '20231014'),
(5, 1, '길동', '20231014'),
(6, 2, '길순', '20231014'),
(7, 3, '영희', '20231014'),
(8, 3, '갑순', '20231014'),
(9, 3, '둘리', '20231014'),
(10, 0, '영희', '20231015'),
(11, 0, '철수', '20231015'),
(12, 1, '길동', '20231015'),
(13, 2, '민수', '20231015'),
(14, 3, '길동', '20231015'),
(15, 2, '길순', '20231015');

클릭된 상품들 중 날짜별로 해당 상품의 가격이 얼마인지 percent rank로 표시
-- date를 기준으로 파티션을 나누고 그룹 내에서 price기준으로 오름차순 정렬 후 순위를 매김
SELECT date, name, price, PERCENT_RANK() OVER (PARTITION BY date ORDER BY price) AS date_p_rank
FROM clicks c INNER JOIN products p on c.product_id = p.product_id
ORDER BY 1, 3 DESC
** PARTITIN BY
: 그룹별로 집계를 구하거나 순위를 매길 수 있다.
SELECT 집계함수() OVER (PARTITION BY 컬럼명)
FROM 테이블명
2. LEAD()
: 파티션 내에서 다음으로 오는 값을 찾는 함수
위의 테이블 예제에 이어서 실습해보자.
SELECT clk_index, user_name, date,
LEAD(clk_index, 1) OVER (PARTITION BY user_name, date ORDER BY clk_index) AS next_click
FROM clicks
ORDER BY 3, 1
3. LAG()
: 파티션 내에서 그 전에 어떤 값이 왔는지 LEAD()의 역으로 찾는 함수
위의 테이블 예제에 이어서 실습해보자.
SELECT clk_index, user_name, date,
LAG(clk_index, 1) OVER (PARTITION BY user_name, date ORDER BY clk_index) AS former_click
FROM clicks
ORDER BY 3, 1
▶ 이처럼 기준을 정해서 파티션을 나누고 순위를 매기거나 다음/이전 값을 찾는 함수들을 '윈도우 함수(Window Function)'라고 한다.