
Foundation 모델
: 인공지능의 다양한 분야에 혁신을 가져온 대규모 사전 학습(Pre-Trained) 모델
- 광범위한 데이터 세트에 대해 학습됨
- Fine-tuning으로 사용자에 맞게 커스터마이징 가능
- 프로그래밍에서 라이브러리를 사용하는 것과 사용법이 유사함
Fine-Tuning
: 내가 원하는 유스케이스에 맞게 커스터마이징할 수 있는 과정
분야별 대표 Foundation 모델
1. NLP
- Transformer
- GPT
- BERT
2. CV(Computer Vision)
- ResNet, VGG, Inception과 같은 CNN 기반 모델
- ViT(Vision Transformers)와 같은 Transformer 기반 모델
3. Multi-modal
- GPT-4
4. Audio/Speech
- WaveNet
- BERT for Audio
Hugging Face
: Open Source AI 개발 사이트
Hugging Face 주요 기능
Hugging Hub
: 모델, 코드, 데이터셋 저장소
다양한 오픈 소스 기반 AI 모델링 라이브러리
- AutoTrain, Transformer, Diffuser, Accelerate, Optimum
- 사용하기 쉬움
- 직관적
머신러닝 애플리케이션 서비스
- Spaces : 사용자들이 ML 애플리케이션을 구축/공유할 수 있는 플랫폼
- 하나의 Space = 하나의 git repository
- 무료버전은 public
- Inference Endpoints : 모델 추론 서비스
오픈소스 챗폿
- HuggingChat
자체 모델
- Bloom : 오픈소스 기반의 언어 모델
- StarCoder : 코드용 대규모 언어 모델
- Idefics : 플라밍고 기반의 이미지, 텍스트 관련 모델
HuggingFace 주요 모듈
- Transformers
- 다양한 NLP 작업을 위해 설계된 광범위한 사전 학습된 모델을 제공하는 NLP 종합 라이브러리
- TensorFlow, PyTorch 등 딥러닝 프레임워크 기반 구축
- dattasets
- AutoTrain
- Diffuser
- Accelerate
- Optimum
HuggingFace LLM의 사용 모드
1. Text Generation
- LM 본연의 동작으로 주어진 문장의 다음 단어들을 입력하는 방식으로 동작
- Decoder Only : gpt2-medium
2. Text to Text Generation
- ChatGPT처럼 문장을 입력으로 주면 다음 문장을 답해주는 방식으로 동작
- Encoder-Decoder : google/flan-t5-large
HuggingFace를 활용한 텍스트 분석 실습
NLP, CV 분야 접근 방식
- Zero-shot : 예제 없이 바로 새로운 태스크 학습에 사용하는 것
- One-shot : 예제 하나를 가지고 학습하고 사용하는 것
- Few-shot : 적은 수의 예제를 가지고 (일반적으로) Final Layer만 새로 추가하는 형태로 훈련하는 것
Fine-Tuning vs. Transfer Learning
| Fine-Tuning | Transfer Learning | |
| 차이점 | - Transfer Leaning의 특정 기술 - 사전 학습된 모델을 약간 조정하는 것을 포함 |
- 하나의 모델을 활용하여 다른 작업을 시작하는 모든 시나리오 |
| 적용 방식 | - 특히 새로운 데이터 셋에 대해 사전 훈련된 모델을 계속 훈련 | - 사전 학습된 모델을 특징 추출기로 사용한 다음 해당 특징을 기반으로 새로운 분류기를 학습 |
| 훈련 깊이 | - (일반적으로) 새로운 데이터에 더 잘 맞도록 학습된 표현을 약간 조정하기 위해 더 많은 레이어를 포함시킴 | - 모델의 기본 레이어를 완전히 동결 - 네트워크의 일부만 훈련 가능 |
실습 개요
- 실습 목표 : 텍스트 감정(sentiment) Zero-shot 분류
- 사용할 모델 : facebook에서 만든 bart-large-mnli 모델 사용
- 사용할 라이브러리 : transformers
1단계. 모듈 불러오기
원래 아래의 코드를 입력하면 에러가 뜨지만, Colab에서 실습할 경우 transformers는 워낙에 유명한 모듈이기 때문에 이미 설치되어 있어 에러가 뜨지 않는다.
from transformers import pipeline
만약 다른 파이썬 노트북을 사용한다면 아래와 같이 입력해야 에러가 뜨지 않게 된다.
!pip3 install tansformers
2단계. 모델 다운로드
classifier 인스턴스를 생성해보자.
classifier = pipeline(model="facebook/bart-large-mnli")
3단계. zero-shot 분류 수행
다운로드 받은 모델을 바탕으로 별도 훈련 없이 내가 임의로 만든 레이블과 문장으로 분류 작업을 수행해보자.
classifier("one day I will see the world",
candidate_labels=['travel', 'cooking', 'dancing', 'exploration'],
multi_label=True
)
다른 예제도 살펴보자.
classifier("I have a problem with my iphone that needs to be resolved asap!",
candidate_labels=["positive", "neutral", "negative"]
)
HuggingFace를 활용한 이미지 분석 실습
실습 개요
1. 이미지 분류
- "개"와 "고양이"라는 레이블을 사용하여 이미지를 개 or 고양이로 판별하는 분류 작업
- https://huggingface.co/openai/clip-vit-base-patch32
- 이미지에 대한 설명을 텍스트로 제공 → 이를 기반으로 이미지 분류하는 zero-shot learning
2. 이미지 생성
- https://huggingface.co/stabilityai/stable-diffusion-2
- text to image 모델
1. 이미지 분류
필요한 모듈을 불러온다.
from transformers import CLIPProcessor, CLIPModel
모델과 프로세서를 각각 정의한다.
프로세서는 전처리 하는 역할, 모델은 분류/예측하는 역할이다.
# 모델과 프로세서 초기화
model_name = "openai/clip-vit-base-patch32"
model = CLIPModel.from_pretrained(model_name)
processor = CLIPProcessor.from_pretrained(model_name)
# 분류할 레이블 정의
labels = ["a dog", "a cat"]
분류에 사용할 이미지를 다운로드 받는다.
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/cat.jpeg
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/dog.jpeg
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/dogs.jpeg
from IPython.display import Image
Image('cat.jpeg')
Image('dog.jpeg')
Image('dogs.jpeg')
이미지 분류 함수를 정의해보자.
from PIL import Image
def classify(file_path):
# 이미지 로드 (예시 경로: "path/to/your/image.jpg")
image = Image.open(file_path)
# 이미지와 텍스트를 모델에 입력하기 위한 처리
inputs = processor(text=labels, images=image, return_tensors="pt", padding=True)
# 모델 예측
outputs = model(**inputs)
# 로짓스(scores)에서 softmax를 사용하여 확률 얻기
probs = outputs.logits_per_image.softmax(dim=1)
# 확률 출력
for label, prob in zip(labels, probs[0]):
print(f"{label}: {prob:.4f}")
정의된 함수를 정의해서 분류에 대한 확률을 출력한다.
classify("cat.jpeg")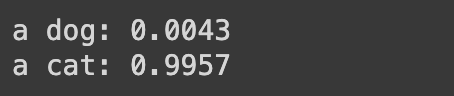
classify("dog.jpeg")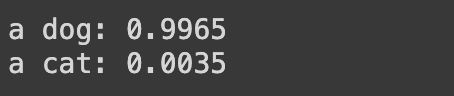
classify("dogs.jpeg")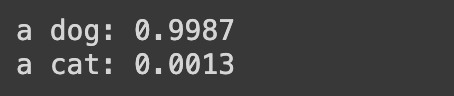
2. 이미지 생성
※ Runtime : GPU로 설정
필요한 모듈을 불러오자.
!pip install diffusers
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
# EulerDiscreteScheduler: https://huggingface.co/docs/diffusers/en/api/schedulers/euler
model_id = "stabilityai/stable-diffusion-2"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
# device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = pipe.to("cuda")
입력 프롬프트를 설정한다.
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt, num_inference_steps=100).images[0]
image
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt, num_inference_steps=200).images[0]
image
다른 입력 프롬프트를 넣어서 실습해보자.
prompt = "광화문에서 춤추는 싸이"
image = pipe(prompt).images[0]
image
prompt = "Psy dancing in Gwanghwamoon"
image = pipe(prompt).images[0]
image
HuggingFace를 활용한 LLM 실습
Bark 모델을 사용한 TTS 기능 구현