[TIL] 데이터분석 데브코스 54일차 - Regression (회귀 모델)/모델 종류/성능 평가 지표/Decision Tree(의사결정나무)/보스턴 주택 가격 예측 실습
Regression (회귀 모델)
: 연속적인 숫자 값을 예측하기 위해 사용되는 알고리즘
Regression 모델 종류
1. Linear Regression
- x와 y의 선형 관계로 모델링
- 직관적
- 훈련 데이터에 최적화되기 쉬움 → 정규화로 과적합 방지
- Lasso Regression, Ridge Regression: 과적합을 경감하기 위한 방법
2. Polynomial Regression
- 비선형 관계로 모델링 (Linear Regression의 또 다른 버전)
3. Decision Tree
- 과적합에 빠질 위험이 크다
- Classification에서도 사용 가능
- 최상단 노드가 가장 중요함
- 직관적
- Grid Search를 통해 트리 구성 가능
- Scikit-Learn에 두 종류의 DT :
- `DecisionTreeRegressor`
- `DecisionTreeClassifier`
4. Random Forests
- 앙상블 기법 중 하나 : 다수의 머신러닝 모델의 결괏값을 적절히 조합해서 최종 예측값으로 사용
- 다양한 형태의 DT 결괏값을 적절히 조합해서 최종 예측값에 사용
- DT의 과적합 문제를 막기 위해 다수의 DT를 사용해서 그 결과를 평균 or 다수결
- Scikit-Learn의 `RandomForestClassifier` 사용
5. Deep Learning
- Classification에도 사용 가능
Regression 성능 평가
- Mean Absolute Error (MAE) 평균 절댓값 오차
- Mean Squared Error (MSE) 평균 제곱 오차 (차이가 클수록 오차값도 늘어남)
- Root Mean Squared Error (RMSE) 평균 제곱 오차의 제곱근
보스턴 주택 가격 예측 실습 with Linear Regression
문제 정의
지역별 중간 주택 가격 예측
실습 데이터
- 총 506개 행 / 13개 피처 / 레이블 필드(주택가격)
| 필드명 | 설명 |
| CRIM | 주택이 있는 지역의 인당 범죄율 |
| ZN | 25,000 sqft(약 700평) 이상의 땅이 주거지역으로 설정된 비율 |
| INDUS | 에이커당 공업단지의 비율 |
| CHAS | 주택이 강가에 위치한 비율 |
| NOX | 산화질소 농도(=오염정도) |
| RM | 주택 당 평균 방 개수 |
| AGE | 1940년 이전에 지어진 주택의 비율 |
| DIS | 보스턴 지역 고용 센터까지의 평균 거리 |
| RAD | 고속도로 접근성에 대한 인덱스 |
| TAX | 재산세(주택가격 $10K 기준) |
| PTRATO | 초등학교 학생-선생님 비율 |
| B | 흑인 인구의 비율 |
| LSTAT | 저소득자의 인구 비율 |
| MEDV (레이블) | 주택 중간값 ($1000 단위) |
1단계. 데이터 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
boston = pd.read_csv("https://pyspark-test-sj.s3.us-west-2.amazonaws.com/BostonHousing.csv")
2단계. EDA
1) 데이터 살펴보기
# 데이터셋의 컬럼 확인
boston.keys()
boston.head()
# 데이터 크기 확인
boston.shape
2) 기본 정보 및 기술 통계 확인
boston.describe()
boston.info()
3) 상관관계 분석
boston.corr()
► 대체적으로 상관관계가 높음
# 전체 데이터셋에서 주택가격(medv)만 뽑아서 input과 label로 분리
X = boston.drop('medv', axis = 1)
Y = boston['medv']
3단계. 훈련 / 평가 데이터 분리
import sklearn.model_selection
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size = 0.33, random_state = 5)
print(X_train.shape)
print(X_test.shape)
print(Y_train.shape)
print(Y_test.shape)
※ `random_state` : 똑같은 `random_state` 값을 부여하면 어떤 상황에서든 동일한 환경이 구성된다.
4단계. Linear Regression 모델 학습 (스케일링 이전)
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(X_train, Y_train)
# 시각화
Y_pred = lm.predict(X_test)
plt.scatter(Y_test, Y_pred)
plt.xlabel("Prices")
plt.ylabel("Predicted prices")
plt.title("Prices vs Predicted prices")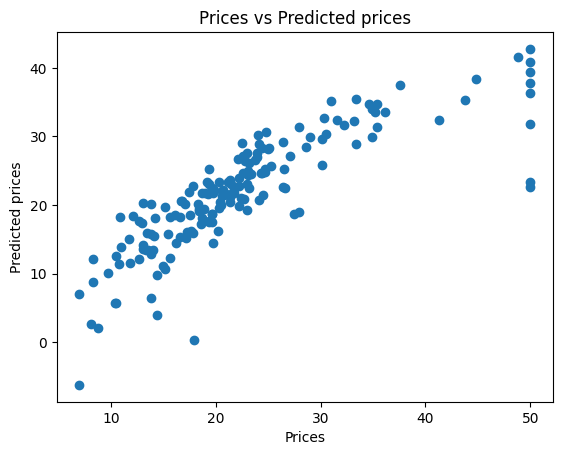
5단계. 성능 평가 (RMSE)
먼저, MSE(Mean Squared Error) 부터 구해보자
mse = sklearn.metrics.mean_squared_error(Y_test, Y_pred)
print(mse)
루트를 취해서 RMSE를 구해보자. (이 값은 작을수록 좋다.)
## RMSE
from math import sqrt
sqrt(mse)
13개 파라미터들의 가중치(회귀선의 선형 계수)를 살펴보자.
print('Coefficients: \n', lm.coef_)
회귀선의 절편을 살펴보자.
print('Coefficients: \n', lm.intercept_)
6단계. 데이터 전처리 (MinMaxScaling)
Linear Regression의 경우, 스케일링을 했느냐 / 안했느냐에 따라 큰 차이가 없는 경우가 많다.
즉, 스케일링이 모든 학습방법에서 도움이 되는 것은 아니다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_train_scaled[:5]
# 비교를 위해 스케일링 전 데이터 찍어보기
X_train[:5]
7단계. Linear Regression 모델 학습 (스케일링 이후)
lm = LinearRegression()
lm.fit(X_train_scaled, Y_train)
평가 데이터에도 훈련 데이터와 동일하게 스케일링을 진행한다.
# 평가데이터 스케일링
X_test_scaled = scaler.transform(X_test)
y_pred_scaled = lm.predict(X_test_scaled)
8단계. 성능 평가 (RMSE)
mse = sklearn.metrics.mean_squared_error(Y_test, y_pred_scaled)
print(mse)
► 스케일링 전과 동일한 MSE 값을 갖는 것을 확인할 수 있다.
즉, 해당 문제에서는 스케일링 여부가 성능 향상에 영향을 미치지 않는 것을 알 수 있다.
9단계. Ridge Regression 적용해보기
from sklearn.linear_model import Ridge
r = Ridge()
r.fit(X_train_scaled, Y_train)
y_r = r.predict(X_test_scaled)
성능 살펴보기
sklearn.metrics.mean_squared_error(Y_test, y_r)
► 위의 일반적인 Linear Regression에 비해서 성능이 나빠지는 것은 당연하다.(MSE 값이 증가함)
Ridge Regression은 과적합을 방지하기 위해, 모델 학습시 일부러 중요하지 않는 피쳐의 가중치를 없애거나 줄이는 방향으로 너무 주어진 데이터에 최적화되지 않도록 하기 때문이다.
보스턴 주택 가격 예측 실습 with Decision Tree
위의 [보스턴 주택 가격 예측 실습 with Linear Regression]에서 1 ~ 3단계는 동일하므로 4단계부터 진행하겠다.
본격적인 실습에 앞서 Decision Tree에서 반드시 필요한 개념인 Grid Search에 대해서 알아보자.
📌 Grid Search
: 주어진 모델의 하이퍼 파라미터 조합(=그리드)을 시스템적으로 탐색하여(Cross Validation 사용) 최적의 조합을 찾는 방법
► 이렇게 찾은 파라미터들은 트리를 얼마나 깊고, 세분화되어 성장할지를 결정한다.
(노드가 너무 많아도 과적합이 발생하고, 너무 적어도 성능이 저하되므로 적당한 수가 필요하다.)
parameters = {
'max_depth':(1,2,3,4,5,6,7,8,9,10),
'min_samples_split': [2, 10, 20],
'min_samples_leaf': [1, 5, 10],
'max_leaf_nodes': [5, 10, 20]
}- `max_depth` : 트리의 최대 깊이
- `min_samples_split` : 노드를 분할하기 위해 필요한 최소 샘플 수
- `min_samples_leaf` : 리프 노드가 되기 위해 필요한 최소 샘플 수
- `max_leaf_nodes` : 트리가 가질 수 있는 리프 노드의 최대 개수
4단계. Decision Tree 모델 학습
from sklearn.tree import DecisionTreeRegressor
regressor = DecisionTreeRegressor()
parameters = {
'max_depth':(1,2,3,4,5,6,7,8,9,10),
'min_samples_split': [2, 10, 20],
'min_samples_leaf': [1, 5, 10],
'max_leaf_nodes': [5, 10, 20],
}
rom sklearn.model_selection import GridSearchCV
regressors = GridSearchCV(regressor, parameters, cv=5, scoring='neg_mean_squared_error')`GridSearchCV` :
- `regressor` : 사용할 알고리즘
- `parameters` : 테스트할 하이퍼 파라미터 조합
- `cv = ` : 폴드 수
- `scoring = ` : 모델 성능 평가 지표(값이 클수록 성능이 좋아지는 지표를 선택해야 함)
regressors.fit(X_train, Y_train)
# pick the best
reg = regressors.best_estimator_ # 가장 성능이 좋은 머신러닝 모델 선택
5단계. 평가 데이터로 모델 검증
import matplotlib.pyplot as plt
Y_pred = reg.predict(X_test)# 시각화
plt.scatter(Y_test, Y_pred) # Y_test: 정답, Y_pred: 예측값
plt.xlabel("Prices: $Y_i$")
plt.ylabel("Predicted prices: $\hat{Y}_i$")
plt.title("Prices vs Predicted prices: $Y_i$ vs $\hat{Y}_i$")
plt.show()
6단계. 평가 데이터로 성능 평가
from sklearn.metrics import mean_squared_error
mse = sklearn.metrics.mean_squared_error(Y_test, Y_pred)
print(mse)
from math import sqrt
sqrt(mse)
print(Y_test[:5])
print(Y_pred[:5])
7단계. 만든 Decisioin Tree 시각화
from sklearn import tree
dotfile = open("boston_housing_dt.dot", 'w')
tree.export_graphviz(reg, out_file = dotfile, feature_names = X_train.columns)
dotfile.close()`tree. export_graphviz()`
- `reg` : 의사결정나무에 해당되는 모델
- `out_file` : 저장할 파일
- `feature_names` : 사용된 피처 이름
구글 코랩 서버의 현재 디렉토리에 아래와 같은 이름의 파일이 생성되면서, 시각화할 수 있는 정보들이 들어간다.
!cat boston_housing_dt.dot
아래의 사이트로 가서 복사한 내용을 붙여넣고 [Generate Graph!] 버튼을 클릭한다.
🔗 시각화 사이트 : http://webgraphviz.com/
Webgraphviz
WebGraphviz is Graphviz in the Browser Enter your graphviz data into the Text Area: (Your Graphviz data is private and never harvested) Sample 1 Sample 2 Sample 3 Sample 4 Sample 5 digraph G { "Welcome" -> "To" "To" -> "Web" "To" -> "GraphViz!" } Loading..
webgraphviz.com

► 알 수 있는 정보
- 루트 노드 : `rm` - 주택 당 평균 방 개수가 주택 가격에 가장 큰 영향을 미친다.
- `rm <= 6.974` : `lstat` - 저소득자의 인구 비율이 그 다음으로 큰 영향을 미친다.
- ...
- `rm > 6.974`
- ...
- `rm <= 6.974` : `lstat` - 저소득자의 인구 비율이 그 다음으로 큰 영향을 미친다.