
** 본 포스팅은 연세대학교 의과대학의생명시스템정보학교실 유튜브 영상을 시청하며 학습을 목적으로 정리한 내용입니다. **
https://youtu.be/_D1YYpvfVLU?si=tETlQdvkNC25y3ju
의생명 데이터사이언스의 궁극적인 목표
의학계가 갖고있는 수많은 데이터를 만들기 위해서 주요한 노력과 자원으로부터 최대한의 가치를 끌어내고, 그 가치가 인간의 건강과 질병을 치료하는데 이용하는 것
이러한 것들을 가능케 했던 많은 노력들
- 2000년 human genom project
- 암 유전체 tcg, icg
ICT & 빅데이터와 결합된 정밀의학의 핵심
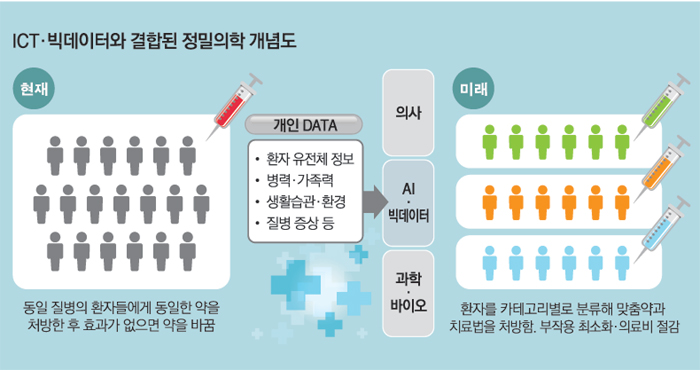
개인 데이터(화자 유전체 정보, 병력 및 가족력, 생활습관 및 환경, 질병 증상 등)를 적절히 가공하고 추출한 지식으로부터 환자를 카테고리별로 분류해 맞춤의학과 치료법을 처방하고 부작용 최소화와 의료비 절감을 가능케 하는 것.
이 과정에서 인공지능과 데이터사이언스는, 데이터로부터 지식을 추출할 수 있는 수많은 도구로서의 역할을 한다.
[참고] 정밀의학의 핵심
1. ML Classification 분류분석
: 데이터에 내제된 특정한 패턴들을 도출하고 연계해서 스스로 학습하여 새로운 unseened한 데이터가 들어왔을 때 예측을 하여 특정한 outcome category로 분류한다.
기계학습 언어에서 가장 많이 활용하는 목적(task)라 할 수 있고, 그 목적에 따라서 discrete outcome으로 분류하는 것이 바로 Classification이다.
c.f) continuous outcome으로 분류하는 것은 Regression Analysis 이다.
실제로 이러한 Classification 방법론은 의학계에서 질병을 분류할 때 많이 쓰인다. 2000년대 초반 ~ 1990년대 말에 처음으로 AML을 분류하는 방법이 Clustering & Classification 이다.
Clustering & Classification은 따로 보기도 하지만 묶어서 보는 경우가 많은데, Clustering 알고리즘의 대부분이 우리가 갖고있는 데이터의 차원을 축소할 수 있다. 축소한 input들을 다시 feature로 변환해서 다시 Classification에 사용하기도 한다. 이처럼 Clustering & Classification은 상호보완적이라 할 수 있겠다.
2. ML Clustering 군집분석
pre-defined outcome은 없다. 기계가 잘할 수 있는 데이터에 내재된 패턴만을 가지고 가장 homogenius로 나누어주고, 거리계산을 통해 나누어준 데이터는 desimilarity matrix를 활용한다.
Clustering & Classification 두 가지 기법을 활용해서 위암에서 분자아형을 biologically meaningful하고 clinically relevent한 클러스터 알고리즘의 성능 지표들을 감안해서 주어진 데이터로 가장 적절한 cluster을 찾게되고, 그러한 것들로부터 예측할 수 있는 feature을 통해 새로운 케이스를 분류하게 된다.
3. Neural Network 인공신경망 (DL Classification)
계층 Layer이 여러개 존재하는 구조.
전통적인 기계학습과 차이가 나는 점은 input variables를 다층적이고 반복적인 비선형 전환을 통해서 끊임없이 계산을 하고, 이렇게 계산된 결괏값을 다음 Layer로 넘기면서 Outcome과의 Relationship을 만들게 된다.
위의 3가지 방법론 중에서
ML Classification과 Neural Network은 pre-defined outcomes가 도출되고 Labeled input data가 필요하기 때문에 Supervised Learning(지도학습)이다.
반면, non-defined outcomes로 도출되는 ML Clustering은 Unsupervised Learning(비지도학습)이라 할 수 있다.
- Supervised Learning (지도학습)
- Unsupervised Learning(비지도학습)
데이터를 다루는 분석 알고리즘들은 하나의 ‘Tool(도구)’이라 생각하면 된다.
여기서 가장 중요한 것은 연구하는 사람 각자의 연구 영역에서 질문을 formulation화 할 수 있는 능력과 그 질문에 맞는 데이터를 수집하는 방법, 그리고 해당 데이터 분석을 통해서 데이터에 최적화된 도구(=분석 알고리즘)을 스스로 선정하는 것이다.
** 본 포스팅은 연세대학교 의과대학의생명시스템정보학교실 유튜브 영상을 시청하며 학습을 목적으로 정리한 내용입니다. **
https://youtu.be/_D1YYpvfVLU?si=tETlQdvkNC25y3ju
의생명 데이터사이언스의 궁극적인 목표
의학계가 갖고있는 수많은 데이터를 만들기 위해서 주요한 노력과 자원으로부터 최대한의 가치를 끌어내고, 그 가치가 인간의 건강과 질병을 치료하는데 이용하는 것
이러한 것들을 가능케 했던 많은 노력들
- 2000년 human genom project
- 암 유전체 tcg, icg
ICT & 빅데이터와 결합된 정밀의학의 핵심
개인 데이터(화자 유전체 정보, 병력 및 가족력, 생활습관 및 환경, 질병 증상 등)를 적절히 가공하고 추출한 지식으로부터 환자를 카테고리별로 분류해 맞춤의학과 치료법을 처방하고 부작용 최소화와 의료비 절감을 가능케 하는 것.
이 과정에서 인공지능과 데이터사이언스는, 데이터로부터 지식을 추출할 수 있는 수많은 도구로서의 역할을 한다.
[참고] 정밀의학의 핵심
1. ML Classification 분류분석
: 데이터에 내제된 특정한 패턴들을 도출하고 연계해서 스스로 학습하여 새로운 unseened한 데이터가 들어왔을 때 예측을 하여 특정한 outcome category로 분류한다.
기계학습 언어에서 가장 많이 활용하는 목적(task)라 할 수 있고, 그 목적에 따라서 discrete outcome으로 분류하는 것이 바로 Classification이다.
c.f) continuous outcome으로 분류하는 것은 Regression Analysis 이다.
실제로 이러한 Classification 방법론은 의학계에서 질병을 분류할 때 많이 쓰인다. 2000년대 초반 ~ 1990년대 말에 처음으로 AML을 분류하는 방법이 Clustering & Classification 이다.
Clustering & Classification은 따로 보기도 하지만 묶어서 보는 경우가 많은데, Clustering 알고리즘의 대부분이 우리가 갖고있는 데이터의 차원을 축소할 수 있다. 축소한 input들을 다시 feature로 변환해서 다시 Classification에 사용하기도 한다. 이처럼 Clustering & Classification은 상호보완적이라 할 수 있겠다.
2. ML Clustering 군집분석
pre-defined outcome은 없다. 기계가 잘할 수 있는 데이터에 내재된 패턴만을 가지고 가장 homogenius로 나누어주고, 거리계산을 통해 나누어준 데이터는 desimilarity matrix를 활용한다.
Clustering & Classification 두 가지 기법을 활용해서 위암에서 분자아형을 biologically meaningful하고 clinically relevent한 클러스터 알고리즘의 성능 지표들을 감안해서 주어진 데이터로 가장 적절한 cluster을 찾게되고, 그러한 것들로부터 예측할 수 있는 feature을 통해 새로운 케이스를 분류하게 된다.
3. Neural Network 인공신경망 (DL Classification)
계층 Layer이 여러개 존재하는 구조.
전통적인 기계학습과 차이가 나는 점은 input variables를 다층적이고 반복적인 비선형 전환을 통해서 끊임없이 계산을 하고, 이렇게 계산된 결괏값을 다음 Layer로 넘기면서 Outcome과의 Relationship을 만들게 된다.
위의 3가지 방법론 중에서
ML Classification과 Neural Network은 pre-defined outcomes가 도출되고 Labeled input data가 필요하기 때문에 Supervised Learning(지도학습)이다.
반면, non-defined outcomes로 도출되는 ML Clustering은 Unsupervised Learning(비지도학습)이라 할 수 있다.
- Supervised Learning (지도학습)
- Unsupervised Learning(비지도학습)
데이터를 다루는 분석 알고리즘들은 하나의 ‘Tool(도구)’이라 생각하면 된다.
여기서 가장 중요한 것은 연구하는 사람 각자의 연구 영역에서 질문을 formulation화 할 수 있는 능력과 그 질문에 맞는 데이터를 수집하는 방법, 그리고 해당 데이터 분석을 통해서 데이터에 최적화된 도구(=분석 알고리즘)을 스스로 선정하는 것이다.