[BigQuery] 빅쿼리 개념/구글 클라우드 콘솔에서 빅쿼리 환경설정/빅쿼리 환경의 구성 요소(프로젝트, 데이터셋, 테이블)
본 포스팅은 인프런 [초보자를 위한 BigQuery(SQL) 입문] 강의를 수강하며 학습한 내용을 정리한 것입니다.
들어가기 전에..
자주는 아니지만, 회사에서 종종 빅쿼리를 사용하게될 것 같아서 퇴근하고 틈틈이 공부해보려고 한다.
공부도 회사 다니는 것도 전부 체력이 필수라는 것을 느끼고 있는 요즘이다.
아직 신입이기 때문에, 신입으로서 나의 목표는 '1인분 하기' 이다.
그럴려면 배우고자 하는 자세, 망설이지 말고 질문하기, 실수하는 것을 두려워 말기 인 것 같다.
원래 좌우명 같은 거 없이 살아왔는데, 취준 기간이 길어지고 최근 직장 생활을 하게 되며 하나 생겼다.
그것은 바로...
This too shall pass
이 또한 지나가리라
이 또한 지나갈 것이다! 지금 당장 힘들고 막막해도 결국엔 시간이 해결해주고, 그 시간을 견딘 나는 성장해있을 것이다..!
라는 마음가짐으로 회사를 다니고 있는 요즘이다.. ㅋㅋ 🤣
1. 빅쿼리란?
: 구글 클라우드(Google Cloud)의 데이터 웨어하우스 + OLAP
데이터의 저장 형태
- 데이터베이스(Database) : 데이터의 저장소로, 여러 테이블이 모여있음
- 테이블(Table) : 데이터가 저장된 공간으로, 행과 열(로 이루어져 있음
- 행(Row, 가로) : 하나의 row는 하나의 고유한 데이터
- 열(Column, 세로) : 하나의 column은 각 데이터의 특정 속성 값
SQL(Structured Query Language)
: 데이터베이스에서 데이터를 추출할 때 사용하는 언어
데이터베이스의 유형
1) OLTP (Online Transaction Processing)
: 거래를 목적으로 사용되는 데이터베이스
- ex. MySQL, Oracle, PostgreSQL 등
- 보류, 중간상태가 없음 ﹦주문을 완료하거나 vs. 안하거나 ﹦데이터가 무결하다
- 데이터의 추가(INSERT), 변경(UPDATE)가 자주 발생
- 분석을 위해 만든 데이터베이스가 X → 쿼리 속도 느림 (데이터 추출은 가능)
2) OLAP (Online Analytical Processing)
: 속도, 기능이 부족한 OLTP의 한계를 보완하여 분석을 위한 기능을 제공하는 데이터베이스
데이터 웨어하우스(Data Warehouse; DW)
: 데이터를 한 곳에 모아서 저장해둔 창고
2. 빅쿼리 환경설정
빅쿼리를 처음 사용하는 사람이라면 $300의 크레딧이 주어지기 때문에 90일동안 무료로 사용할 수 있다.
90일이 지나거나 $300의 크레딧을 모두 사용해도 자동 결제되지 않고, 그대로 해지된다고 한다.
우선 구글 클라우드 콘솔(Google Cloud Console)에 접속해보자.
https://console.cloud.google.com/
Google 클라우드 플랫폼
로그인 Google 클라우드 플랫폼으로 이동
accounts.google.com
필자도 이번에 강의를 통해서 빅쿼리와 구글 클라우드 콘솔을 처음 접하는 것이기 때문에, 입문자 관점에서 설명해보고자 한다.
처음 접하는 사용자라면 아래와 같은 화면을 마주할 수 있을 것이다.
'무료 체험' 혹은 '무료로 시작하기' 버튼을 클릭해보자.
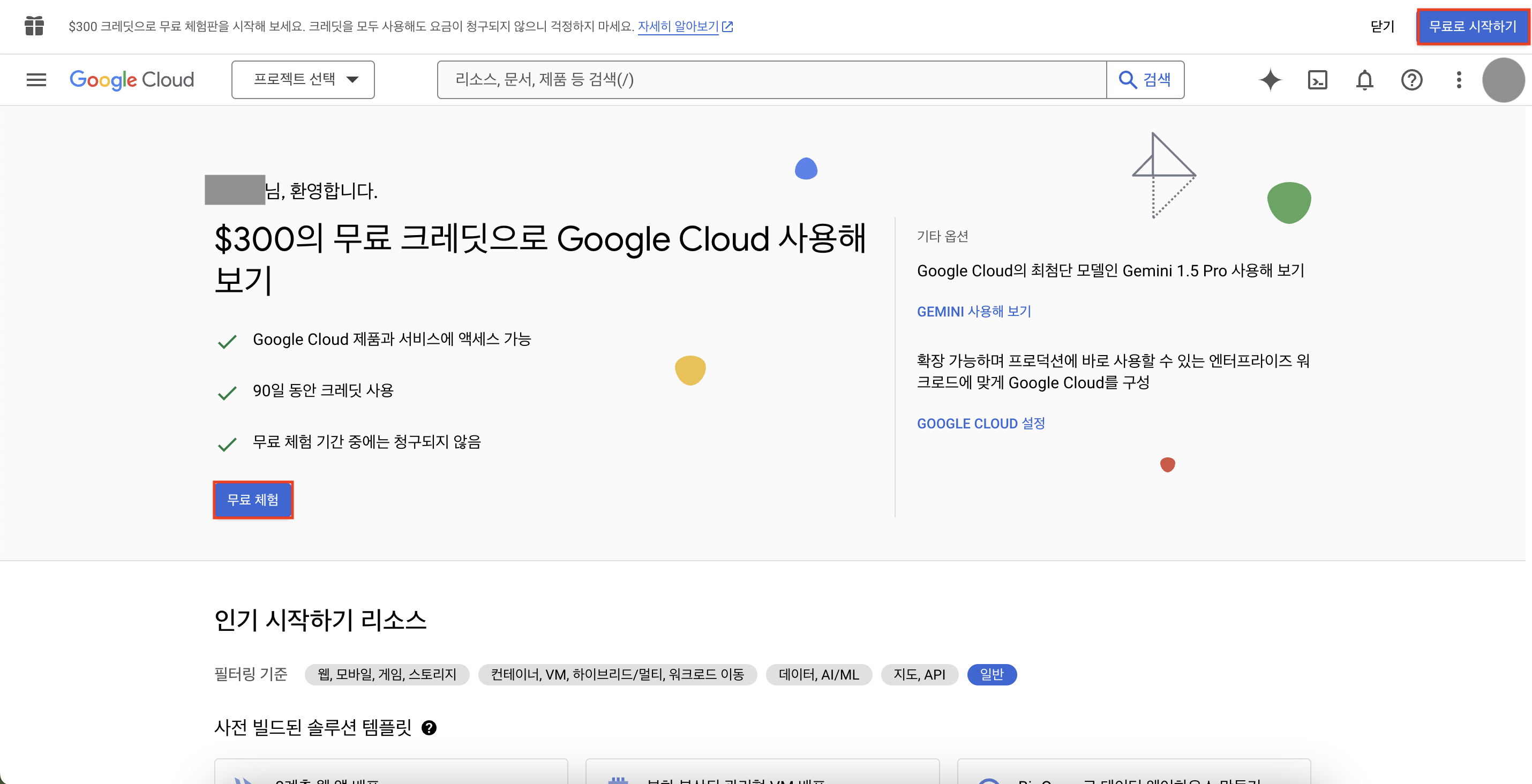
계정 정보를 입력하라는 창으로 넘어가게 될 것이다.
본인 거주 국가를 선택하고, 서비스 약관에 모두 체크한 후 '계속' 버튼을 눌러보자.
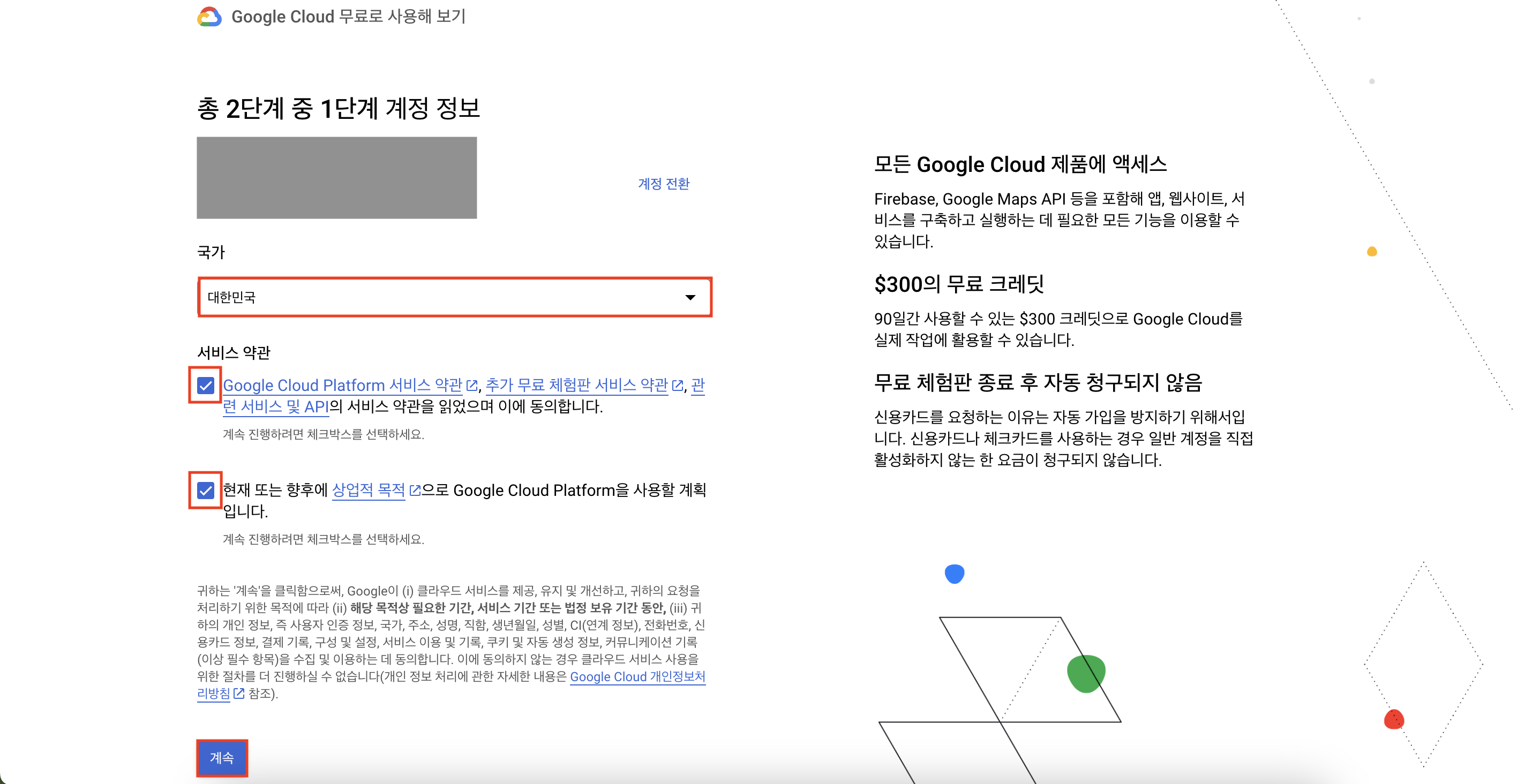
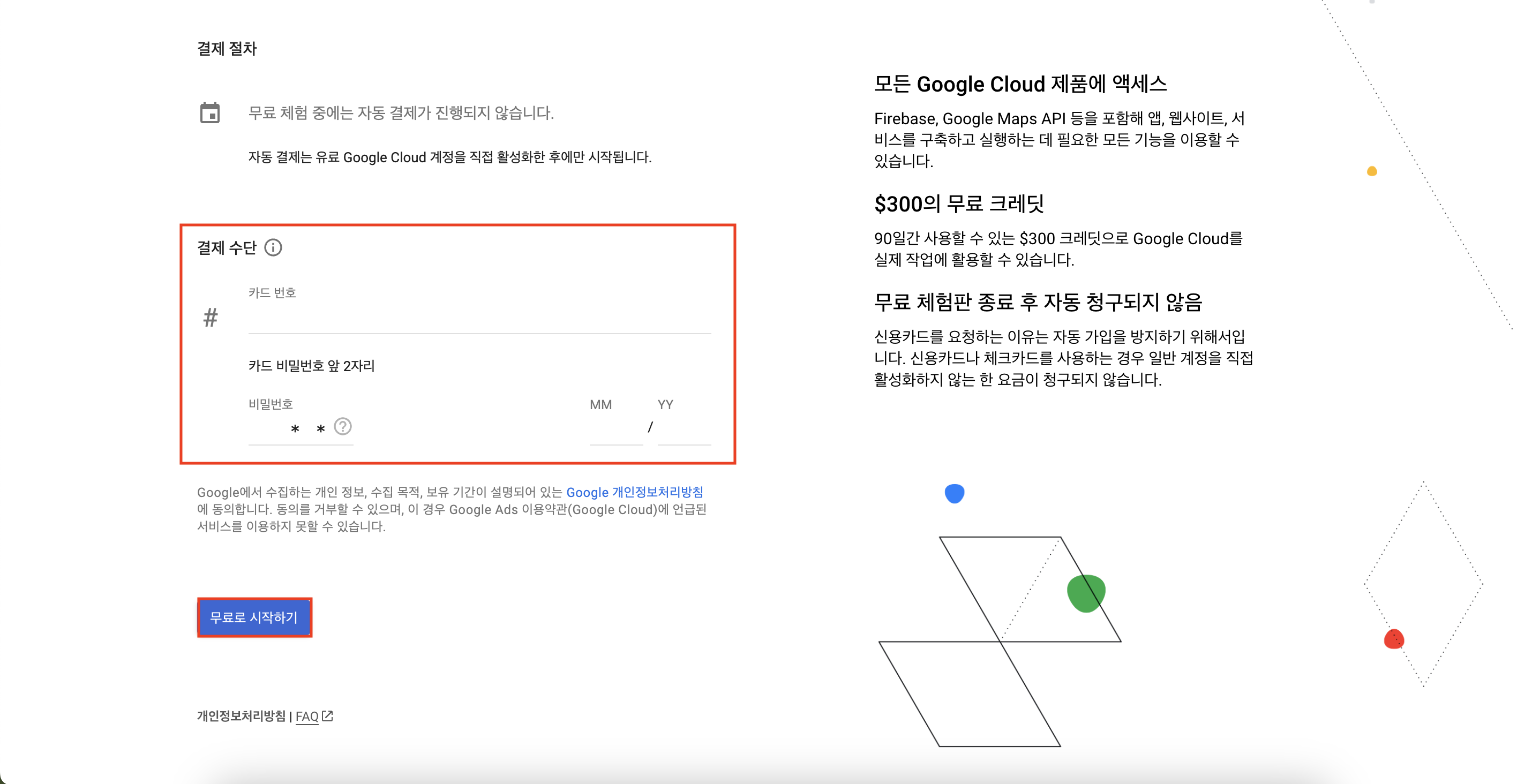
당장 결제하는 것은 아니지만, 결제 정보를 입력해야 계정을 생성할 수 있다.
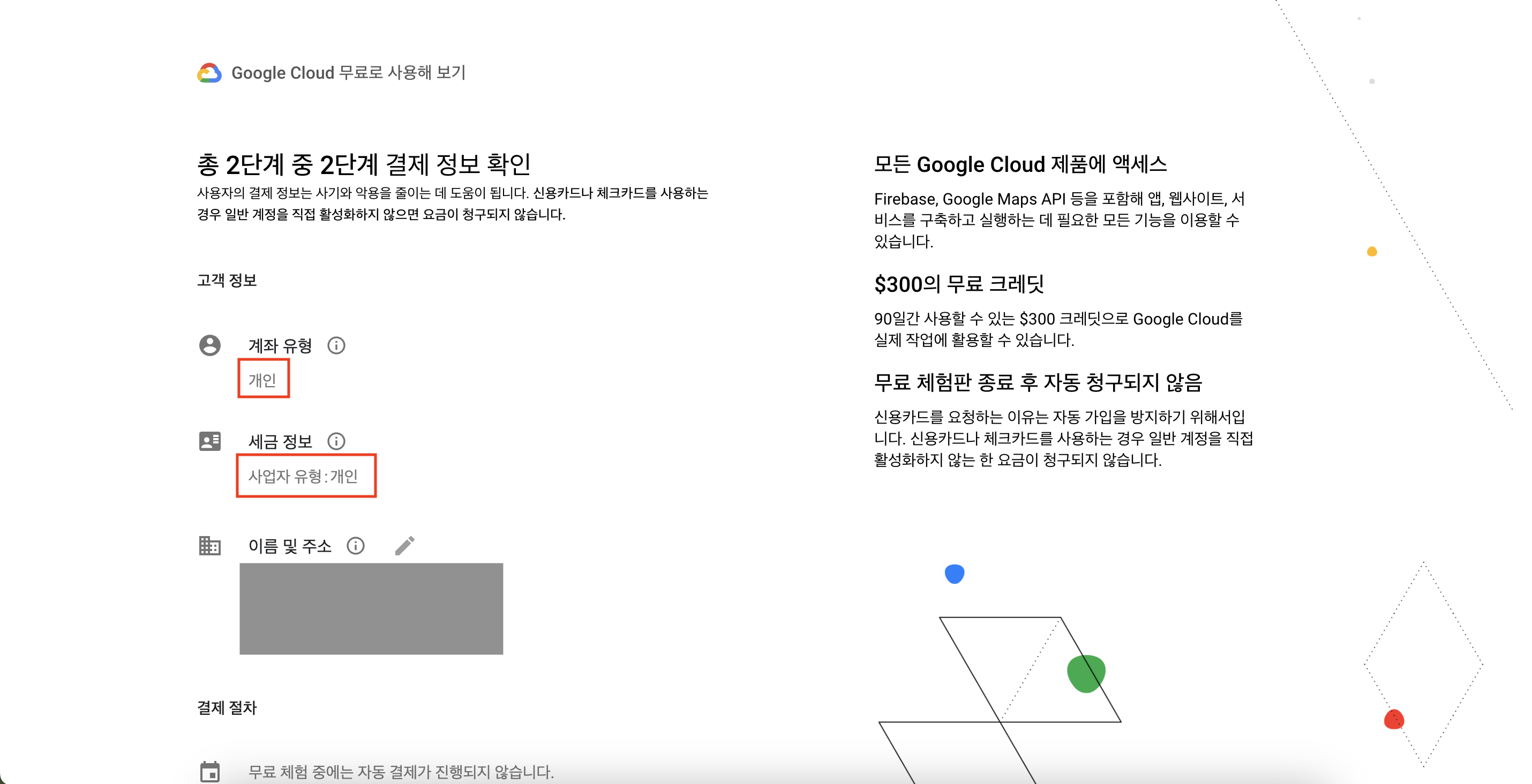
계좌 유형, 세금 정보는 모두 '개인'으로 선택하고 본인 이름과 주소를 입력한다.
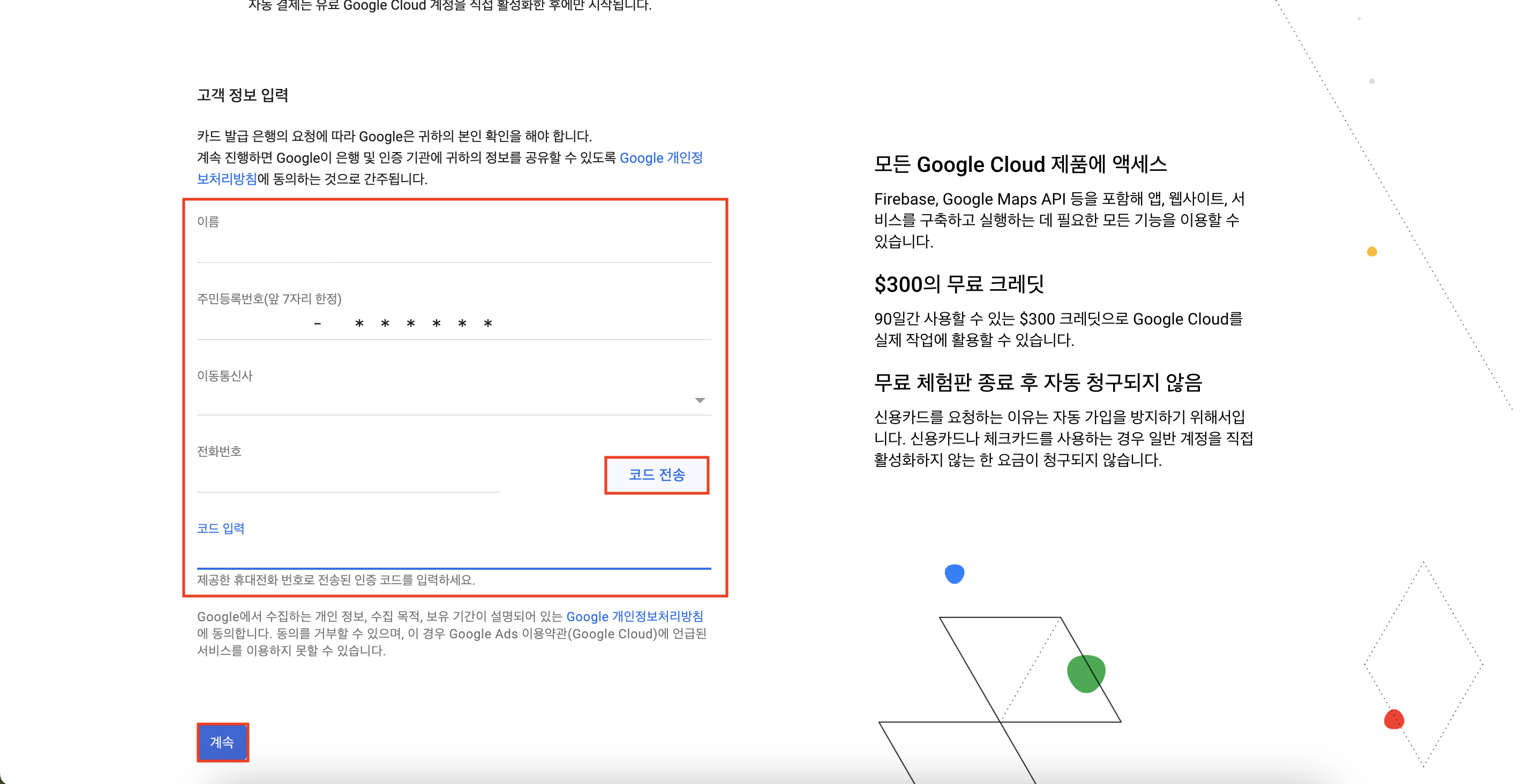
다음으로 이름, 주민등록번호, 이동통신사, 전화번호를 입력해서 전화번호 인증 코드를 입력하자.
결제 수단에 필요한 카드 번호와 비밀번호, 유효기간까지 입력한 후 '무료로 시작하기' 버튼을 클릭한다.
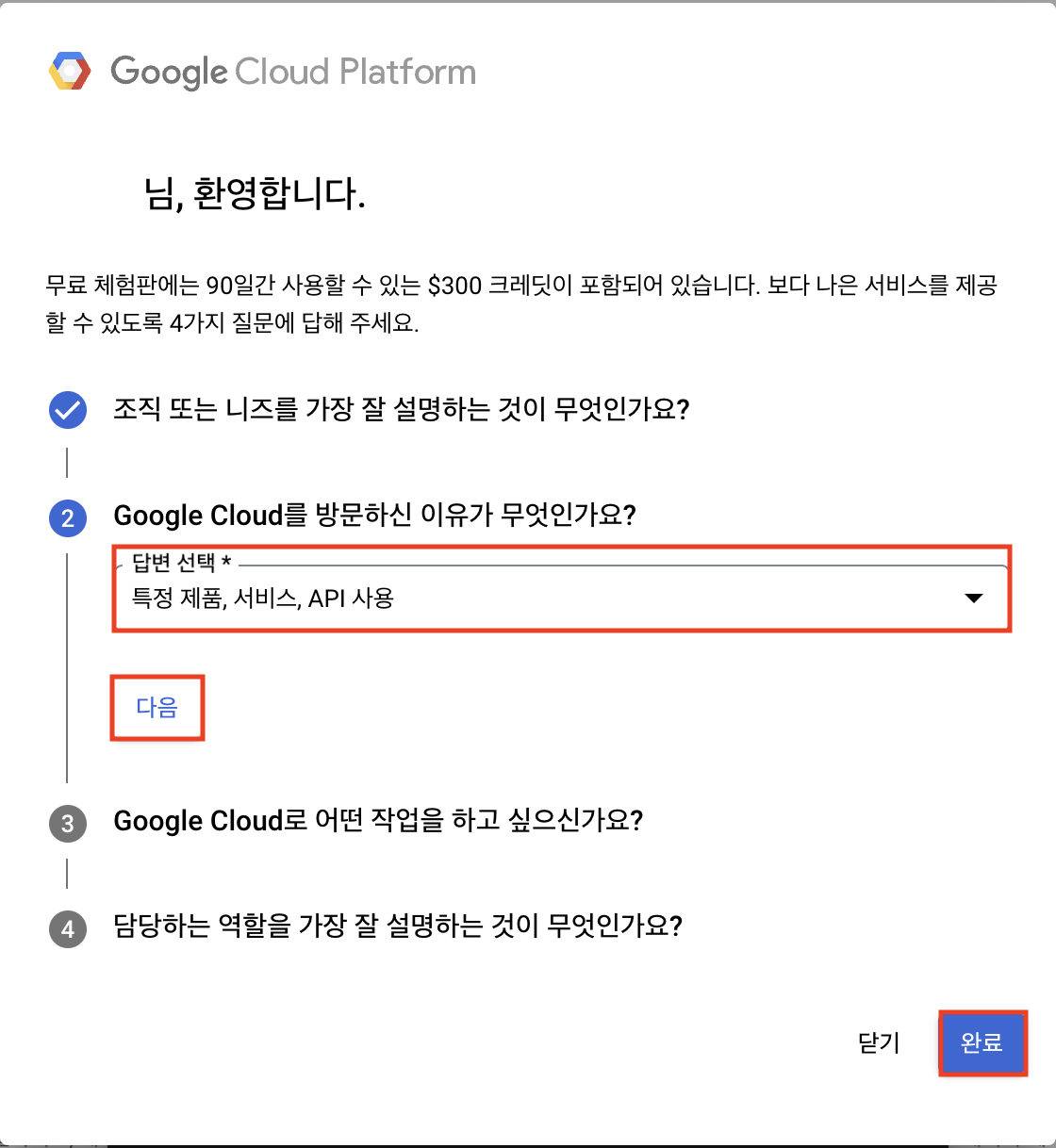
아래와 같은 4단계의 설문조사 문항에 체크하고 '완료' 버튼을 클릭한다.
이제 계정 생성이 완료되었을 것이다.
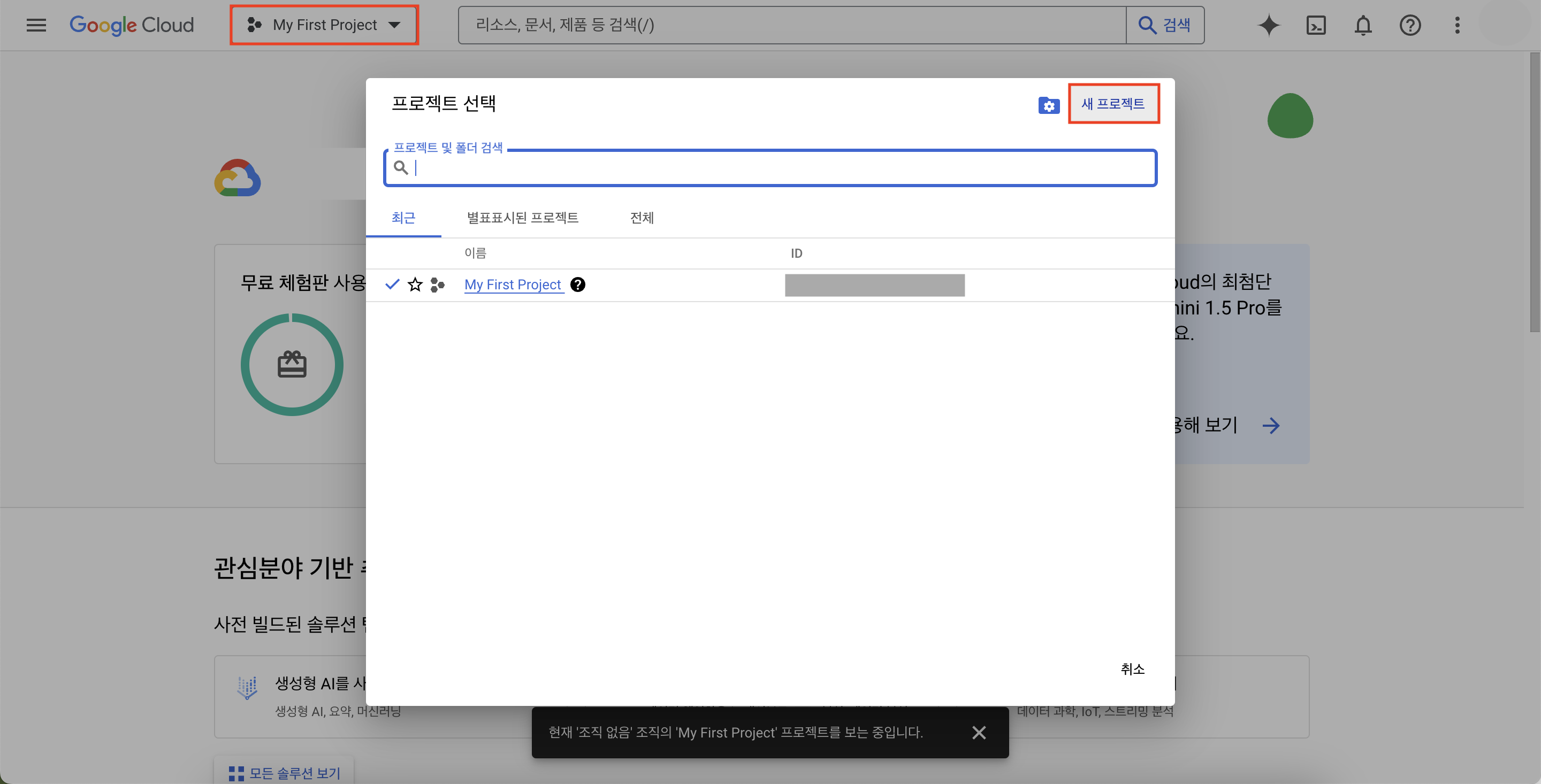
다음으로 새로운 프로젝트를 생성해보자.
계정을 생성하면 기본적으로 아래와 같이 'My First Project'라는 이름의 기본 프로젝트가 생성되어져 있는 것 같다.
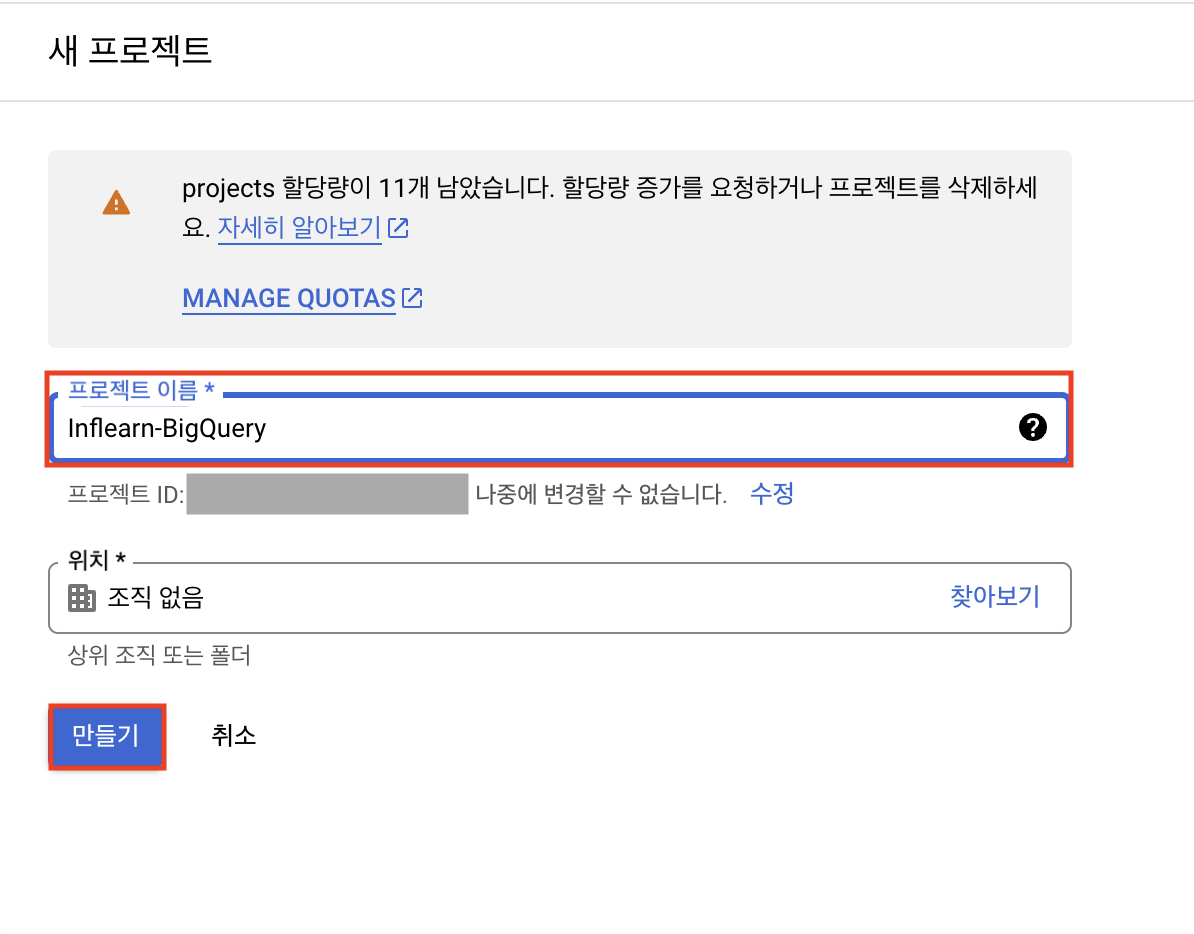
필자는 강의 내용과 최대한 똑같이 따라가기 위해서 상단에 프로젝트를 클릭하여 [새 프로젝트]로 추가로 하나 더 만들기로 했다.
만들 프로젝트의 이름을 지정하고 위치를 선택한 후 '만들기'를 클릭한다.
프로젝트가 제대로 만들어졌다면, 콘솔 홈 화면의 우측 상단에 종모양 버튼을 클릭해보자.
아래와 같이 지정해준 프로젝트 이름 옆에 초록색 체크 표시를 확인했다면 '프로젝트 선택' 버튼을 클릭한다.=
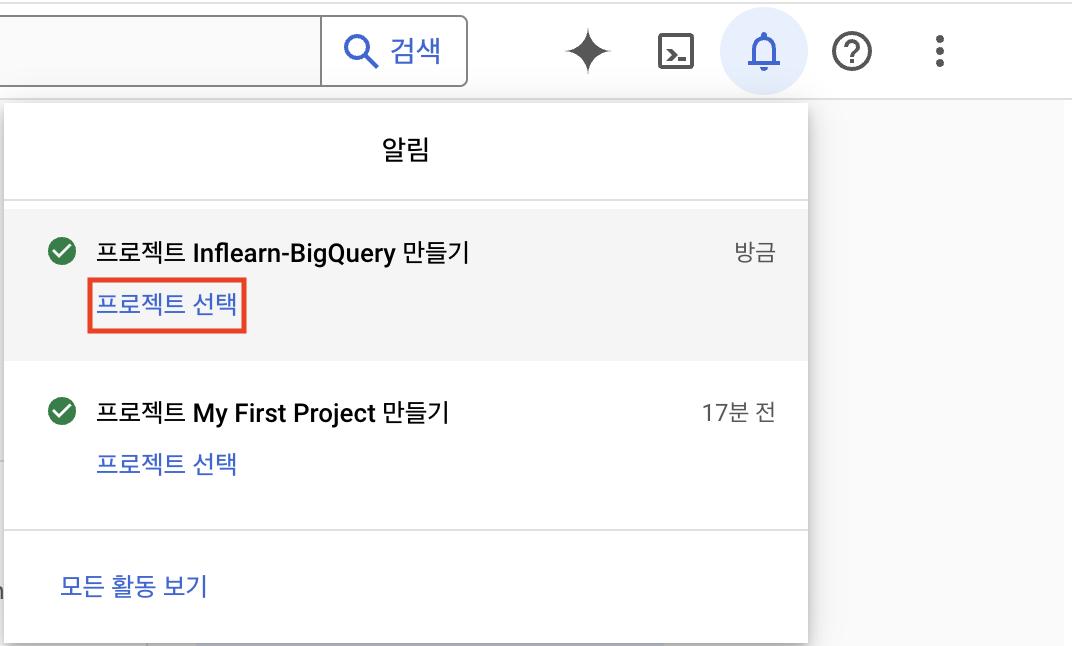
좌측 상단에 석 삼 자의 메뉴바를 클릭해보자.
구글 클라우드를 처음 사용한다면 [고정된 제품] 탭에 아무것도 없을 것이다.
하단에 [모든 제품 보기] 버튼을 클릭하고, 'BigQuery'를 찾아 빅쿼리를 메뉴바에 고정시키자.
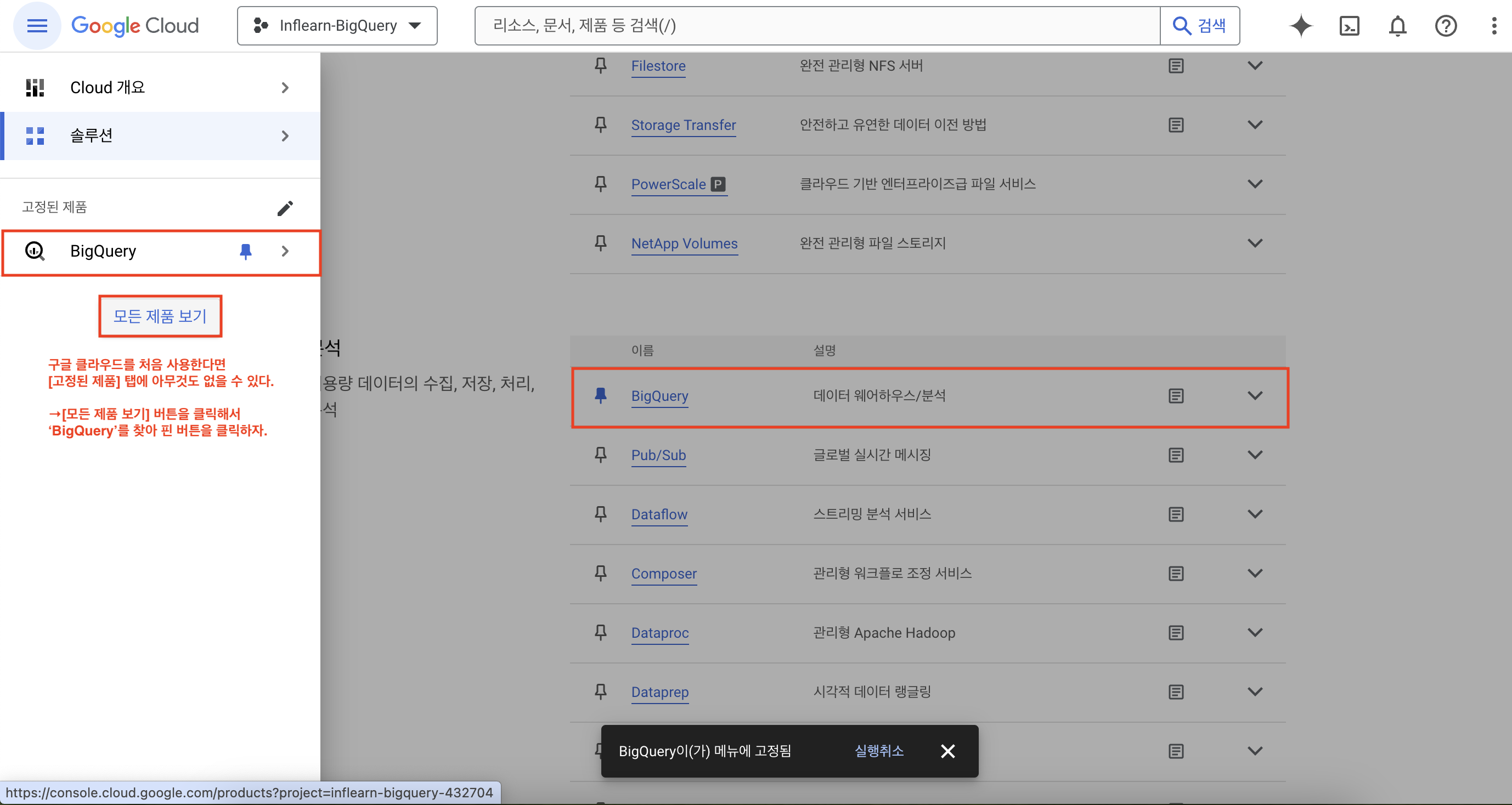
메뉴바의 'BigQuery'를 클릭해보자.
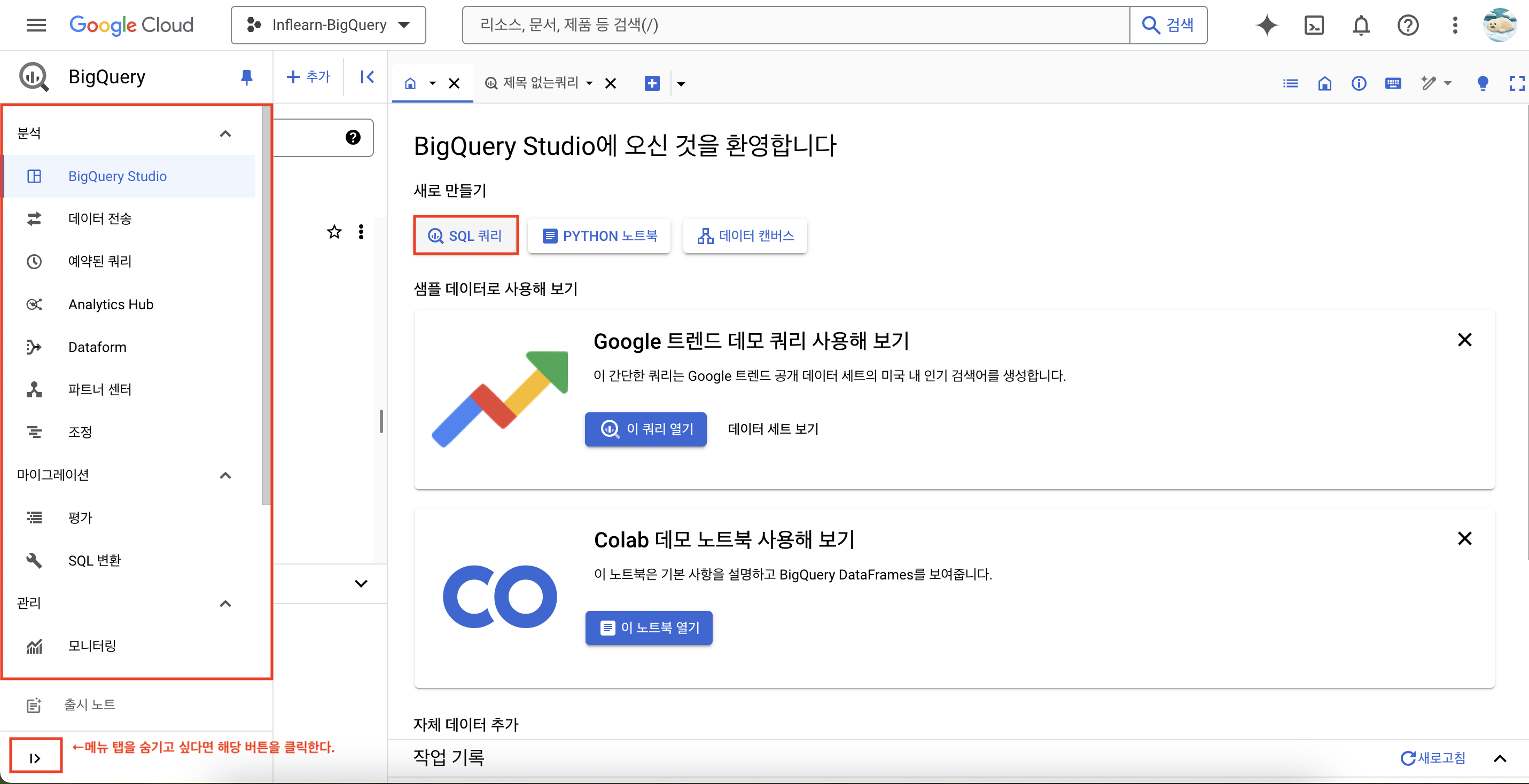
메뉴 탭에 다양한 기능을 확인할 수 있을 것이다.
메뉴 탭을 숨기고 싶다면 하단에 |> 버튼을 클릭하면 된다.
이제 [SQL 쿼리] 버튼을 눌러 간단한 쿼리를 작성할 수 있다.
3. BigQuery의 환경 구성 요소
프로젝트 > 데이터셋 > 테이블
1. 프로젝트 = 하나의 큰 건물
- 하나의 프로젝트에 여러 데이터셋이 존재할 수 있음
(하나의 큰 건물 안에 여러 목적을 가진 창고가 존재하듯이) - 회사마다 다르지만 보통 1~2개이고, Product(PRD; 실제 서비스용)와 Develop(Dev; 개발용)로 나뉘어짐
2. 데이터셋 = 건물안에 있는 창고
- 판매 데이터, 고객 데이터 등 별도의 데이터를 저장할 수 있음
3. 테이블 = 창고에 있는 선반
- 테이블 안에는 상품의 세부 정보가 저장됨
- 테이블은 행과 열로 이루어진 데이터들이 저장됨
4. [실습] 테이블 불러오기
현재 작업하려는 프로젝트가 최상단 토글에 위치해 있다.
우리는 아직 데이터셋이 없기 때문에 새로 데이터셋을 만들어야 한다.
프로젝트 명 우측에 더보기(점 3개) 버튼을 눌러 [데이터 세트 만들기]를 클릭해보자.

데이터세트 ID는 데이터셋 이름과 같다. 우선 basic이라고 설정해보자.

강의에서 배포한 자료를 보면 실습에 활용할 수 있는 csv파일 여러개가 주어진다.
차례로 테이블을 불러와보자.
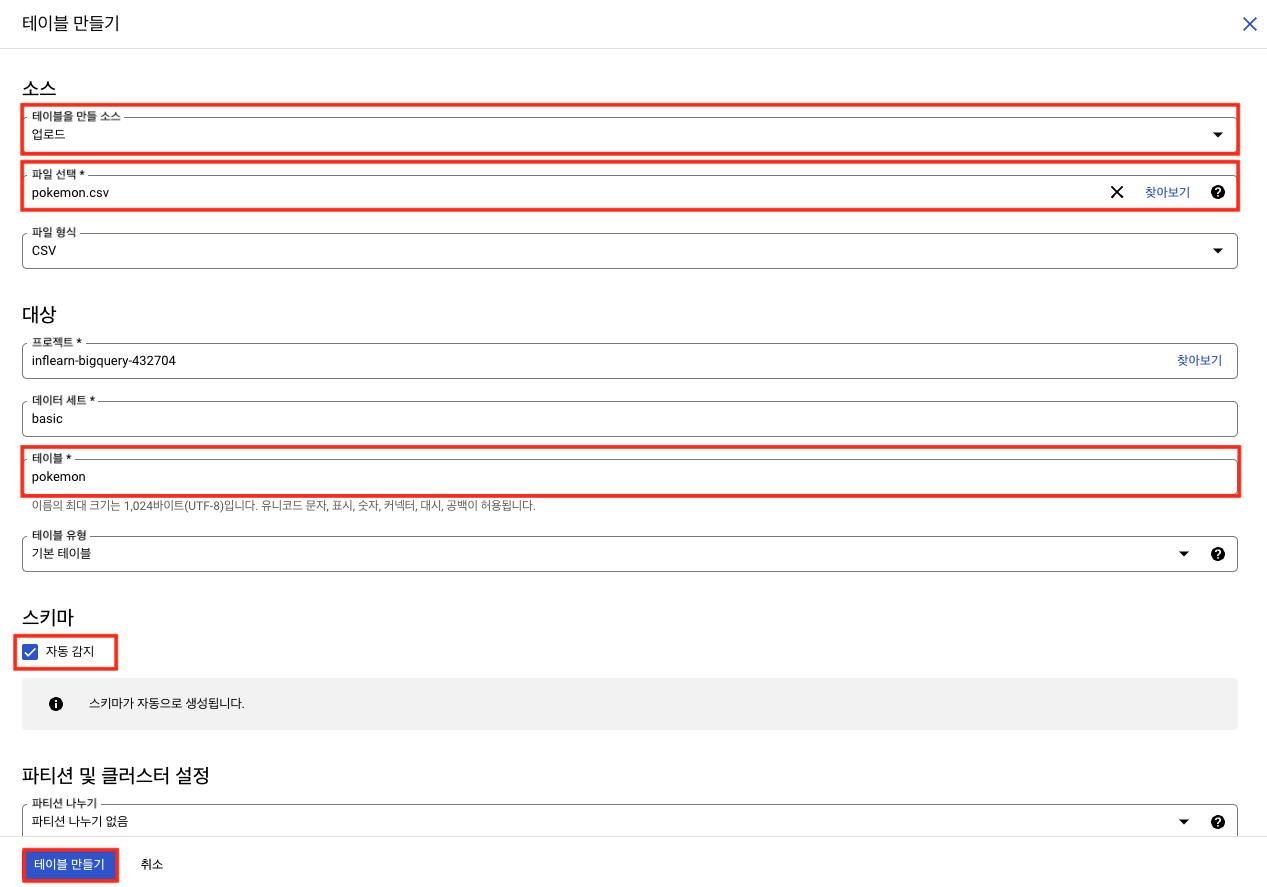
먼저 pokemon.csv 파일이다.
로컬에 있는 csv파일을 불러와 사용할 것이기 때문에 [테이블을 만들 소스]에서 '업로드'를 선택한다.
[파일 선택] 탭을 클릭하여 저장된 csv파일을 선택하자.
[테이블] 탭에는 불러온 csv파일의 테이블명을 정해야 한다. 테이블명을 입력한다.
[스키마]의 '자동 감지'에 체크해서 스키마가 자동으로 생성되게끔 하자.
완료되었다면 '테이블 만들기' 버튼을 클릭해 테이블 생성을 마무리해보자.
pokemon.csv, trainer.csv, trainer_pokemon.csv 파일은 모두 위와 같은 방법으로 테이블을 생성하면 된다.
마지막 남은 battle.csv 파일의 경우 [스키마] '자동 감지'를 체크 해제하고 [텍스트로 편집] 하여 데이터 타입을 각각 지정해줘야한다.

🤔 파티션(Partition)이란?
: [파티션 나누기 유형]에 따라 데이터를 나누는 칸막이
그리고 파티션을 설정해주어야 하는데, 예제에서는 battle_datetime(게임 일자)으로 데이터를 나누도록 한다.
[파티션 나누기 유형]은 '날짜별'로 설정한다.
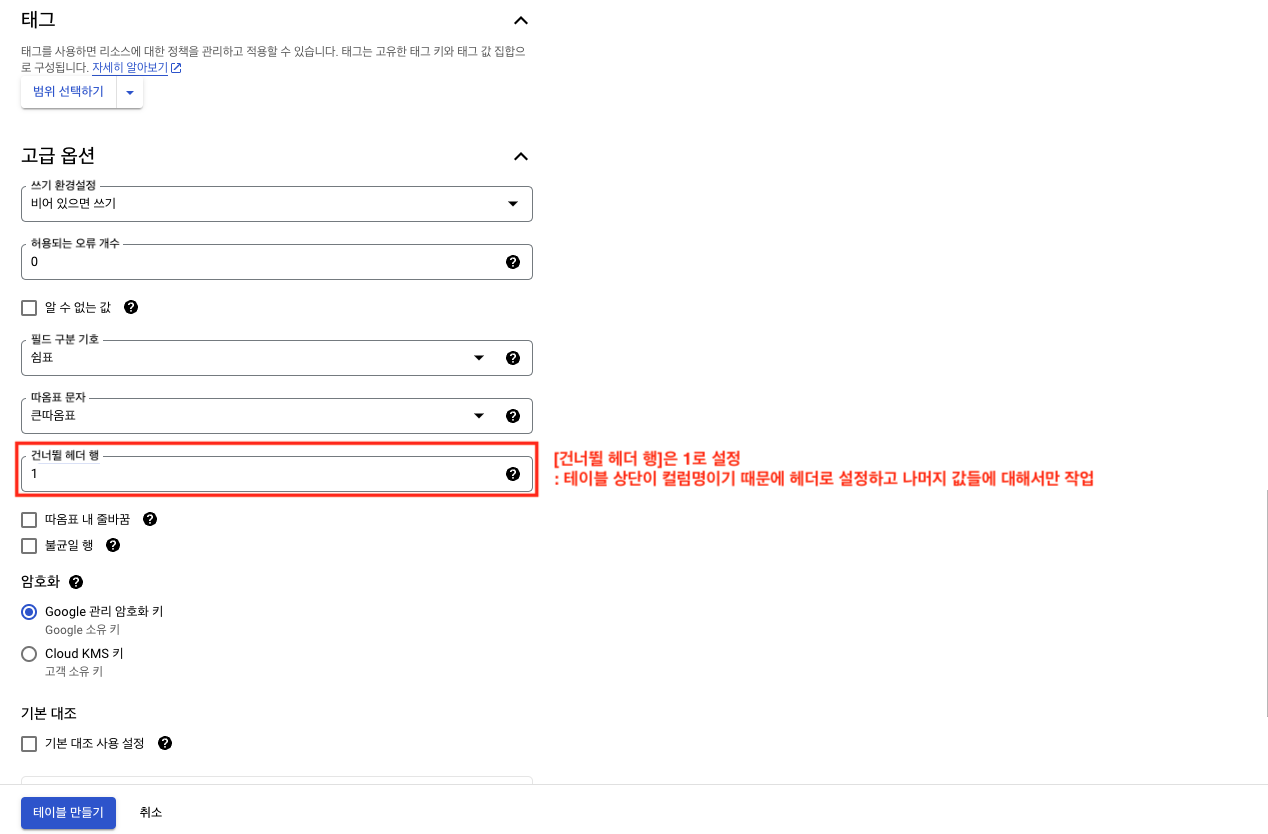
[건너뛸 헤더 행]은 1로 설정해준다. 이는 지정해준 행만큼 테이블의 헤더로 설정할 수 있는 기능이다.

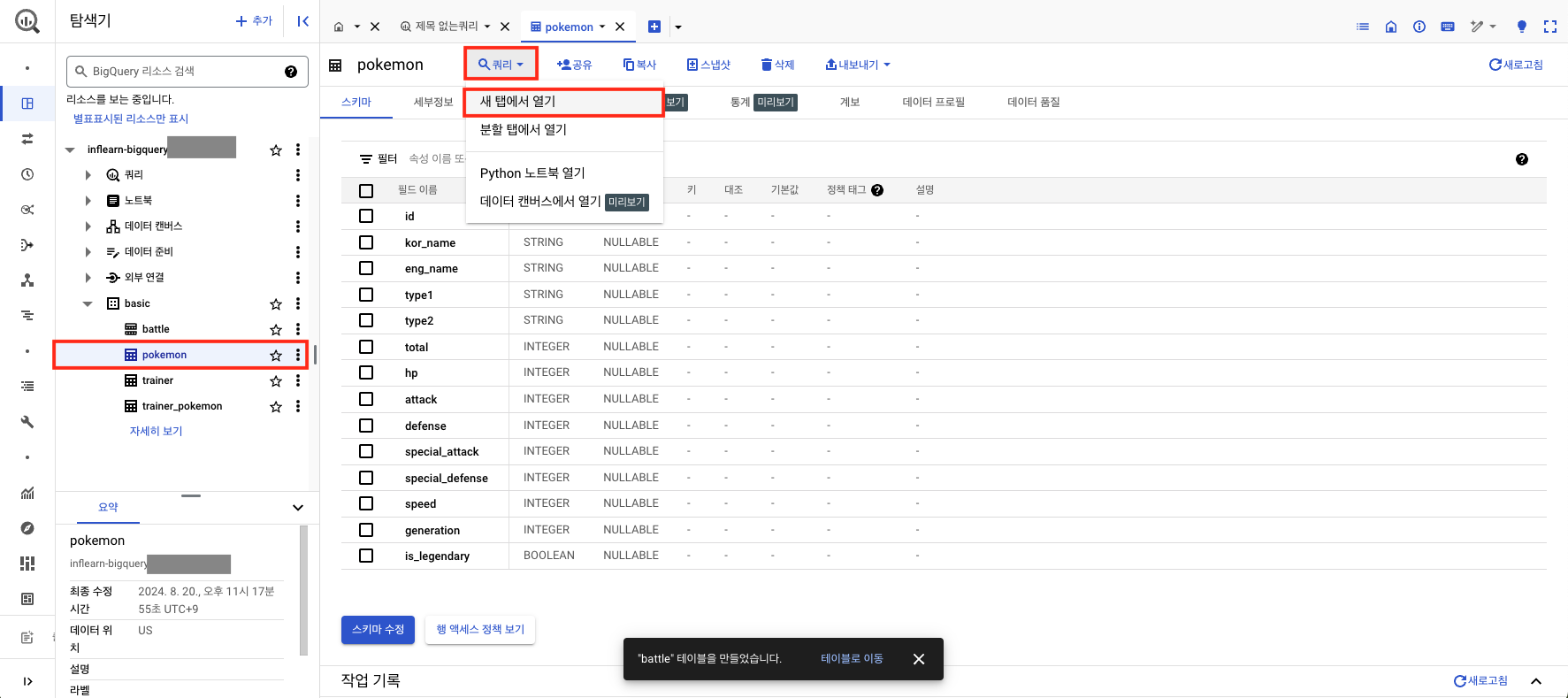
만들어둔 pokemon 테이블을 열어서 상단에 [쿼리 - 새 탭에서 열기]를 클릭하자.
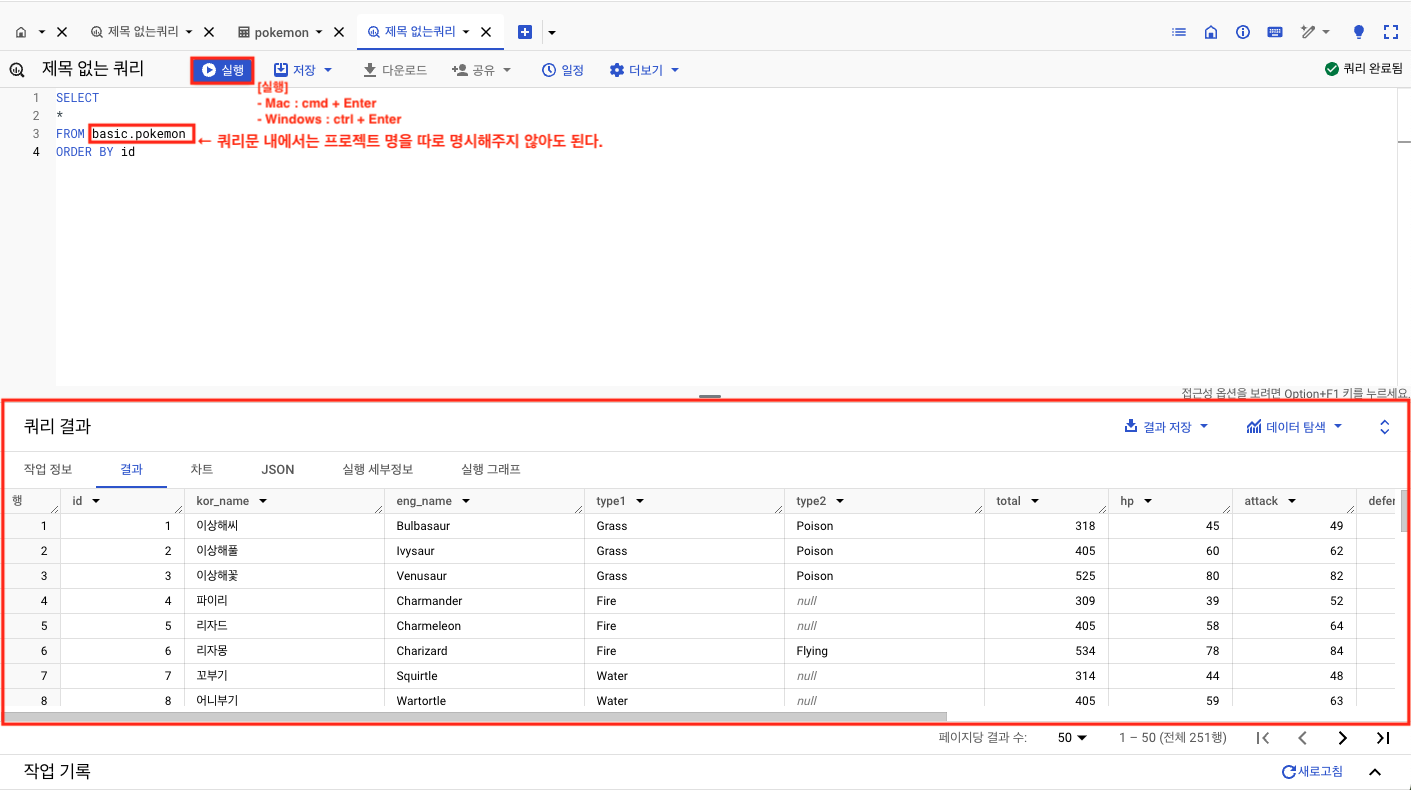
간단하게 쿼리를 작성할 수 있는데, 일반적인 SQL과 살짝 다른 점은
FROM절에서 조회할 테이블을 불러올 때 그냥 테이블명을 쓰는 것이 아니라,
FROM 프로젝트명.데이터셋명.테이블명으로 작성해야 한다는 것이다.

쿼리 안에서는 프로젝트ID를 꼭 명시하지 않아도 된다.
즉, inflearn-bigquery.basic.pokemon이 아니라 basic.pokemon으로 작성해도 무방하다는 뜻!
(프로젝트ID를 제외하고 작성할 때는 ` 기호가 없어도 괜찮음)
단, 프로젝트를 여러개 사용한다면 명시하는 것이 좋다. (쿼리를 실행할 때 어떤 프로젝트인지 확인하는 과정이 존재하기 때문이다)
쿼리를 실행하려면 아래와 같이 운영체제에 따라 단축키를 다르게 하거나, 상단의 [실행] 버튼을 클릭하면 된다.
- mac : `cmd` + `Enter`
- Windows : `ctrl` + `Enter`
이상으로 빅쿼리를 활용하여 간단하게 쿼리를 작성하고 결과를 살펴볼 수 있는 실습을 진행해보았다.