
다양한 시각화 툴
- Excel, Google Spreadsheet
- Looker (google)
- Tableau (Salesforce)
- Power BI (Microsoft)
- Apache Superset (Open source)
- Mode Analytics, ReDash
- Google Studio, AWS Quicksight
- Python
※ 셀프 서비스 대시보드를 만드는 것이 중요함
- 안그러면 매번 사람의 노동이 필요해짐
- 60~70%의 질문을 셀프 서비스 대시보드로 만들면 좋음 (Looker가 더 적합)
지표 (Metrics)
: 팀 혹은 개인별로 중요한 성과 목표를 정량적으로 정의한 것
좋은 지표의 특성 : 3A
1. Accesible
: 지표를 보는 것이 쉬워야 함 ← 시각화 툴이 도움이 됨
2. Actionable
: 지표의 의미가 분명하여 실행 가능한 통찰력이 제공되어야 함
ex. 등록 회원수 = 의미 X, 등록된 회원들 중 실제로 서비스를 이용하는 인원수 = 의미 O
3. Auditable
: 지표 계산이 제대로 되었는지 검증 가능해야 함 (= 데이터 기반이어야 함)
Next Dashboard Fallacy
: 기존 지표 기반으로 결정을 하지 못하고 대시보드만 계속해서 만드는 현상으로, 의사결정 장애의 일종
Next Feature Fallacy
: 어떤 제품이 진짜로 고객을 위한 제품인지 큰 방향성을 생각하지 않고, 현재에만 집중하여 이 제품이 고객에게 좋을 것이다라고만 생각하는 현상(=숲을 보지 못하고 나무만 보는 것)
KPI (Key PErformance Indicator)
: 조직 내에서 달성하고자 하는 중요한 목표로, 지표의 일종
- 일반적으로 정량적인 숫자 형태
- KPI의 수는 적을수록 좋음 = 대시보드의 수도 적을수록 좋음
- 잘 정의된 KPI = 현재 상황을 알고 더 나은 계획 가능
- 시간에 따른 성과 추적 가능
- OKR(Objectives and Key Results)과 같은 목표 설정 프레임워크의 핵심 포인트
허영심 지표
Tableau 제품군
- Tableau Public (무료 버전)
- Tableau Desktop (이걸 사용하려면 Tableau Server가 필요함)
- Tableau Server
- Tableau Cloud
- Tableau Mobile (Tableau로 만든 대시보드를 보기만 할 수 있음)
- Tableau Prep (데이터 전처리 툴)
- Tableau AI
- Tableau Pulse (내가 팔로잉하는 지표를 모아서 요약해줌)
헷갈리기 쉬운 용어
- Workbook : Tableau로 만든 대쉬보드 프로젝트
- Worksheet : Tableau로 만든 대쉬보드 개별 차트
- Dashboard : 개별 차트들(Worksheet)의 집합으
- Data Source : 대시보드(Worksheet)를 구성하는데 필요한 원천 데이터
- Data story : 차트나 대쉬보드를 기반으로 슬라이드를 만들어줌
Calculated Fields
- 데이터 원본의 기존 필드를 바탕으로 만드는 새로운 필드
- 수식, 함수, Z-score 계산 가능
Parameter
- 동적인 값을 가질 수 있는 변수
- Calculated Field나 필터 등에서 사용 가능
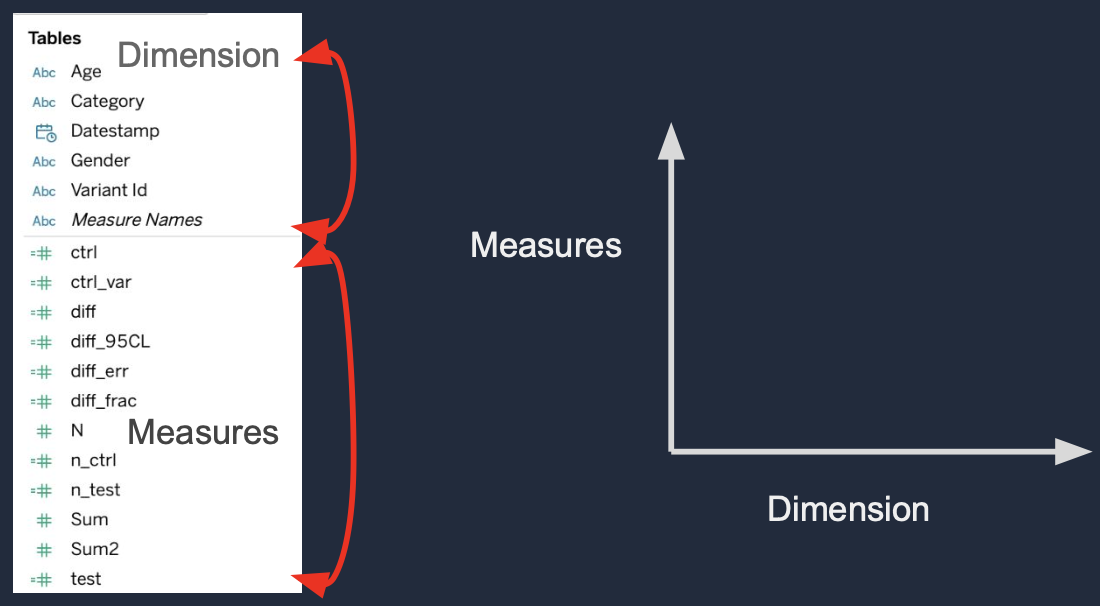
Measures
: 정량적인 숫자 혹은 값
- Metrics
- ex. Revenue, Purchase, Click, Impression 등
Dimensions
: 정성적인 데이터 (=필터)로 보통 사용자나 제품에 관한 메타 데이터를 의미
- Categorical Breakdown of Measures
- ex. Gender, Age, Datestamp, Variant, Browser Type 등
OLAP Cube
: 미리 Measures의 계산을 다 해서 대시보드 응답속도를 개선하기 위해, 미리 모든 조합에 대한 지표 데이터를 수집해둔 것
- 장점 : 속도가 빠름
- 단점 : 필터가 변경될 때마다 데이터 수집 방법을 바꿔야함 (dbt code를 변경해야 함)
실습
1. Variant, Date, Age, Gender별로 Dimension 테이블 아래 Measure을 계산한다.
- Session 수
- Impression
- Click
- Purchased
- Revenue
2. 최종 two-sample t-test를 수행하기 위해 아래 3가지를 미리 계산해둔다.
- 크기 (n)
- 합
- 제곱의 합
SELECT datestamp,
variant_id,
age,
gender,
'impression' category,
count(1) n, -- number of sessions
sum(num_of_items) sum,
sum(num_of_items*num_of_items) sum2
FROM keeyong.analytics_variant_user_daily vds
GROUP BY 1, 2, 3, 4, 5
UNION
SELECT datestamp,
variant_id,
age,
gender,
'click' category,
count(1) n, -- number of sessions
sum(num_of_clicks) sum,
sum(num_of_clicks*num_of_clicks) sum2
FROM keeyong.analytics_variant_user_daily vds
GROUP BY 1, 2, 3, 4, 5
UNION
SELECT datestamp,
variant_id,
age,
gender,
'purchase' category,
count(1) n, -- number of sessions
sum(num_of_purchases) sum,
sum(num_of_purchases*num_of_purchases) sum2
FROM keeyong.analytics_variant_user_daily vds
GROUP BY 1, 2, 3, 4
UNION
SELECT datestamp,
variant_id,
age,
gender,
'revenue' category,
count(1) n, -- number of sessions
sum(revenue) sum,
sum(revenue*revenue) sum2
FROM keeyong.analytics_variant_user_daily vds
GROUP BY 1, 2, 3, 4;
`UNION`은 중복을 제외한 합집합의 개념
(중복을 포함하려면 `UNION ALL`)
위의 SQL문을 실행시킨 후 파일 형태로 만든 것이 `session_hypercube.csv`