[TIL] 데이터분석 데브코스 71일차 - Gen AI/Foundation model(파운데이션 모델)/Modality/Fine-tuning(파인 튜닝)/LLM/ChatGPT/Prompt(프롬프트)/AI 발전 동향/
AGI vs. AI vs. ML vs. DL
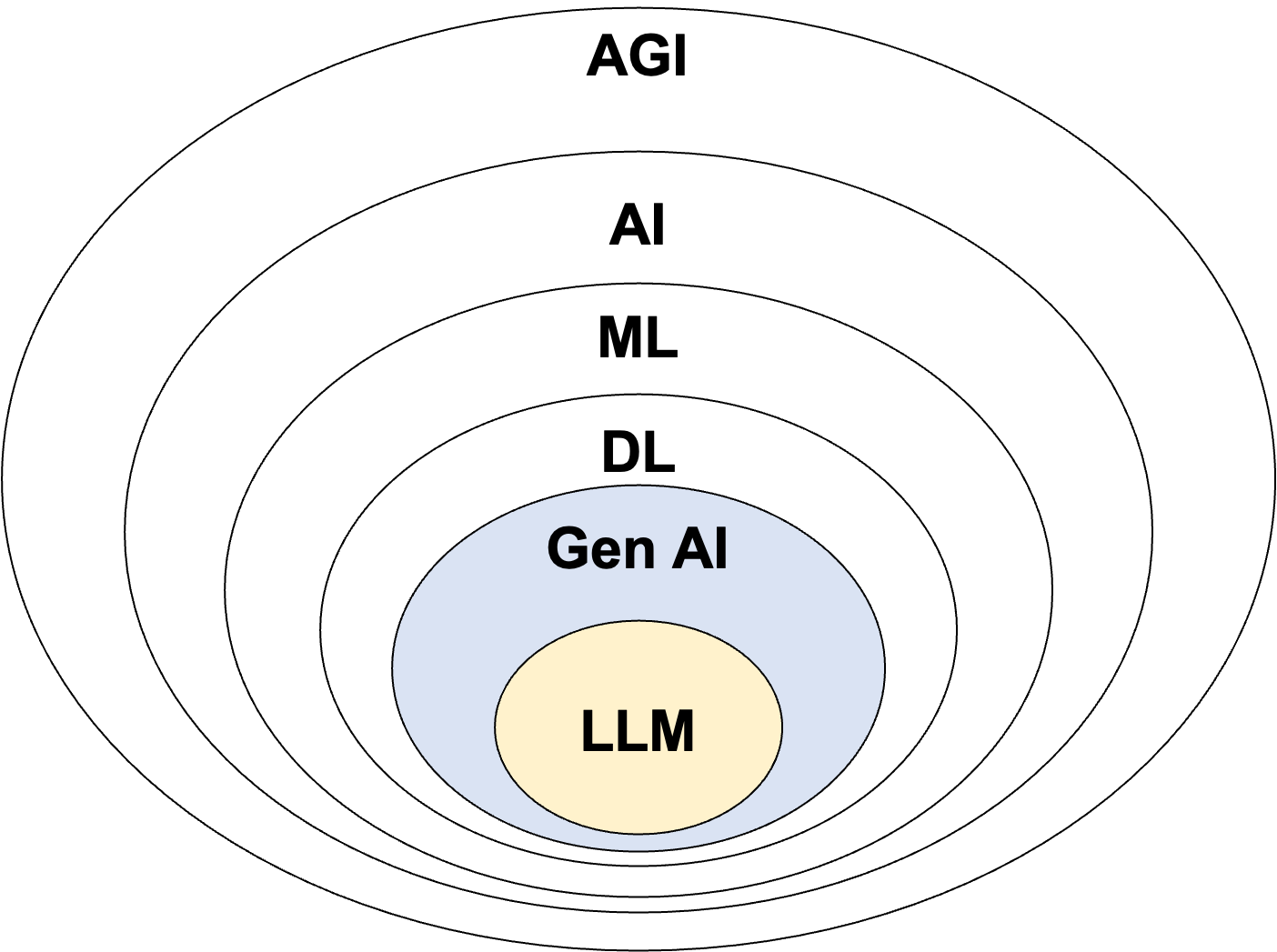
AGI(Artificial General Intelligence)
: 스스로 학습할 수 있는 것
인공지능 (Artificial Intelligence; AI)
: 인간이 하는 일을 자동화할 수 있는 시스템
머신러닝 (Machine Learning; ML)
: AI의 일부로서 데이터로부터 학습하는 시스템
딥러닝 (Deep Learning; DL)
: 인공신경망을 사용해서 사람의 뇌가 동작하는 것을 흉내낸 시스템. 기존 머신러닝 알고리즘이 처리하지 못하는 복잡한 패턴을 처리할 수 있음
딥러닝 모델 유형
1. Discriminative
- 분류/예측
- 레이블이 존재하는 데이터에 적용
- 지도학습
- 피처들과 레이블 간 관계를 학습
2. Generative
- 훈련 데이터에서 패턴/특성을 찾아내어 차원축소하여 모델 형태로 보존하고 있다가, 사용자 입력에 맞춰서 패턴으로 새로운 컨텐츠를 만들어내는 형태로 동작
- 비지도 학습
- qna, 이미지 생성 등에 적용 가능
Gen AI (생성형 AI, Generative AI)
: 딥러닝의 일부로, 학습된 컨텐츠를 바탕으로 새로운 컨텐츠를 만드는 딥러닝 기술
- 학습 대상 = 컨텐츠
- 프롬프트를 바탕으로 대답을 예측하던지 새로운 컨텐츠를 생성
📌 프롬프트 (Prompt)
: 언어 모델이나 모델 기반 AI 서비스, Gen AI에 입력하는 입력값으로 질문 혹은 지시가 될 수 있다.
Gen AI 모델과 일반 ML 모델 동작 방식
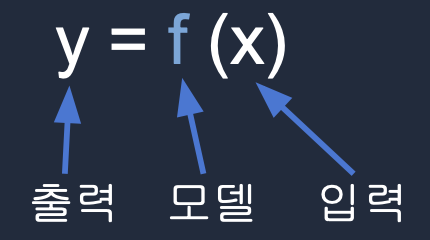
| 일반 ML | Gen AI | |
| y값 | 숫자, 카테고리, 확률 등 | 자연어 문장, 이미지, 오디오 등 |
파운데이션 모델 (Foundation Model)
: 광범위한 데이터 셋에 대해 학습된 대규모 머신러닝 모델의 한 유형
- pre-trained 모델 (일반적인 지식이 사전 학습된 모델)
- Unsupervised Learning, Self-Supervised Learning
- 대용량 데이터로 학습 → 시간, 돈, 인력 소요
- Transformer model 아키텍처 사용 ('Attention is All You Need')
- 특별한 학습 없이 다양한 작업에 적용 가능
멀티 모달 파운데이션 모델 (Multi-Modal Foundation Model)
: 다양한 타입의 데이터를 입력과 출력으로 처리할 수 있는 파운데이션 모델

📌 Modality
: 데이터 유형 (ex. 텍스트, 이미지, 오디오, 비디오 등)
📌 Multi-Modal AI
: 다양한 데이터 유형을 여러 지능 처리 알고리즘과 결합하여 더 좋은 성능을 달성하는 새로운 AI 패러다임
ex. ChatGPT-4
Supervised Fine-Tuning
: 사용자의 용도에 맞게 파운데이션 모델에 특정 지식을 학습시키는 과정
- 프로그래밍의 클래스 계승과 유사함
- 파운데이션 모델을 적절하게 파인튜닝 해서 사용자의 유스케이스에 맞게 사용가능
Gen AI 유형
1. Generative Language Models
- 훈련 데이터로 제공된 문장들로부터 언어 패턴을 학습한 모델
- (입력) 문장의 일부 → 다음 단어 예측
2. Generative Image Models
- Diffusion과 같은 기술을 사용해서 새로운 이미지를 생성하는 모델
- 프롬프트를 입력으로 받아서 이미지 생성
- (입력) 이미지 → 특정 노이즈 추가 → 이미지 변환
📌 Stable Diffusion
: Diffusion 프로세스를 사용하여 여러 Iteration을 돌면서 최종 이미지에 비슷한 형태를 생성하는 Generative AI
Gen AI의 Hallucinations(환각)
: 모델이 부정확, 무의미, 조작된 정보를 생성하는 경우, 사실 확인이 항상 필요하다
발생하는 이유
- 훈련 데이터의 불충분
- 훈련 데이터의 최신성 부족
- 훈련 데이터의 품질 이슈
- 모델에게 충분한 컨텍스트가 주어지지 않음
입력에 따른 Gen AI 모델
1. 이미지
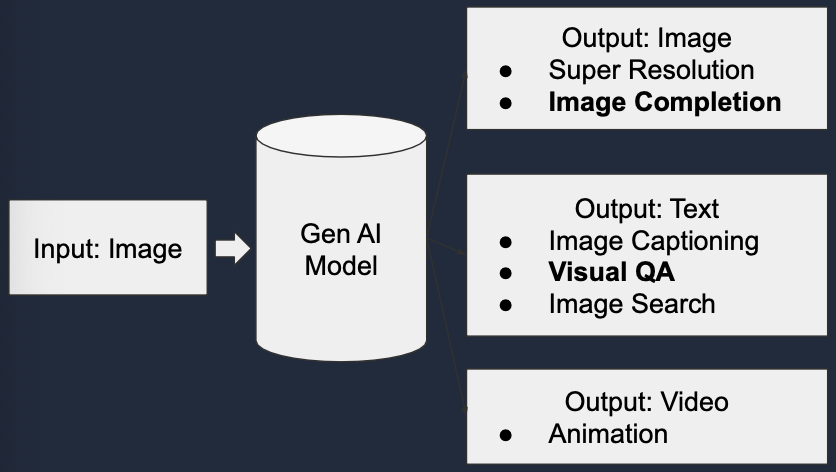
2. 텍스트
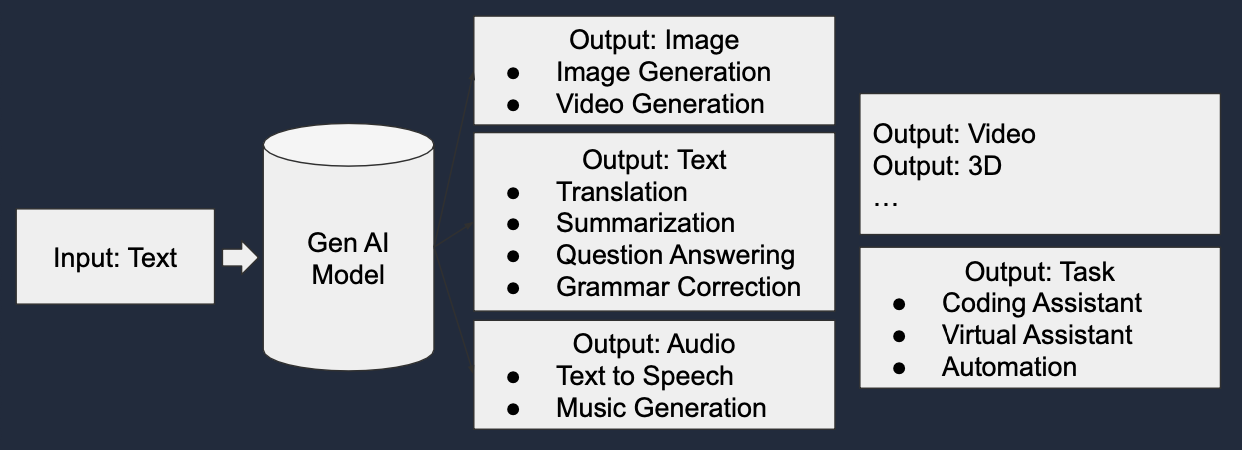
LLM (Large Language Model)
: GenAI의 일부로, 문장의 일부분을 가지고 빈 단어를 확률적으로 맞추는 모델
📌 Temperature
: 어떤 단어를 선택할 것인지에 대한 랜덤적 확률
- 0 : 정확하고 확실하게 단어 선택
- 100 : 아주 랜덤하게 임의로 단어 선택
프로세스 1. Word Embedding
: 텍스트 정보를 기계가 이해할 수 있는 수치 정보(vector)로 변환하는 과정
- 언어 모델에 사용되는 Transformer model은 수학 모델
- 데이터의 크기를 줄이고 단어 간 유사도 측정 가능
- 1) One-hot encoding : 단어를 숫자로 변환 → 공간 낭비가 심한 매우 큰 행렬이 됨
- 2) Word Embedding : 이를 다시 N차원 공간의 벡터로 변환 → 훨씬 더 밀도있는 작은 차원의 행렬이 됨
프로세스 2. Language Model 훈련
: 웹 상에 존재하는 자연어로 구성된 문서들(wiki pedia, new article 등)을 입력으로 받아서 정답을 만들도록 훈련하는 과정
- context window 크기가 모델의 메모리를 결정함
<예시 문장>
(Open AI) (transitioned) (from) (non-profit) (to) (for-profit)
↓
<만들어진 훈련데이터>
["OpenAI transitioned from", "non-profit"]
["transitioned from non-profit", "to"]
["from non-profit to", "for-profit"]
► context window = 4
: 앞의 3개 토큰을 보고 뒤의 1개 토큰을 예측
프로세스 3. Language Model 예측
: 만든 모델을 실제로 사용하는 과정
- (문제점)LLM Serving 비용은 매우 큼 → 지구 온난화의 가속화 유도
모델링 관점에서의 LLM 사용법
- 있는 그대로 사용
- 프롬프트와 함께 사용 (RAG)
- 파인 튜닝
- 처음부터 훈련
► 4단계로 갈수록 도메인 활용도가 높아지지만, 동시에 ML 스킬과 비용 및 시간이 증가한다.
데이터 관점에서의 LLM 사용법
- 언어, 이미지 데이터 ► BERT, Llama
- 도메인 데이터 ► FinBERT, BioBERT, StarCoder
- 회사 프라이빗 데이터 ► Bloomberg GPT
- 케이스 데이터 ► SafeCoder
► 4단계로 갈수록 비즈니스 가치가 높아진다.
GPT (Generative Pre-trained Transformer)
: OpenAI 기업에서 만든 초거대 언어 모델
- Word Completion : 입력이 다양한 언어로 구성된 입력으로 다음에 올 단어를 예측하는 모델
- Code Completion : 코드를 보고 다음에 올 코드를 예측하는 모델
► 사용자의 유스케이스에 적합한 가장 작은 모델을 사용하는 것이 바람직함
GPT-3 vs. GPT-4
| GPT-3 | GPT-4 | |
| 메모리 | 175B 파라미터 = 800GB | 1T 파라미터 |
| Context Window 크기 | 2048 + 1 | 8192 + 1 |
| 사용하는 워드 벡터 | 12,288개 | 32,768개 |
| 기타 | 훈련 비용 4.6$ | 멀티 모달(이미지 인식 |
GPT-4 Turbo
- Context Window 크기 : 128K(=300페이지) → 모델의 기억력, 정확도 개선
- API 기능 개선 : JSON 모드, 시드 제어, 다수 함수 동시 호출
- RAG 기능 제공 : 외부 문서, 데이터베이스 호출 가능
- 정보 업데이트 (2023.04)
ChatGPT
: GPT를 챗봇의 형태로 파인튜닝한 모델
- RLHF : Reinforcement Learning from Human Feedback(사람의 피드백을 기반으로 대화하는 AI모델)
- Prompts Engineering
- 용도 :
- 질문에 대한 답변
- 정보 추출
- 번역
- 대화 생성
- 글쓰기 지원
- 코드 생성 및 리뷰
- 프로세스 :
- 1) Collect demonstration data and train a supervised policy
- 2) 챗 지피티가 다수의 답변 중 적합한 답변을 판단하는 Reward Model을 훈련
- 3) 이렇게 만들어진 Reward Model을 강화학습의 형태로 최적화
좋은 프롬프트
- 단계별로 생각하고 알려달라고 하기
- 칭찬과 상호작용 많이 하기
- 기계 보다도 생산성 향상을 도와주는 '비서'라고 생각하기
당신의 [역할]은 ____ 이며, [해야할 일]은 ___한 [형식]과 ___의 [글의 톤]을 적용한 ____입니다.
[이러한 일]의 [목표]는 ____이며, 하면서 ____하는 [제약사항]을 지켜주세요.
프롬프트 기술
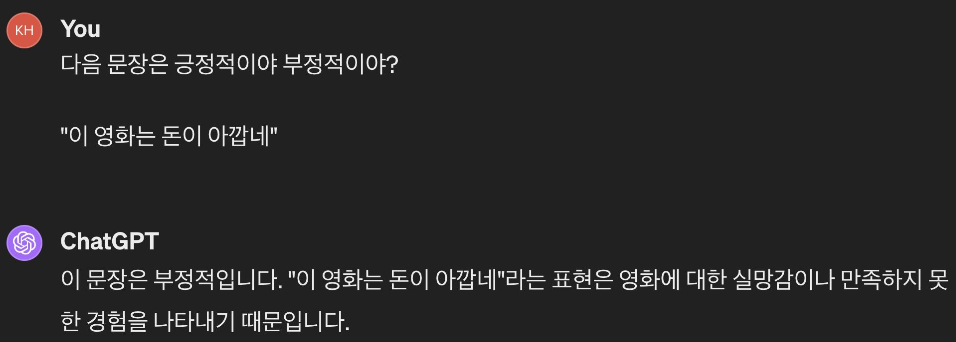
1. Zero shot prompting
: 별다른 예제, 설명없이 작업을 주는 방식
2. Few shot prompting
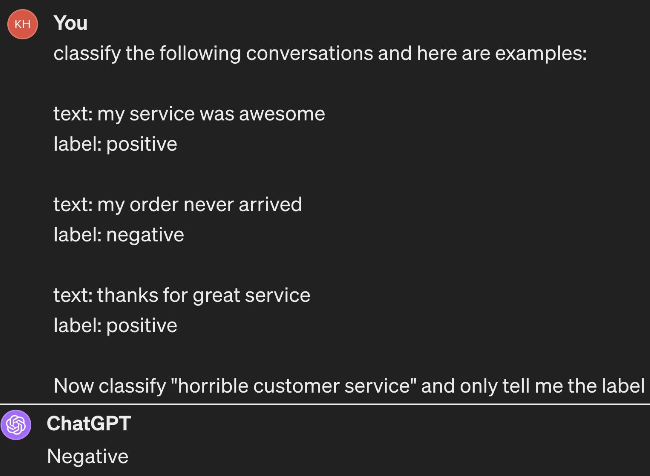
: 예제를 주면서 LLM에게 구체적으로 작업을 주는 방식
3. Chain of thoughts prompting
: 일련의 중간 추론 단계를 통해 LLM의 목잡한 추론 수행 능력을 크게 향상시키는 방식

4. Prompt chaining
: 하나의 프롬프트의 출력을 다음 프로프트로 제공하여 연속적인 답변을 만들어내는 방식
- AI와 단일 상호작용으로는 불가능한 복잡한 다단계 작업을 수행하는데 사용
- 유스케이스 :
- 순차적 정보 수집/처리
- 단계별 문제 해결
- 반복적 개선
5. Prompt extraction
: 사용자가 준 프롬프트에서 중요한 의도(ex. 제약조건, 원하는 정보)를 추출해서 챗지피티가 하는 일을 보강하는 방식
ChatGPT 4.0
: ChatGPT 유료 버전($20/월)
- Code Interpreter : 코드 작성 → 주피터 노트북에서 실행, 데이터 업로드, 데이터 분석 가능
- 인터넷을 통해 연결하고 일부 정보 검색 가능
- 멀티 모달 지원 : 이미지, 텍스트 업로드 지원
- 플러그인 지원
📌 플러그인
: 링크를 걸어서 다양한 활동을 쉽게 가능하게 하는 기능(별도 등록 필요)
GPTs (Custom GPT)
: 에이전트 기능 구현이 목적인 커스텀 챗봇
- GPT Builder : No Code 솔루션 (채팅으로 빌딩)
- Instructions, Expanded Knowledge, Actions로 구성됨
- Actions : 플러그인 기능의 상향된 버전
- Expanded Knowledge : GPT가 부가적으로 알았으면 하는 문서를 업로드
- 내 GPT를 외부에 공개하거나 개인적으로 사용 가능
- Revenue Sharing 제공
- API 제공
나만의 LLM을 만드는 방법
- 직접 만들기
- 기존 LLM을 파인 튜닝
- Pre-trained Model 위에 새로운 레이어를 얹어 다른 용도의 데이터로 훈련하는 것
- GPT는 이를 API로 지원함 - LLM을 그대로 사용하되 컨텍스트 정보를 프롬프트의 일부로 보내기(RAG)
📌 RAG (Retrieval Augmented Generation)
: 프롬프트에 사용자 질문과 관련된 도메인 정보를 같이 넘기는 방식
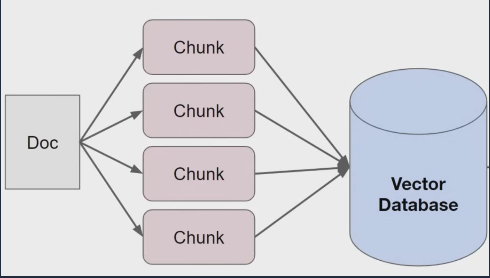
1) 인덱싱 단계
- LLM에 프롬프트의 일부로 넘길 기타 정보를 Vector DB에 저장
- 문서별로 Chunk라는 단위로 나누어 인덱싱
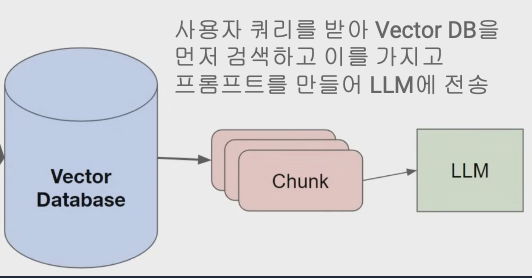
2) 검색 단계
- 사용자 질문이 들어오면 DB에서 검색하여 관련 콘텐츠 추출
- 그 콘텐츠와 질문을 조합하여 프롬프트를 생성하고 이걸로 LLM에게 질문
- 결과를 받아 후처리한 다음, 사용자에게 전송
AI발전이 IT업계에 미치는 영향
기존 개발 방식
- 요구사항 수집
- 코딩
- Build : 배포용 패키지로 만드는 것
- CI/CD pipeline
- Source Control
- 테스트
- 결과 리뷰
- (결과가 좋다면) 배포
위의 과정을 반복
AI기반 개발 방식
- 요구사항 수집 ← 사람이 함
- 위의 2~4과정을 다음이 진행 :
- CI/CD pipeline
- Source Control
- AI bot
- 결과 리뷰 ← 사람이 함
- (결과가 좋다면) 배포
개발 방식의 변화
- 현재 AI coding bot은 좋은 태도와 가능성을 가진 주니어 개발자에 가까움
- 프로그래밍 문법에 대한 명확한 이해보다 봇과의 대화 능력이 중요
- 소스 코드 에디터의 모양도 변화할 것으로 예상
- Task specification → Coding bot → 소스코드 생성
개발자 역할의 변화
- 코딩 능력보다 문제 정의, 의사소통 능력이 더 중요해질 것으로 예상
- 개인의 능력보다 그룹을 이끌고 가는 영향력
- AI를 잘 활용하는 능력이 더 중요할 것으로 예상